





This is a follow up post with answer to commonly asked question during the public webinar by edureka! on ‘Limitations of Hadoop 1.0 and their solution in Hadoop 2.0’.
Frequently Asked Questions about Hadoop
Deepak:
What is Hadoop?
Apache Hadoop is an Open Source software framework for storage and large-scale processing of data-sets on a clusters of commodity hardware. It is an Open source Data Management software framework with scale-out storage and distributed processing. It is being built and used by a global community of contributors and users.
Sucheta:
What are the big data uses cases in travel, transportation and airlines industry?
Sunny:
Can you point us to some real life sample of Hadoop Implementation that we can study?
We are living in an era of increasing peak-time congestion. Transport operators are constantly seeking to find cost effective ways to deliver their services while keeping their transportation fleet in good conditions. Big Data Analytics usage in this domain can help organization with:
- Route optimization
- Geospatial analytics
- Traffic patterns and congestion
- Assets maintenance
- Revenue Management (i.e. airline)
- Inventory management
- Fuel conservation
- Targeted Marketing
- Customer loyalty
- Capacity forecasting
- Network performance and optimization
Few the Real-world Use Case are:
a) Determining Flight costs
b) Prediction Modelling for Inventory Logistics
c) Orbitz Worldwide – Customer Buying Patterns
d) Six Super-Scale Hadoop Deployments
e) Hadoop – More than Adds
f) Hadoop in Enterprise
You can learn about more about Hadoop Real-world implementations at:
- Rio Olympics 2016: Big Data powers the biggest sporting spectacle of the year!
- Big Data In Healthcare: How Hadoop Is Revolutionizing Healthcare Analytics
Hirdesh:
Is Hadoop all about Data handling and processing? How do we go for Reporting and Visual Analytics. Can Qlikview , Tableau be used on top of Hadoop?
The core Hadoop components HDFS and MapReduce are all about Data Storage and Processing. HDFS for storage and MapReduce for processing. But Hadoop core components such as Pig and Hive are used for analytics. For Visual Reports Tableau, QlikView can be connected to Hadoop for Visual Reporting.
Amit:
Hadoop Vs. mongoDB
MongoDB® is used as the “Operational” real-time data store whereas Hadoop is used for offline batch data processing and analysis.
mongoDB is a document oriented, schema-less data store which you can use in a web application as a backend instead of RDBMS like MySQL whereas Hadoop is mainly used in as scale-out storage and distributed processing for large amount of data.
Read more at our mongoDB and Hadoop blog post.
Hemendara:
Is Apache Spark a part of Hadoop?
Apache Spark is a fast and general engine for large scale data processing. Spark is faster and supports In-Memory processing. Spark execution engine broadens the type of computing workloads Hadoop can handle and can run on Hadoop 2.0 YARN cluster. It is a processing framework system that allows for storing In-Memory objects (RDD) along with an ability to process these objects using Scala closures. It is supports Graph, Data Warehouse, Machine Learning and Stream processing.
If you have a Hadoop 2 cluster, you can run Spark without any installation needed. Otherwise, Spark is easy to run standalone or on EC2 or Mesos. It can read from HDFS, HBase, Cassandra, and any Hadoop data source.
Prasad:
What is Apache Flume?
Apache Flume is a distributed, reliable, and available system for efficiently collecting, aggregating and moving large amounts of log data from many different sources to a centralized data source.
Amit:
SQL vs NO-SQL Databases
NoSQL databases are Next Generation Databases and are mostly addressing some of the points
- non-relational
- distributed
- open-source
- horizontally scalable
Often more characteristics apply such as schema-free, easy replication support, simple API, eventually consistent / BASE (not ACID), a huge amount of data and more. For example, few of the differentiator are:
- NoSQL databases scale up horizontally, adding more servers to deal with larger loads. SQL databases, on the other hand, usually scale up vertically, adding more and more resources to a single server as traffic increases.
- SQL databases required you to define your schemas before adding any information and data but NoSQL databases are schema-free do not require schema definition in advance.
- SQL databases are table based with rows and columns following RDBMS principles whereas NoSQL databases are document, key-value pairs, graph or wide-column stores.
- SQL databases uses SQL (structured query language) for defining and manipulating the data. In NoSQL database, queries vary from one database to another.
Popular SQL Databases: MySQL, Oracle, Postgres and MS-SQL
Popular NoSQL Databases: MongoDB, BigTable, Redis, RavenDb, Cassandra, HBase, Neo4j and CouchDB
Review our blogs on Hadoop and NoSQL databases and Advantages of one such database: Cassandra
Koteswararao:
Does Hadoop have an in-built Cluster Technology?
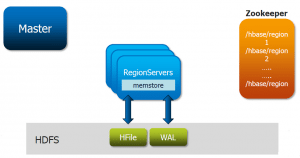
A Hadoop Cluster uses Master-Slave architecture. It consist of a Single Master (NameNode) and a Cluster of Slaves (DataNodes) to store and process data. Hadoop is designed to run on a large number of machines that do not share any memory or disks. These DataNodes are configured as Cluster using Hadoop Configuration files. Hadoop uses a concept of replication to ensure that at least one copy of data is available in the cluster all the time. Because there are multiple copy of data, data stored on a server that goes offline or dies can be automatically replicated from a known good copy.
Dinesh:
What is a Job in Hadoop? What all can be accomplished via a Job?
In Hadoop, a Job is a MapReduce program to process/analyse the data. The term MapReduce actually refers to two separate and distinct tasks that Hadoop programs perform. The first is the Map task, which takes a set of data and converts it into another set of intermediate data, where individual elements are broken down into key-value pairs. The second part of a MapReduce Job, the Reduce task, takes the output from a map as input and combines the key-value pairs into a smaller set of aggregated key-value pair. As the sequence of the name MapReduce implies, the Reduce task is always performed after the completion of Map tasks. Read more on MapReduce Job here.
Sukruth:
What is special about NameNode?
The NameNode is the heart of an HDFS file system. It keeps the metadata such as directory tree of all files in the file system and tracks where across the cluster the file data is kept. The actual data is stored on DataNodes as HDFS blocks.
Client applications talk to the NameNode whenever they wish to locate a file, or whenever they want to add/copy/move/delete a file. The NameNode responds the successful requests by returning a list of relevant DataNodes servers where the data lives. Read more on HDFS Architecture here.
Dinesh:
When was Hadoop 2.0 introduced to market?
Apache Software foundation (ASF), the open source group which manages the Hadoop Development has announced in its blog on 15th October 2013 that Hadoop 2.0 is now Generally Available (GA). This announcement means that after a long wait, Apache Hadoop 2.0 and YARN are now ready for Production deployment. More on this blog.
Dinesh:
What are the few examples of non-MapReduce Big Data application?
MapReduce is great for many applications to solve Big Data problems but not for everything; other programming models better serve requirements such as Graph processing (e.g., Google Pregel / Apache Giraph) and iterative modelling with Message Passing Interface (MPI).
Marish:
How does the data arranged and indexed in HDFS?
Data is broken into blocks of 64 MB (configurable by a parameter) and is stored in HDFS. NameNode stores storage information of these blocks as Block ID’s in its RAM (NameNode Metadata). MapReduce jobs can access these blocks using the metadata stored in NameNode RAM.
Shashwat:
Can we use both MapReduce (MRv1) and MRv2 (with YARN) on the same cluster?
Hadoop 2.0 has introduced a new framework YARN to write and execute different applications on Hadoop. So, YARN and MapReduce are two different concepts in Hadoop 2.0 and should not be mixed and used interchangeably. The right question is “Is it possible to run both MRv1 and MRv2 on a YARN enabled Hadoop 2.0 Cluster?” The answer to this question is a “No” as even though a Hadoop Cluster can be configured to run both MRv1 and MRv2 but can run only one set of daemons at any point of time. Both of these frameworks eventually use the same configuration files (yarn-site.xml and mapred-site.xml) to run the daemons, hence, only one of the two configuration can be enabled on a Hadoop Cluster.
Manika:
What is the difference between Next Generation MapReduce (MRv2) and YARN?
YARN and Next Generation MapReduce (MRv2) are two different concepts and technologies in Hadoop 2.0. YARN is a software framework which can be used to run not only MRv2 but other applications too. MRv2 is an application framework written using YARN API and it runs within YARN.
Bharat:
Does Hadoop 2.0 provide backward compatibility for Hadoop 1.x applications?
Neha:
Does Hadoop 1.0 to 2.0 migration require heavy application code migration?
No, Most of the application developed using “org.apache.hadoop.mapred” APIs, can run on YARN without any recompilation. YARN is binary compatible to MRv1 applications and “bin/hadoop” can be used to submit these applications on YARN.
Sherin :
What happens if Resource Manager node fails in Hadoop 2.0?
Starting from Hadoop Release 2.4.0, High Availability support for Resource Manager is also available. The ResourceManager uses Apache ZooKeeper for fail-over. When the Resource Manager node fails, a secondary node can quickly recover via cluster state saved in ZooKeeper. The ResourceManager, on a fail-over, restarts all of the queued and running applications.
Sabbirali:
Does Apache’s Hadoop framework work on Cloudera Hadoop?
Apache Hadoop was introduced in 2005 with the core MapReduce processing engine to support the distributed processing of large-scale data workloads stored in HDFS. It is an Open Source Project and has multiple distributions (similar to Linux). Cloudera Hadoop (CDH) is one such distribution from Cloudera. Other Similar distributions are HortonWorks, MapR, Microsoft HDInsight, IBM InfoSphere BigInsights etc.
Arulvadivel:
Any easy way to install Hadoop on my Laptop and try migration of Oracle database to Hadoop?
You can start with installing a HortonWorks Sandbox or Cloudera Quick VM on your Laptop (with at least 4 GB RAM and i3 or above processor). Use SQOOP to move data from Oracle to Hadoop as explained here.
Bhabani:
What are the best books available to learn Hadoop?
Start with Hadoop: The Definitive Guide by Tom White and Hadoop Operations by Eric Sammer.
Mahendra:
Is there any reading available for Hadoop 2.0 just like Hadoop the definitive guide?
Review the latest arrival on bookshelves written by few of the creators of Hadoop 2.0.
Stay tuned for more questions in this series.






































How do you see the prospects of a 8yr experienced professional into Hadoop? As number years in experience grows from 8 to 13yrs will hadoop help him be technical career path giving him challenges upto his experience?
Hi Neelu, the prospect for professionals with rich experience like you in Big Date space is tremendous. What we are seeing as of now is just a start and there is a lot of potential for professionals who will be the early movers in Big Data space. You can check out our blog post on this – https://www.edureka.co/blog/big-prospects-for-big-data/
You can also call us at US: 1800 275 9730 (Toll Free) or India: +91 88808 62004 to discuss in detail.
Thank you for your answer. I did read that column in your blog. Would you be able to detail out what kind of challenges. I am looking for something like, if you take my current profile in c++ after coding next challenges would design based on OOPs and archeitecture. Can you help me in this details.
Hi Neelu,
The right word to define challenge in this context is to learn something new like MapReduce. While you are exposed to c++, here you would be using core Java fundamentals. Overall, it will be a new experience and for sure Hadoop is the choice for IT professional these days.