Hadoop Cluster, an extraordinary computational system, designed to Store, Optimize and Analyse Petabytes of data, with astonishing Agility. In this article, I will explain the important concepts of our topic and by the end of this article, you will be able to set up a Hadoop Cluster by yourself.
I have lined up the docket for this article as follows:
- What is a Hadoop Cluster?
- Advantages of a Hadoop Cluster
- Facebook’s Hadoop Cluster
- Hadoop Cluster Architecture
- Setting up a Hadoop Cluster.
- Hadoop Cluster Management System
What is a Hadoop Cluster?
Before getting into our topic, let us understand what actually a basic Computer Cluster is.

A Cluster basically means that it is a Collection. A Computer Cluster is also a collection of interconnected computers which are capable enough to communicate with each other and work on a given task as a single unit.
Similarly, The Hadoop Cluster is a special type of computing cluster designed to perform Big-data analysis and also to store and manage huge amounts of data. It is a collection of commodity hardware interconnected with each other and working together as a single unit.
 It basically has a Master and numerous number of Slaves. Master assigns the tasks to the Slaves and guides the Slaves to perform any particular task.
It basically has a Master and numerous number of Slaves. Master assigns the tasks to the Slaves and guides the Slaves to perform any particular task.
Now that we know what a Hadoop Cluster is, Let us now understand its Advantages over other similar data processing units.
Advantages of a Hadoop Cluster
Some of the major Advantages are as follows:
- Scalable
- Cost-effective
- Flexible
- Fast
- Resilient to failure

Scalable: Hadoop is a beautiful storage platform with unlimited Scalability. Compared to RDBMS, Hadoop storage network can be expanded by just adding additional commodity hardware. Hadoop can run Business Applications over thousands of computers altogether and process petabytes of data.

Cost-effective: Traditional data storage units had many limitations and the major limitation was related to the Storage. Hadoop Clusters overcome it drastically by its distributed storage topology. The lack of storage can be handled by just adding additional storage units to the system.

Flexible: Flexibility is the major advantage of Hadoop Cluster. The Hadoop Cluster can process any type of data irrelevant of whether it is Structured, Semi-structured or completely Unstructured. this enables Hadoop to process multiple types of data directly from Social Media.

Fast: Hadoop Clusters can process petabytes of data within a fraction of second. This is possible because of the efficient Data Mapping Capabilities of Hadoop. The data processing tools are always kept available on all the Servers. i,e; The Data Processing tool is available on the same unit where the Data needed is stored.

Resilient to failure: Data loss in a Hadoop Cluster is a Myth. It is practically impossible to lose data in a Hadoop cluster as it follows Data Replication which acts as a backup storage unit in case of the Node Failure.
With this, let us now move on to our next topic which is related to Facebook’s Hadoop Cluster.
Facebook’s Hadoop Cluster
Following are the few important facts about Facebook’s Hadoop Cluster
- Since 2004 from its launch, Facebook is one of the biggest users of Hadoop Cluster.
- It is called as the Beefiest Hadoop cluster.
- it approximately uses 4000 machines and is capable to process Millions of Gigabytes together.
- Facebook has a 2.38 Billion number of active users.

To manage such a huge network, Facebook uses Distributed Storage Frameworks and Millions of developers writing MapReduce programs in multiple languages. It also uses SQL which drastically improved the process of Search, Log-Processing, Recommendation system starting from Data warehousing to Video and Image analysis.
Facebook is growing day to day by encouraging all possible updates to its cluster.

Cassandra and Hive
Cassandra was developed to perform NoSQL queries on Hadoop Clusters and Hive improved the query capability of Hadoop by using a subset of SQL.
Today, Facebook is one of the biggest corporations on earth thanks to its extensive data on over Two and a half billion active users.
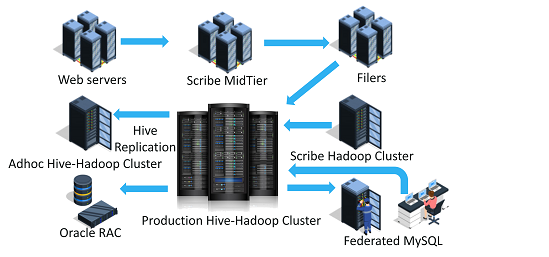
The overview of the Facebook Hadoop cluster is shown as above. Let us now move on to the Architecture of Hadoop cluster.
Hadoop Cluster Architecture
The Architecture of Hadoop consists of the following Components:
- HDFS
- YARN
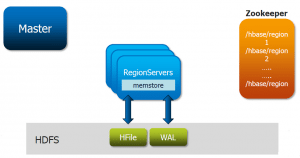
HDFS consists of the following components:
Name node: Name node is responsible for running the Master daemons. It stores the Metadata. Name node encounters the client request for the data then transfers the request to the data nodes which store the actual data. It is responsible for managing the health of all the Data nodes.
Data node: Data nodes are called as the Slaves of Name node and are responsible to Store the actual data and also to update the Task Status and Health Status to the Name node in the form of a Heartbeat.
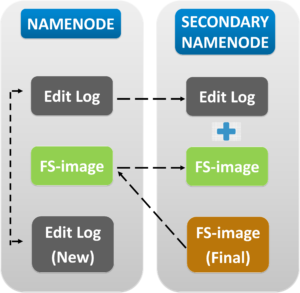
Secondary Name node: The Secondary Name node as it speaks is not actually a backup of Name node, but it actually acts as a Buffer which saves the latest updates to the FS-image which are obtained in the intermediate process and updates them to the FinalFS-image.
YARN consists of the following units:
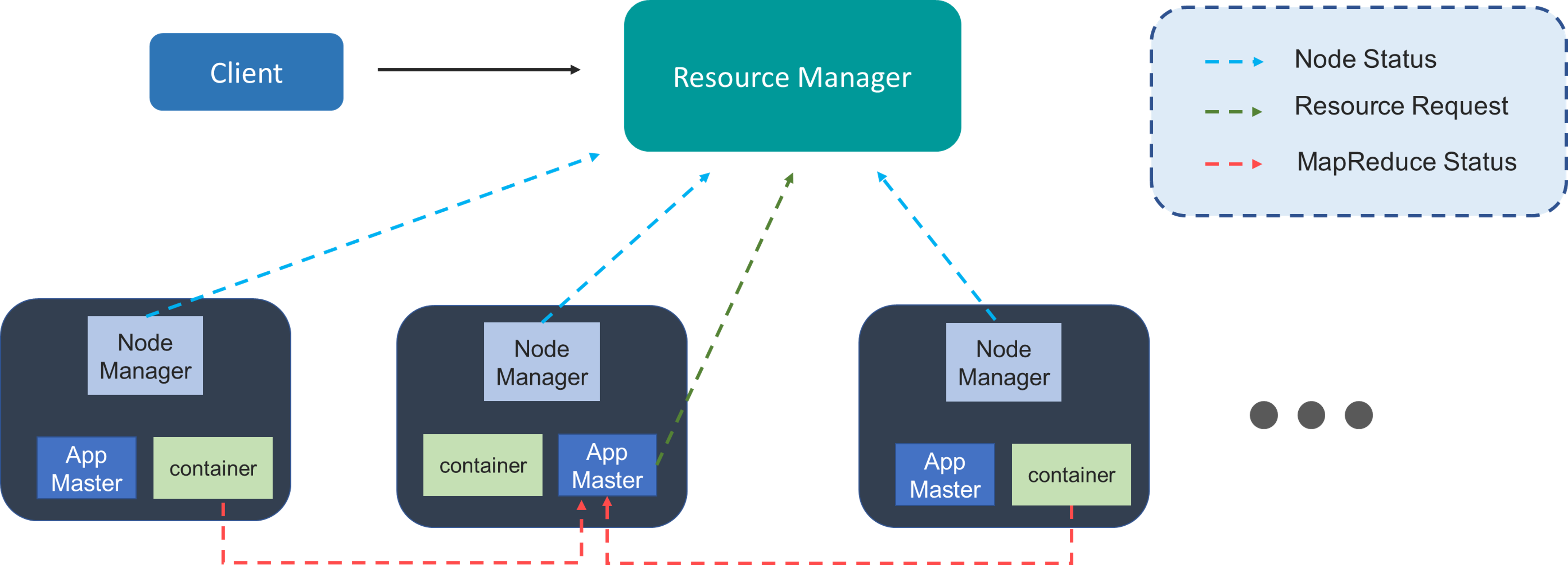
Node Manager: It is a Java utility that runs as a separate process from WebLogic Server and allows you to perform common operations tasks for a Managed Server, regardless of its location with respect to its Administration Server.
App Master: It is responsible for negotiating the resources between the Resource Manager and Node Manager.
Container: It is actually a collection of reserved amounts of resources allocated from the Resource Manager to work with a task assigned by the Node Manager.
Now, with this we shall have a look at the overview of the Hadoop cluster Architecture and followed by that we shall look into the Replication Factor and Rack Awareness Algorithm

The default Replication Factor in Hadoop is 3 as the image above describes that each block of memory is replicated for 3 times.
Rack Awareness Algorithm is all about Data Storage.
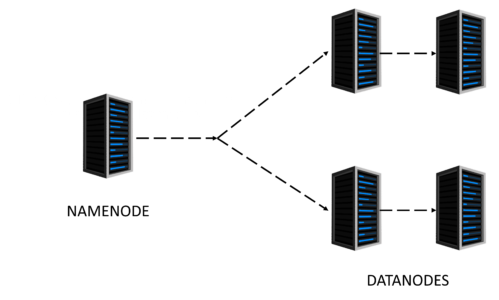
It says that the first Replica of the Actual data must be located in the Local rack and the rest of the Replicas will be stored on a different Remote rack.
Let us look into the following diagram to understand it in a better way.

With this we finished our Theory part, now let get into the Practical part where we learn to set up a Hadoop cluster with one Master and two Slaves.
For details, You can even check out tools and systems used by Big Data experts and its concepts with the Masters in data engineering.
Find out our Azure Data Engineer Course in Top Cities
Setting up a Hadoop Cluster.
Before getting started with our Hadoop Cluster, We need to make sure to meet the prerequisites of setting up the Hadoop Cluster.
The Prerequisites are as follows:
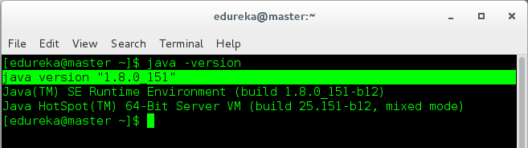
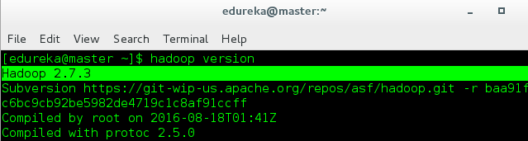
In case if you have not installed Hadoop, then you can refer to the Hadoop installation blog. We shall follow the following steps to set up a Hadoop Cluster with one Master and Two Slaves.
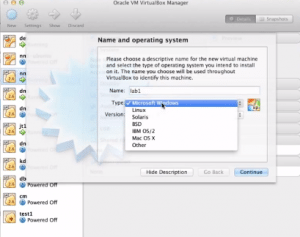
Step 1: Download VM Workstation 15 and install it on your Host Machine
Step 2: Browse your file system and select your virtual machine CentOS that is existing in your host system.
Step 3: Accept the terms and conditions and get started with your Virtual Linux Operating System.
Step 4: Follow the same Procedure for setting up the Slave Machines as well. Once the Virtual Operating Systems are loaded, your Workstation interface looks as below.
Step 5: Start your Master and all the Slaves altogether and then open a new terminal in all the machines and check for the IP Addresses of the machines. you can use the following code to check your IP Address.
IP Address of the Master

IP Address of Slave-1

IP Address of Slave-2

Step 6: Once you identify the IP Addresses of your machines, The next step would be Configuring them as Master and Slaves. It can be done by editing the hosts as follows.


Once the Master and Slaves are set, Let us start all the daemons and start the local host to check the HDFS Web user interface.
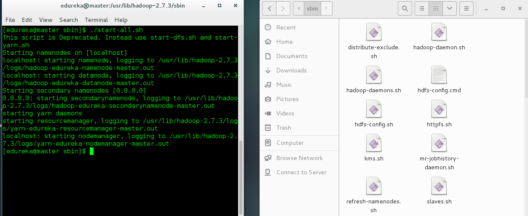
To Start all the daemons, You must open the terminal from the sbin folder as shown below. The location to the sbin folder would be:
usr/lib/hadoop-2.7.0/sbin
Once the terminal is opened in the sbin folder, use the start-all.sh command to start all the daemons.
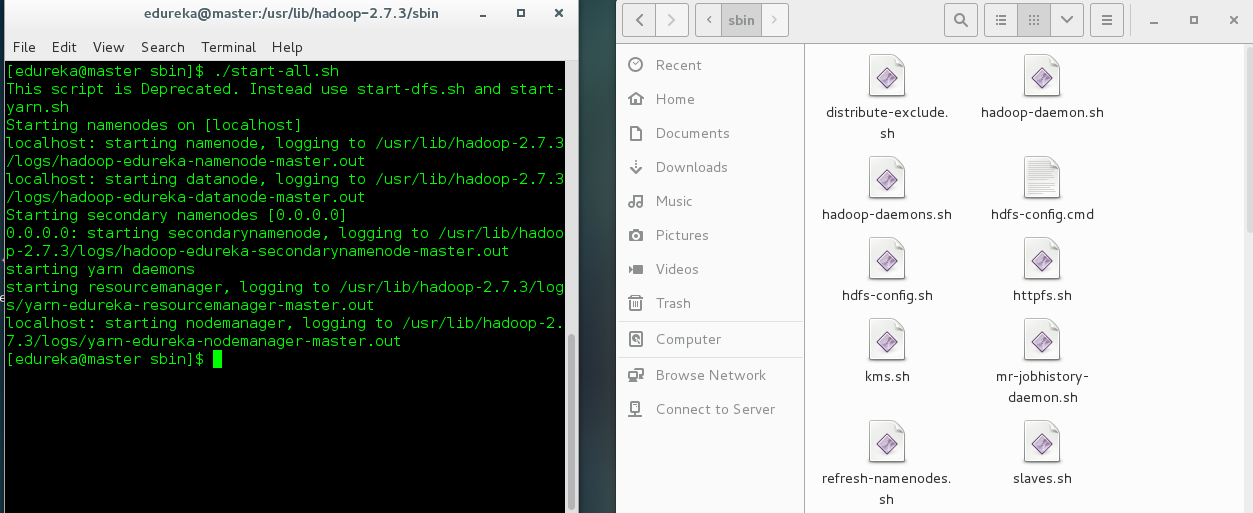
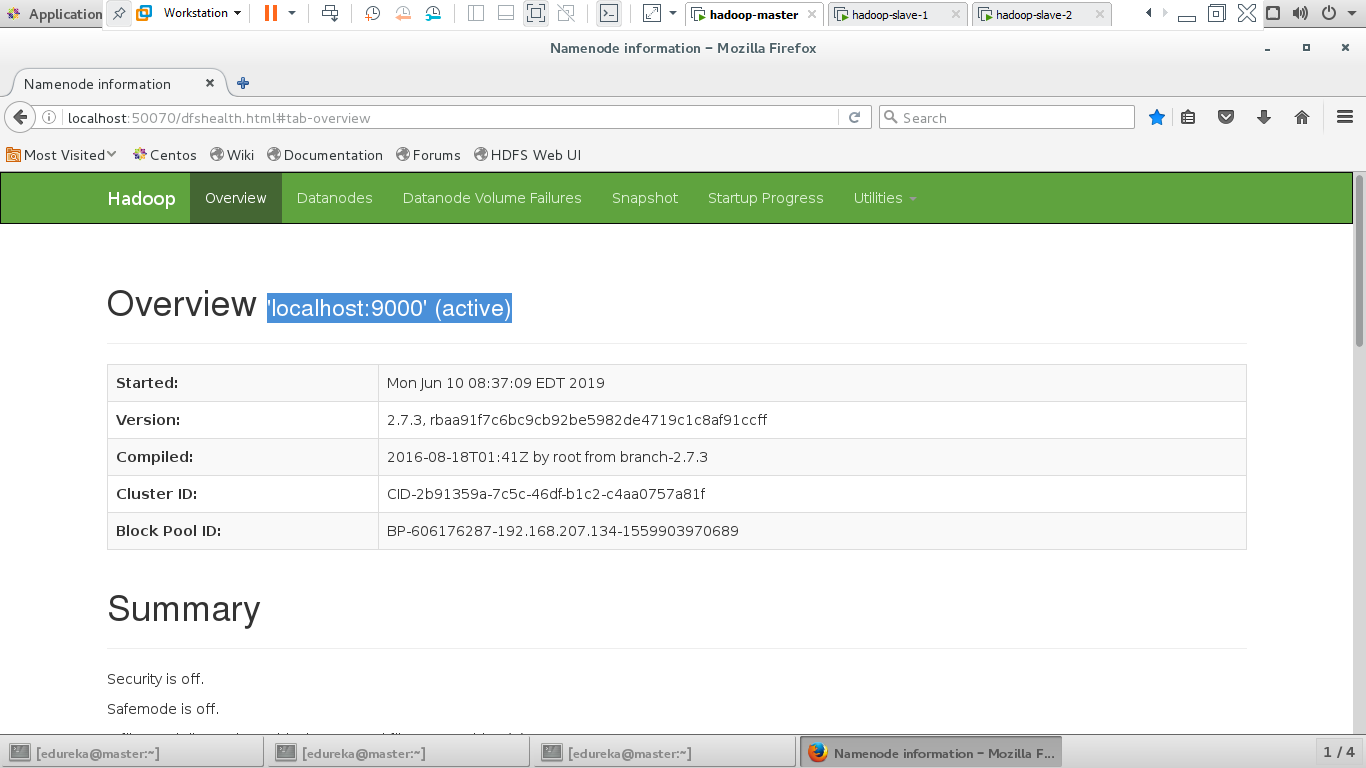
Once all the daemons are started, Let us check the HDFS Web User Interface.
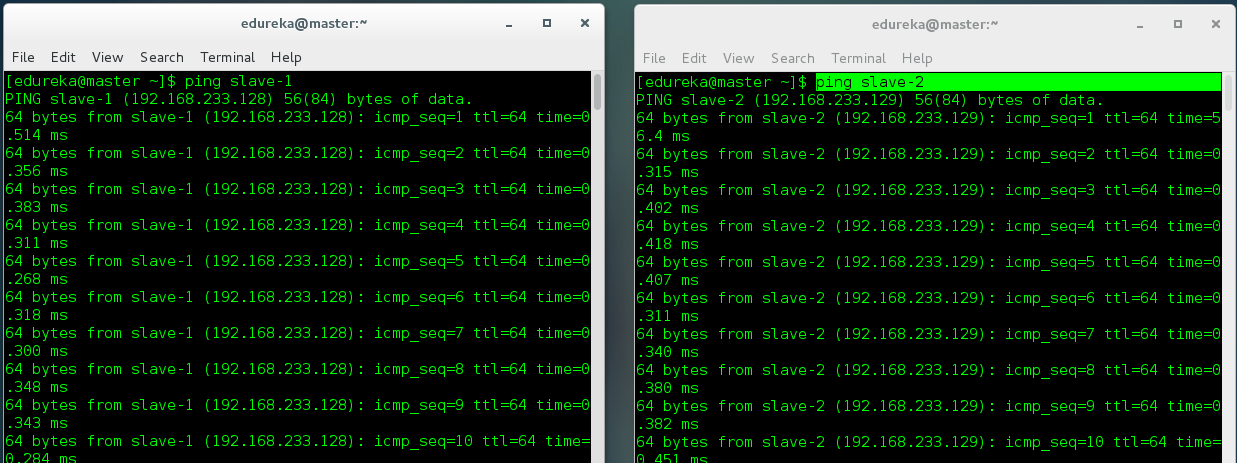
Step 7: Let us now try to communicate with the Master and Slaves by sending a ping to each one of them.
Master pinging to Slave-1 and Slave-2
Slave-1 pinging to Master
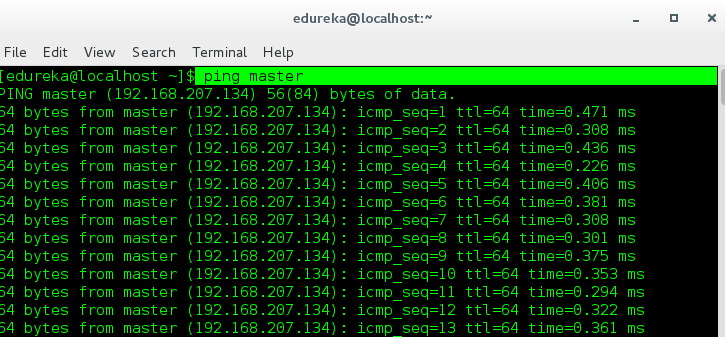
Slave-2 pinging to Master
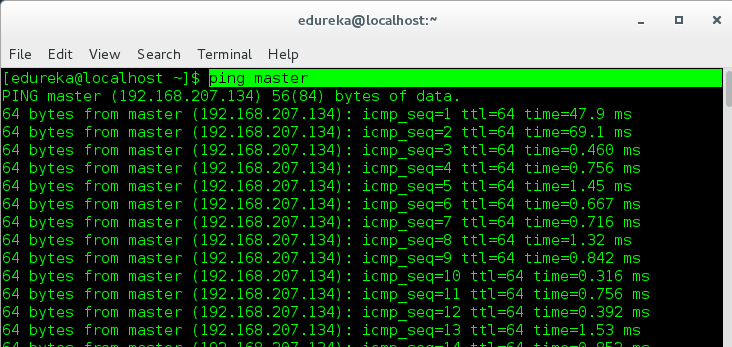
Now with this, we have finished our Demo Session, Now let us learn about Managing a Hadoop Cluster.
Unleash the power of distributed computing and scalable data processing with our Spark Course.
Ambari: The Hadoop Cluster Management System
- Hadoop is both a command line interface as well as an API.
- It does not require any tool in specific for managing and monitoring utilities.
- There are some options available such as:
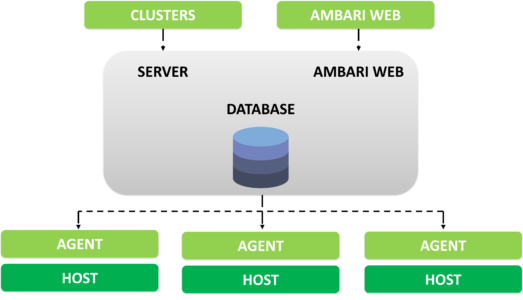
Ambari can be defined as an Open Source Administration tool which plays a crucial role in keeping track of Running Applications and their Status is what we call Apache Ambari. Basically, it is deployed on top of the Hadoop cluster.
Following the Architecture of Ambari
Let us now see how does a typical Ambari User Interface look like.
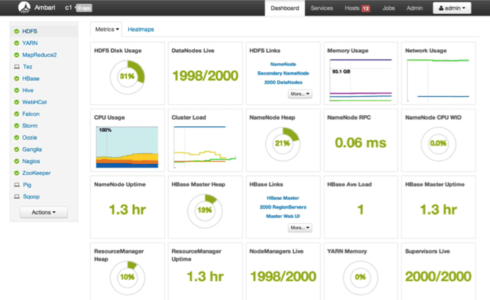
With this, we come to an end of this article. I hope I have thrown some light on to your knowledge on Hadoop and Hadoop Clusters and I hope you can create your own Hadoop Cluster and also be able to manage it on your own.
Now that you have understood Hadoop Cluster and its features, check out the Hadoop training by Edureka, a trusted online learning company with a network of more than 250,000 satisfied learners spread across the globe. The Edureka Big Data Hadoop Certification Training course helps learners become expert in HDFS, Yarn, MapReduce, Pig, Hive, HBase, Oozie, Flume and Sqoop using real-time use cases on Retail, Social Media, Aviation, Tourism, Finance domain.