This “What’s New in Hadoop 3.0” blog focus on the changes that are expected in Hadoop 3, as it’s still in alpha phase. Apache community has incorporated many changes and is still working on some of them. So, we will be taking a broader look at the expected changes.
The major changes that we will be discussing are:
- Minimum Required Java Version in Hadoop 3 is 8
- Support for Erasure Encoding in HDFS
- YARN Timeline Service v.2
- Shell Script Rewrite
- Shaded Client Jars
- Support for Opportunistic Containers
- MapReduce Task-Level Native Optimization
- Support for More than 2 NameNodes
- Default Ports of Multiple Services have been Changed
- Support for Filesystem Connector
- Intra-DataNode Balancer
- Reworked Daemon and Task Heap Management
Apache Hadoop 3 is going to incorporate a number of enhancements over the Hadoop-2.x. So, let us move ahead and look at each of the enhancements.
Changes Expected in Hadoop 3 | Getting to Know Hadoop 3 Alpha | Upcoming Hadoop 3 Features | Edureka
1. Minimum Required Java Version in Hadoop 3 is Increased from 7 to 8
In Hadoop 3, all Hadoop JARs are compiled targeting a runtime version of Java 8. So, users who are still using Java 7 or below have to upgrade to Java 8 when they will start working with Hadoop 3.
 Now let us discuss one of the important enhancement of Hadoop 3, i.e. Erasure Encoding, which will reduce the storage overhead while providing the same level of fault tolerance as earlier.
Now let us discuss one of the important enhancement of Hadoop 3, i.e. Erasure Encoding, which will reduce the storage overhead while providing the same level of fault tolerance as earlier.
2. Support for Erasure Encoding in HDFS
So now let us first understand what is Erasure Encoding.
 Generally, in storage systems, Erasure Coding is mostly used in Redundant Array of Inexpensive Disks (RAID).
Generally, in storage systems, Erasure Coding is mostly used in Redundant Array of Inexpensive Disks (RAID).
As you can see in the above image, RAID implements EC through striping, in which the logically sequential data (such as a file) is divided into smaller units (such as bit, byte, or block) and stores consecutive units on different disks.
Then for each stripe of original data cells, a certain number of parity cells are calculated and stored. This process is called encoding. The error on any striping cell can be recovered through decoding calculation based on surviving data cells and parity cells.
As we got an idea of Erasure coding, now let us first go through the earlier scenario of replication in Hadoop 2.x.

The default replication factor in HDFS is 3 in which one is the original data block and the other 2 are replicas which require 100% storage overhead each. So that makes 200% storage overhead and it consumes other resources like network bandwidth.
However, the replicas of cold datasets which have low I/O activities are rarely accessed during normal operations, but still, consume the same amount of resources as the original dataset.
Erasure coding stores the data and provide fault tolerance with less space overhead as compared to HDFS replication. Erasure Coding (EC) can be used in place of replication, which will provide the same level of fault-tolerance with less storage overhead.
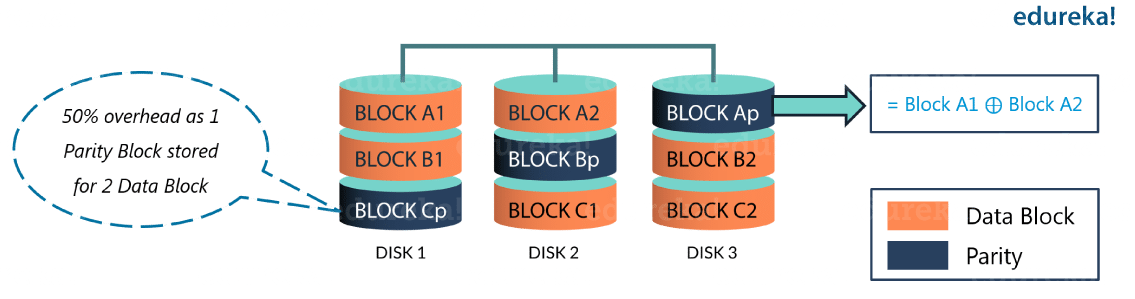 Integrating EC with HDFS can maintain the same fault-tolerance with improved storage efficiency. As an example, a 3x replicated file with 6 blocks will consume 6*3 = 18 blocks of disk space. But with EC (6 data, 3 parity) deployment, it will only consume 9 blocks (6 data blocks + 3 parity blocks) of disk space. This only requires the storage overhead up to 50%.
Integrating EC with HDFS can maintain the same fault-tolerance with improved storage efficiency. As an example, a 3x replicated file with 6 blocks will consume 6*3 = 18 blocks of disk space. But with EC (6 data, 3 parity) deployment, it will only consume 9 blocks (6 data blocks + 3 parity blocks) of disk space. This only requires the storage overhead up to 50%.
Since Erasure coding requires additional overhead in the reconstruction of the data due to performing remote reads, thus it is generally used for storing less frequently accessed data. Before deploying Erasure code, users should consider all the overheads like storage, network and CPU overheads of erasure coding.
From this Big Data Course designed by a Big Data professional, you will get 100% real-time project experience in Hadoop tools, commands and concepts.
Now to support the Erasure Coding effectively in HDFS they made some changes in the architecture. Lets us take a look at the architectural changes.
HDFS Erasure Encoding: Architecture
- NameNode Extensions – The HDFS files are striped into block groups, which have a certain number of internal blocks. Now to reduce NameNode memory consumption from these additional blocks, a new hierarchical block naming protocol was introduced. The ID of a block group can be deduced from the ID of any of its internal blocks. This allows management at the level of the block group rather than the block.
- Client Extensions – After implementing Erasure Encoding in HDFS, NameNode works on block group level & the client read and write paths were enhanced to work on multiple internal blocks in a block group in parallel.
- On the output/write path, DFSStripedOutputStream manages a set of data streamers, one for each DataNode storing an internal block in the current block group. A coordinator takes charge of operations on the entire block group, including ending the current block group, allocating a new block group, etc.
- On the input/read path, DFSStripedInputStream translates a requested logical byte range of data as ranges into internal blocks stored on DataNodes. It then issues read requests in parallel. Upon failures, it issues additional read requests for decoding.
- DataNode Extensions – The DataNode runs an additional ErasureCodingWorker (ECWorker) task for background recovery of failed erasure coded blocks. Failed EC blocks are detected by the NameNode, which then chooses a DataNode to do the recovery work. Reconstruction performs three key tasks:
- Read the data from source nodes and reads only the minimum number of input blocks & parity blocks for reconstruction.
- New data and parity blocks are decoded from the input data. All missing data and parity blocks are decoded together.
- Once decoding is finished, the recovered blocks are transferred to target DataNodes.
- ErasureCoding policy – To accommodate heterogeneous workloads, we allow files and directories in an HDFS cluster to have different replication and EC policies. Information about encoding & decoding files is encapsulated in an ErasureCodingPolicy class. It contains 2 pieces of information, i.e. the ECSchema & the size of a stripping cell.
The second most important enhancement in Hadoop 3 is YARN Timeline Service version 2 from YARN version 1 (in Hadoop 2.x). They are trying to make many upbeat changes in YARN Version 2.
3. YARN Timeline Service v.2
Hadoop is introducing a major revision of YARN Timeline Service i.e. v.2. YARN Timeline Service. It is developed to address two major challenges:
- Improving scalability and reliability of Timeline Service
- Enhancing usability by introducing flows and aggregation
YARN Timeline Service v.2 can be tested by the developers to provide feedback and suggestions. It should be exploited only in a test capacity. The security is not enabled in YARN Timeline Service v.2.
So, let us first discuss scalability and then we will discuss flows and aggregations.
YARN Timeline Service v.2: Scalability
YARN version 1 is limited to a single instance of writer/reader and does not scale well beyond small clusters. Version 2 uses a more scalable distributed writer architecture and a scalable backend storage. It separates the collection (writes) of data from serving (reads) of data. It uses distributed collectors, essentially one collector for each YARN application. The readers are separate instances that are dedicated to serving queries via REST API.
YARN Timeline Service v.2 chooses Apache HBase as the primary backing storage, as Apache HBase scales well to a large size while maintaining good response times for reads and writes.
YARN Timeline Service v.2: Usability Improvements
Now talking about usability improvements, in many cases, users are interested in the information at the level of “flows” or logical groups of YARN applications. It is much more common to launch a set or series of YARN applications to complete a logical application. Timeline Service v.2 supports the notion of flows explicitly. In addition, it supports aggregating metrics at the flow level as you can see in the below diagram.
 Now lets us look at the architectural level, how YARN version 2 works.
Now lets us look at the architectural level, how YARN version 2 works.
YARN Timeline Service v.2: Architecture
YARN Timeline Service v.2 uses a set of collectors (writers) to write data to the backend storage. The collectors are distributed and co-located with the application masters to which they are dedicated, as you can see in the below image. All data that belong to that application are sent to the application level timeline collectors with the exception of the resource manager timeline collector.

For a given application, the application master can write data for the application to the co-located timeline collectors. In addition, node managers of other nodes that are running the containers for the application also write data to the timeline collector on the node that is running the application master.
The resource manager also maintains its own timeline collector. It emits only YARN-generic life cycle events to keep its volume of writes reasonable.
The timeline readers are separate daemons separate from the timeline collectors, and they are dedicated to serving queries via REST API.
4. Shell Script Rewrite
The Hadoop shell scripts have been rewritten to fix many bugs, resolve compatibility issues and change in some existing installation. It also incorporates some new features. So I will list some of the important ones:
- All Hadoop shell script subsystems now execute hadoop-env.sh, which allows for all of the environment variables to be in one location.
- Daemonization has been moved from *-daemon.sh to the bin commands via the –daemon option. In Hadoop 3 we can simply use –daemon start to start a daemon, –daemon stop to stop a daemon, and –daemon status to set $? to the daemon’s status. For example, ‘hdfs –daemon start namenode’.
- Operations which trigger ssh connections can now use pdsh if installed.
- ${HADOOP_CONF_DIR} is now properly honored everywhere, without requiring symlinking and other such tricks.
- Scripts now test and report better error messages for various states of the log and pid dirs on daemon startup. Before, unprotected shell errors would be displayed to the user.
There are many more features you will know when Hadoop 3 will be in the beta phase. Now let us discuss the shaded client jar and know their benefits.
5. Shaded Client Jars
The hadoop-client available in Hadoop 2.x releases pulls Hadoop’s transitive dependencies onto a Hadoop application’s classpath. This can create a problem if the versions of these transitive dependencies conflict with the versions used by the application.
So in Hadoop 3, we have new hadoop-client-api and hadoop-client-runtime artifacts that shade Hadoop’s dependencies into a single jar. hadoop-client-api is compile scope & hadoop-client-runtime is runtime scope, which contains relocated third party dependencies from hadoop-client. So, that you can bundle the dependencies into a jar and test the whole jar for version conflicts. This avoids leaking Hadoop’s dependencies onto the application’s classpath. For example, HBase can use to talk with a Hadoop cluster without seeing any of the implementation dependencies.
Now let us move ahead and understand one more new feature, which has been introduced in Hadoop 3, i.e. opportunistic containers.
6. Support for Opportunistic Containers and Distributed Scheduling
A new ExecutionType has been introduced, i.e. Opportunistic containers, which can be dispatched for execution at a NodeManager even if there are no resources available at the moment of scheduling. In such a case, these containers will be queued at the NM, waiting for resources to be available for it to start. Opportunistic containers are of lower priority than the default Guaranteed containers and are therefore preempted, if needed, to make room for Guaranteed containers. This should improve cluster utilization.
 Guaranteed containers correspond to the existing YARN containers. They are allocated by the Capacity Scheduler, and once dispatched to a node, it is guaranteed that there are available resources for their execution to start immediately. Moreover, these containers run to completion as long as there are no failures.
Guaranteed containers correspond to the existing YARN containers. They are allocated by the Capacity Scheduler, and once dispatched to a node, it is guaranteed that there are available resources for their execution to start immediately. Moreover, these containers run to completion as long as there are no failures.
Opportunistic containers are by default allocated by the central RM, but support has also been added to allow opportunistic containers to be allocated by a distributed scheduler which is implemented as an AMRMProtocol interceptor.
Now moving ahead, let us take a look how MapReduce performance has been optimized.
7. MapReduce Task-Level Native Optimization
In Hadoop 3, a native Java implementation has been added in MapReduce for the map output collector. For shuffle-intensive jobs, this improves the performance by 30% or more.
They added a native implementation of the map output collector. For shuffle-intensive jobs, this may provide speed-ups of 30% or more. They are working on native optimization for MapTask based on JNI. The basic idea is to add a NativeMapOutputCollector to handle key value pairs emitted by the mapper, therefore sort, spill, IFile serialization can all be done in native code. They are still working on the Merge code.
Now let us take a look, how Apache community is trying to make Hadoop 3 more fault tolerant.
8. Support for More than 2 NameNodes
In Hadoop 2.x, HDFS NameNode high-availability architecture has a single active NameNode and a single Standby NameNode. By replicating edits to a quorum of three JournalNodes, this architecture is able to tolerate the failure of any one NameNode.
However, business critical deployments require higher degrees of fault-tolerance. So, in Hadoop 3 allows users to run multiple standby NameNodes. For instance, by configuring three NameNodes (1 active and 2 passive) and five JournalNodes, the cluster can tolerate the failure of two nodes.
 Next, we will look at default ports of Hadoop services that have been changed in Hadoop 3.
Next, we will look at default ports of Hadoop services that have been changed in Hadoop 3.
9. Default Ports of Multiple Services have been Changed
Earlier, the default ports of multiple Hadoop services were in the Linux ephemeral port range (32768-61000). Unless a client program explicitly requests a specific port number, the port number used is an ephemeral port number. So at startup, services would sometimes fail to bind to the port due to a conflict with another application.
Thus the conflicting ports with ephemeral range have been moved out of that range, affecting port numbers of multiple services, i.e. the NameNode, Secondary NameNode, DataNode, etc. Some of the important ones are:

There are few more which are expected. Now moving on, let us know what are new Hadoop 3 file system connecters.
10. Support for Filesystem Connector
Hadoop now supports integration with Microsoft Azure Data Lake and Aliyun Object Storage System. It can be used as an alternative Hadoop-compatible filesystem. First Microsoft Azure Data Lake was added and then they added Aliyun Object Storage System as well. You might expect some more.
Let us understand how Balancer have been improved within multiple disks in a Data Node.
11. Intra-DataNode Balancer

A single DataNode manages multiple disks. During a normal write operation, data is divided evenly and thus, disks are filled up evenly. But adding or replacing disks leads to skew within a DataNode. This situation was earlier not handled by the existing HDFS balancer. This concerns intra-DataNode skew.

Now Hadoop 3 handles this situation by the new intra-DataNode balancing functionality, which is invoked via the hdfs diskbalancer CLI.
Now let us take a look how various memory managements have taken place.
12. Reworked Daemon and Task Heap Management
A series of changes have been made to heap management for Hadoop daemons as well as MapReduce tasks.
- New methods for configuring daemon heap sizes. Notably, auto-tuning is now possible based on the memory size of the host, and the HADOOP_HEAPSIZE variable has been deprecated.In its place, HADOOP_HEAPSIZE_MAX and HADOOP_HEAPSIZE_MIN have been introduced to set Xmx and Xms, respectively. All global and daemon-specific heap size variables now support units. If the variable is only a number, the size is assumed to be in megabytes.
- Simplification of the configuration of map and reduce task heap sizes, so the desired heap size no longer needs to be specified in both the task configuration and as a Java option. Existing configs that already specify both are not affected by this change.
I hope this blog was informative and added value to you. Apache community is still working on multiple enhancements which might come up until beta phase. We will keep you updated and come up with more blogs and videos on Hadoop 3.
Now that you know the expected changes in Hadoop 3, check out the Big Data training in Chennai by Edureka, a trusted online learning company with a network of more than 250,000 satisfied learners spread across the globe. The Edureka Big Data Hadoop Certification Training course helps learners become expert in HDFS, Yarn, MapReduce, Pig, Hive, HBase, Oozie, Flume and Sqoop using real-time use cases on Retail, Social Media, Aviation, Tourism, Finance domain.
Got a question for us? Please mention it in the comments section and we will get back to you.