
Advanced Certification in Agentic AI Engineer ...
- 65k Enrolled Learners
- Weekend
- Live Class
(45931)





 Copy Link!
Copy Link!_1648290501.jpg)
In Machine Learning, concept learning can be termed as “a problem of searching through a predefined space of potential hypothesis for the hypothesis that best fits the training examples” – Tom Mitchell. In this article, we will go through one such concept learning algorithm known as the Find-S algorithm. If you want to go beyond this article and really want the level of expertise in you – you can get certified in Machine Learning Certification!
Machine Learning Full Course – Learn Machine Learning 10 Hours | Machine Learning Tutorial | Edureka
Machine Learning Course lets you master the application of AI with the expert guidance. It includes various algorithms with applications.
The following topics are discussed in this article.
In order to understand Find-S algorithm, you need to have a basic idea of the following concepts as well:
1. Concept Learning
Let’s try to understand concept learning with a real-life example. Most of human learning is based on past instances or experiences. For example, we are able to identify any type of vehicle based on a certain set of features like make, model, etc., that are defined over a large set of features.
These special features differentiate the set of cars, trucks, etc from the larger set of vehicles. These features that define the set of cars, trucks, etc are known as concepts.
Similar to this, machines can also learn from concepts to identify whether an object belongs to a specific category or not. Any algorithm that supports concept learning requires the following:
2. General Hypothesis
Hypothesis, in general, is an explanation for something. The general hypothesis basically states the general relationship between the major variables. For example, a general hypothesis for ordering food would be I want a burger.
G = { ‘?’, ‘?’, ‘?’, …..’?’}
3. Specific Hypothesis
The specific hypothesis fills in all the important details about the variables given in the general hypothesis. The more specific details into the example given above would be I want a cheeseburger with a chicken pepperoni filling with a lot of lettuce.
S = {‘Φ’,’Φ’,’Φ’, ……,’Φ’}
Now ,let’s talk about the Find-S Algorithm in Machine Learning.
The Find-S algorithm follows the steps written below:
Now that we are done with the basic explanation of the Find-S algorithm, let us take a look at how it works.
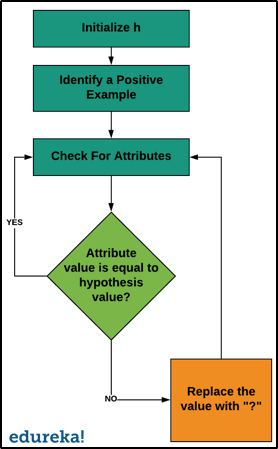
There are a few limitations of the Find-S algorithm listed down below:
Top 10 Trending Technologies to Learn in 2025 | Edureka
Now that we are aware of the limitations of the Find-S algorithm, let us take a look at a practical implementation of the Find-S Algorithm.
To understand the implementation, let us try to implement it to a smaller data set with a bunch of examples to decide if a person wants to go for a walk.
The concept of this particular problem will be on what days does a person likes to go on walk.
| Time | Weather | Temperature | Company | Humidity | Wind | Goes |
| Morning | Sunny | Warm | Yes | Mild | Strong | Yes |
| Evening | Rainy | Cold | No | Mild | Normal | No |
| Morning | Sunny | Moderate | Yes | Normal | Normal | Yes |
| Evening | Sunny | Cold | Yes | High | Strong | Yes |
Looking at the data set, we have six attributes and a final attribute that defines the positive or negative example. In this case, yes is a positive example, which means the person will go for a walk.
So now, the general hypothesis is:
h0 = {‘Morning’, ‘Sunny’, ‘Warm’, ‘Yes’, ‘Mild’, ‘Strong’}
This is our general hypothesis, and now we will consider each example one by one, but only the positive examples.
h1= {‘Morning’, ‘Sunny’, ‘?’, ‘Yes’, ‘?’, ‘?’}
h2 = {‘?’, ‘Sunny’, ‘?’, ‘Yes’, ‘?’, ‘?’}
We replaced all the different values in the general hypothesis to get a resultant hypothesis. Now that we know how the Find-S algorithm works, let us take a look at an implementation using Python.
Let’s try to implement the above example using Python. The code to implement the Find-S algorithm using the above data is given below.
import pandas as pd
import numpy as np
#to read the data in the csv file
data = pd.read_csv("data.csv")
print(data,"n")
#making an array of all the attributes
d = np.array(data)[:,:-1]
print("n The attributes are: ",d)
#segragating the target that has positive and negative examples
target = np.array(data)[:,-1]
print("n The target is: ",target)
#training function to implement find-s algorithm
def train(c,t):
for i, val in enumerate(t):
if val == "Yes":
specific_hypothesis = c[i].copy()
break
for i, val in enumerate(c):
if t[i] == "Yes":
for x in range(len(specific_hypothesis)):
if val[x] != specific_hypothesis[x]:
specific_hypothesis[x] = '?'
else:
pass
return specific_hypothesis
#obtaining the final hypothesis
print("n The final hypothesis is:",train(d,target))
Output:

This brings us to the end of this article where we have learned the Find-S Algorithm in Machine Learning with its implementation and use case. I hope you are clear with all that has been shared with you in this tutorial.
With immense applications and easier implementations of Python with data science, there has been a significant increase in the number of jobs created for data science every year. Enroll for Edureka’s Data Science with Python and get hands-on experience with real-time industry projects along with 24×7 support, which will set you on the path of becoming a successful Data Scientist,
We are here to help you with every step on your journey and come up with a curriculum that is designed for students and professionals who want to be a Machine Learning Engineer. The course is designed to give you a head start into Python programming and train you for both core and advanced Python concepts along with various Machine learning Algorithms like SVM, Decision Tree, etc.
If you come across any questions, feel free to ask all your questions in the comments section of “Find-S Algorithm In Machine Learning” and our team will be glad to answer.












 Thank you for registering Join Edureka Meetup community for 100+ Free Webinars each month JOIN MEETUP GROUP
Thank you for registering Join Edureka Meetup community for 100+ Free Webinars each month JOIN MEETUP GROUP



