Hadoop Components stand unrivalled when it comes to handling Big Data and with their outperforming capabilities, they stand superior. In this article, we shall discuss the major Hadoop Components which played the key role in achieving this milestone in the world of Big Data.
What is Hadoop?
Hadoop can be defined as a collection of Software Utilities that operate over a network of computers with Software Frameworks on a distributed storage environment in order to process the Big Data applications in the Hadoop cluster.
Let us look into the Core Components of Hadoop.
Hadoop Core Components
The Core Components of Hadoop are as follows:

Let us discuss each one of them in detail.
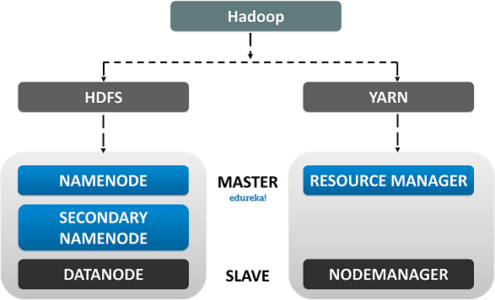
Hadoop Architecture
MapReduce: It is a Software Data Processing model designed in Java Programming Language. MapReduce is a combination of two individual tasks, namely:
- Map: It takes data and set then divides it into chunks such that they are converted into a new format which would be in the form of a key-value pair.
- Reduce: It is the second part where the Key/Value pairs are reduced to tuples.
The MapReduce process enables us to perform various operations over the big data such as Filtering and Sorting and many such similar ones.
HDFS is the primary storage unit in the Hadoop Ecosystem. The HDFS is the reason behind the quick data accessing and generous Scalability of Hadoop.
You can get a better understanding with the Data Engineering Training in London.
The HDFS comprises the following components.
- NameNode
- DataNode
- Secondary NameNode
Explore and learn more about HDFS in this Big Data Course, which was designed by a Top Industry Expert from Big Data platform.
Let us Discuss each one of them in detail.
- Name node: The Name Node is the centralized piece of the HDFS. It known as the Master and it is designed to store the Meta Data. Name Node is responsible for monitoring the Health Status of the Slave Nodes and to assign Tasks to the Data Nodes.
- Data Node: Data Node is the actual unit which stores the data. It is known as the Slave and it responds to the Name Node about its Health Status and the task status in the form of a Heartbeat. If the Data Node fails to respond to the Name Node, then the Name Node considers the Slave Node to be Dead and reassigns the task to the Next available Data Node.
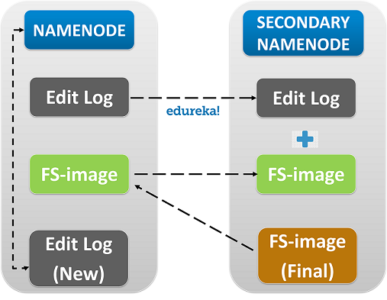
- Secondary Name Node: As the name speaks, the Secondary Name Node is not a backup of the name node. It acts as a Buffer to the Name Node. It stores the intermediate updates the FS-image of the Name Node in the Edit-log and updates the information to theFinalFS-image when the name node is inactive.
The next one in the docket is the YARN.
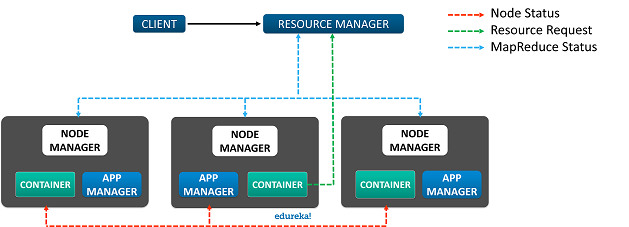
The YARN or Yet Another Resource Negotiator is the update to Hadoop since its second version. It is responsible for Resource management and Job Scheduling. Yarn comprises of the following components:
- Resource Manager: It is the core component of Yarn and is considered as the Master, responsible for providing generic and flexible frameworks to administer the computing resources in a Hadoop Cluster.
- Node Manager: It is the Slave and it serves the ResourceManager. Node Manager is assigned to all the Nodes in a Cluster. The main responsibility of the Node Manager is to monitor the Status of the Container and App Manager.
- App Manager: It manages data processing in the Container and requests the Container resources from the Resource Manager.
- Container: Container is where the actual data processing takes place.
With this we are finished with the Core Components in Hadoop, now let us get into the Major Components in the Hadoop Ecosystem:
You can even check out the details of Big Data with the Data Engineer Training.
Hadoop Ecosystem
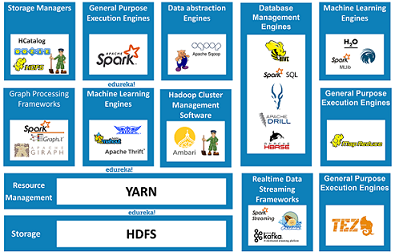
The Components in the Hadoop Ecosystem are classified into:
- Storage
- General Purpose Execution Engines
- Database Management Tools
- Data Abstraction Engines
- Real-Time Data Streaming
- Graph-Processing Engines
- Machine Learning
- Cluster Management

Data Storage

Hadoop Distributed File System, it is responsible for Data Storage. It provides Distributed data processing capabilities to Hadoop. HDFS is Fault Tolerant, Reliable and most importantly it is generously Scalable.
- HDFS supports both Vertical and Horizontal Scalability.
- HDFS has this unique Replication Factor which solves the issue of unexpected Data Loss.

HCATALOG is a Table Management tool for Hadoop. It provides tabular data store of HIVE to users such that the users can perform operations upon the data using the advanced data processing tools such as the Pig, MapReduce etc.
- Apart from Interpreting and Translating, HCatalog can Store information in Binary Format.
- HCatalog offers Kerberos based Authentication.
 Zookeeper is known as the centralized Open Source server responsible for managing the configuration information, naming conventions and synchronisations for Hadoop clusters.
Zookeeper is known as the centralized Open Source server responsible for managing the configuration information, naming conventions and synchronisations for Hadoop clusters.
- The Zookeeper is a Client-Server based model.
- Collection of servers in the environment are called a Zookeeper Ensemble.

Oozie is a scheduler system responsible to manage and schedule jobs in a distributed environment. It runs multiple complex jobs in a sequential order to achieve a complex job done.
- Oozie has client API and command line interface which can be used to launch, control and monitor the job from Java application.
- Using its Web Service APIs one can control jobs from anywhere.
Now let us discuss a few General Purpose Execution Engines. The first one is
General Purpose Execution Engines

MapReduce is a Java–based parallel data processing tool designed to handle complex data sets in Hadoop so that the users can perform multiple operations such as filter, map and many more. MapReduce is used in functional programming.
- MapReduce Programming Model System is Language Independent.
- It supports Data Local Processing.

Spark is an In-Memory cluster computing framework with lightning-fast agility. It can perform Real-time data streaming and ETL. Spark can also be used for micro-batch processing.
- Spark Code is Reusable in Batch-Processing environment.
- Spark supports 80 High-Level Operators.

Tez is an extensible, high-performance data processing framework designed to provide batch processing as well as interactive data processing. It can execute a series of MapReduce jobs collectively, in the form of a single Job. This improves the processing to an exponential level.
- Optimal resource management.
- Plan reconfiguration at run-time.
- Dynamic physical data flow decisions.
With this let us now move into the Hadoop components dealing with the Database management system. Firstly,
Database Management Tools

Hive is a Data warehouse project by the Apache Software Foundation, and it was designed to provide SQL like queries to the databases. Hive is also used in performing ETL operations, HIVE DDL and HIVE DML.
- It stores schema in a database and processed data into HDFS.
- It is designed for OLAP.
- It is familiar, fast, scalable, and extensible.

Spark SQL is a module for structured data processing. It acts as a distributed Query engine. It provides programming abstractions for data frames and is mainly used in importing data from RDDs, Hive, and Parquet files.
- Integration With Spark.
- Uniform Data Access.
- Hive Compatibility.
- Performance And Scalability

Impala is an in-memory Query processing engine. It is used in Hadoop Clusters. it is designed to integrate itself with Hive meta store and share table information between the components.
- Familiar SQL interface that data scientists and analysts already know.
- Ability to query high volumes of data (“big data”) in Apache Hadoop.

Apache Drill is a low latency distributed query engine. Its major objective is to combine a variety if data stores by just a single query. It is capable to support different varieties of NoSQL databases.
- High-performance scale with support for thousands of users across thousands of nodes.
- All the SQL analytics functionality.
- End-to-end security by default with industry Standard Authentication mechanisms.

HBase is an open-source, non-relational distributed database designed to provide random access to a huge amount of distributed data. Like Drill, HBase can also combine a variety of data stores just by using a single query.
- It has automatic failure support.
- It provides consistent read and writes.
- It integrates with Hadoop, both as a source and a destination.
- It has easy java API for client
With this, let us now get into Hadoop Components dealing with Data Abstraction.
Find out our Azure Data Engineer Course in Top Cities
Data Abstraction Engines

Pig is a high-level Scripting Language. It was designed to provide users to write complex data transformations in simple ways at a scripting level. The pig can perform ETL operations and also capable enough to analyse huge data sets.
- Automatic Optimization in the execution of Tasks.
- Provides Multiple-Query Approach
- Every script written in Pig is internally converted into a MapReduce job eliminating the Compilation Stage.

Apache Sqoop is a simple command line interface application designed to transfer data between relational databases in a network. It is basically a data ingesting tool. it enables to import and export structured data at an enterprise level.
- It is capable to perform Parallel Import and Export jobs.
- Provides Kerberos Security integration.
- Loads data directly into Hive/HBase.
Now let us learn about, the Hadoop Components in Real-Time Data Streaming.
Real-Time Data Streaming Tools

Spark Streaming is basically an extension of Spark API. It was designed to provide scalable, High-throughput and Fault-tolerant Stream processing of live data streams.
- Apart from data streaming, Spark Streaming is capable to support Machine Learning and Graph Processing.
- Spark Streaming provides high-level abstraction Data Streaming which is known as DStream or Discrete Stream

Kafka is an open source Data Stream processing software designed to ingest and move large amounts of data with high agility. it uses Publish, Subscribes and Consumer model.
- The Kafka cluster can handle failures with the Masters and Databases.
- Kafka has high throughput for both publishing and subscribing messages even if many TB of messages is stored.

Flume is an open source distributed and reliable software designed to provide collection, aggregation and movement of large logs of data.
- Flume supports Multi-hop flows, fan-in fan-out flows, contextual routing.
- Flume can collect the data from multiple servers in real-time
Now, let us understand a few Hadoop Components based on Graph Processing
Graph Processing Engines

Giraph is an interactive graph processing framework which utilizes Hadoop MapReduce implementation to process graphs. It is majorly used to analyse social media data.
- Giraph is based on Google’sPregel graph processing framework.
- Giraph can perform offline Batch Processing of semi-structured graph data on a massive scale.

GraphX is Apache Spark’s API for graphs and graph-parallel computation. GraphX unifies ETL (Extract, Transform & Load) process, exploratory analysis and iterative graph computation within a single system
- GraphX is Apache Spark’s API for graphs and graph-parallel computation.
- Comparable performance to the fastest specialized graph processing systems.
Let’s get things a bit more interesting. Now we shall deal with the Hadoop Components in Machine Learning.
Machine Learning Engines

H2O is a fully open source, distributed in-memory machine learning platform with linear scalability. The H2O platform is used by over R & Python communities
- H2O is open-source software designed for Big Data Analytics.
- H2O allows you to fit in thousands of potential models as a part of discovering patterns in data.

Oryx is a general lambda architecture tier providing batch/speed/serving Layers. Its major objective is towards large scale machine learning.
- It can continuously build models from a stream of data at a large scale using Apache Hadoop.
- It implements a Lambda architecture.
- In Oryx, models are exchanged in PMML format.

Spark MLlib is a scalable Machine Learning Library. It was designed to provide Machine learning operations in spark.
- Extraction: Extracting features from “raw” data.
- Transformation: Scaling, converting, or modifying features.
- Selection: Selecting a subset of a larger set of features.

Avro is a row-oriented remote procedure call and data Serialization tool. It is used in dynamic typing. Avro is majorly used in RPC.
- Avro is a language-neutral data serialization system.
- It can be processed by many languages (currently C, C++, C#, Java, Python, and Ruby).
- Avro creates a binary structured format that is both compressible and splittable

Thrift is an interface definition language and binary communication protocol which allows users to define data types and service interfaces in a simple definition file. Thrift is mainly used in building RPC Client and Servers.
- Everything is specified in an IDL(Interface Description Language) file from which bindings for many languages can be generated.
- language bindings – Thrift is supported in multiple languages and environments.

Mahout was developed to implement distributed Machine Learning algorithms. It is capable to store and process big data in a distributed environment across a cluster using simple programming models.
- Mahout offers the coder a ready-to-use framework for doing data mining tasks on large volumes of data.
- Mahout lets applications to analyze large sets of data effectively and in quick time.
now finally, let’s learn about Hadoop component used in Cluster Management.
Cluster Management
 Ambari is a Hadoop cluster management software which enables system administrators to manage and monitor a Hadoop cluster.
Ambari is a Hadoop cluster management software which enables system administrators to manage and monitor a Hadoop cluster.
- Simplified Installation, Configuration and Management. Easily and efficiently create, manage and monitor clusters at scale.
- Centralized Security Setup.
- Full Visibility into Cluster Health.
ZooKeeper is essentially a centralized service for distributed systems to a hierarchical key-value store It is used to provide a distributed configuration service, synchronization service, and naming registry for large distributed systems.
- Manage configuration across nodes
- Implement reliable messaging
 With this we come to an end of this article, I hope you have learnt about the Hadoop and its Architecture with its Core Components and the important Hadoop Components in its ecosystem.
With this we come to an end of this article, I hope you have learnt about the Hadoop and its Architecture with its Core Components and the important Hadoop Components in its ecosystem.
For details, You can even check out tools and systems used by Big Data experts and its concepts with the Masters in data engineering.
Now that you have understood Hadoop Core Components and its Ecosystem, check out the Hadoop training in Pune by Edureka, a trusted online learning company with a network of more than 250,000 satisfied learners spread across the globe. The Edureka’s Big Data Architect Course helps learners become expert in HDFS, Yarn, MapReduce, Pig, Hive, HBase, Oozie, Flume and Sqoop using real-time use cases on Retail, Social Media, Aviation, Tourism, Finance domain.