







In this second Apache Drill blog post, we will learn how integrate Hive and HBase with Apache Drill. Apache Drill provides inbuilt storage plugins for Hive and HBase integration. We just need to edit the configurations of these storage plugins and connect Drill.
Check out the first Apache Drill blog in the series here.
First, let us see how to connect Apache Drill with Hive storage plugin.
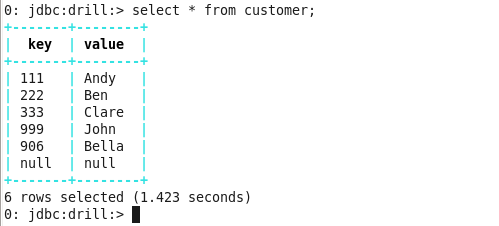
In the snapshot below, you can see that I have a table customer which has some data. Now we will connect Hive with Drill and access the same table from Drill.


Start Drillbit service
Command: ./bin/Drillbit.sh start
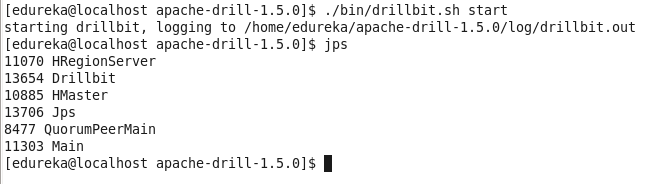

Start Drill shell
Command: Drill-conf


Next, open the Drill UI in the browser localhost:8047
You will see Hive in the disabled storage plugins. Click on Update for Hive.
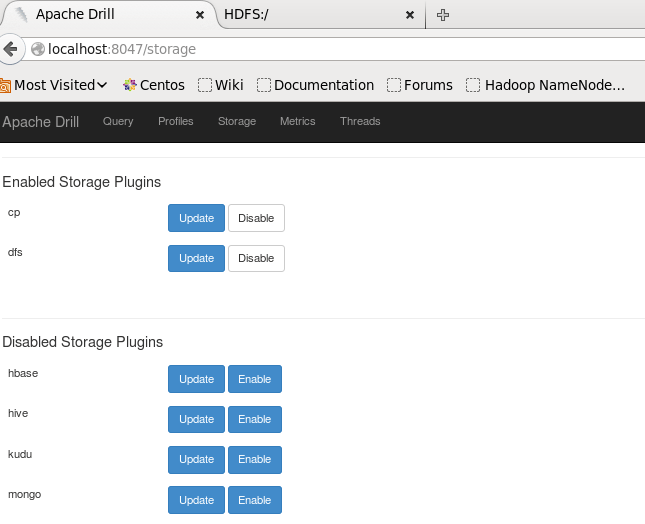

Edit the configurations according to your existing Hive settings that are available in hive-site.xml
After editing, click on Enable.
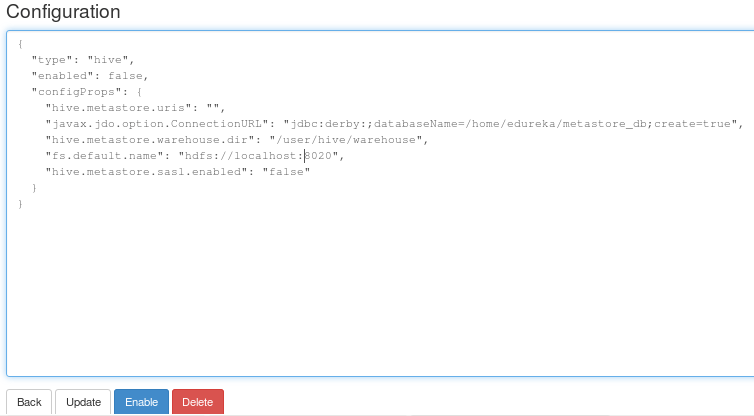

You will now find Hive now in the Enabled Storage Plugin.

Run the command below command in the Drill shell to access Hive from Drill.
Command: use hive;


You can now access the customer table from Drill. You have successfully integrated Hive with Drill.
Command: select * from customer;

Next, to enable the HBase storage plugin, we will follow the same steps as Hive. Click on update for HBase and edit the configurations accordingly.
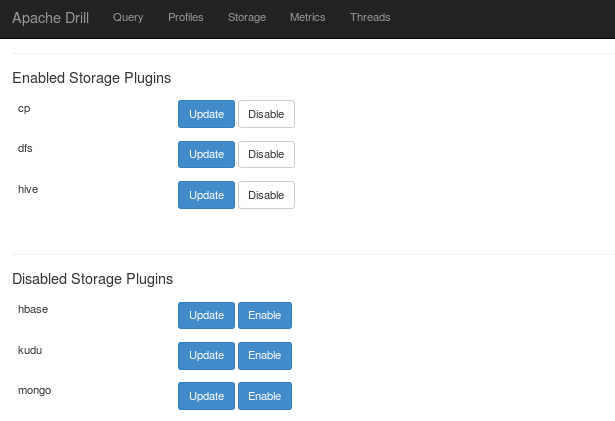

Click on enable after editing the configurations:


Now, I have the “students” table in my HBase which has some data. Let us see if we can access it now through Drill.


Run the command below in Drill to use the HBase storage plugin.
Command: use HBase;


Run a query to the HBase student table.
Command: select * from students;


The above query returns results that are not useable. In the next step, we have to convert the data from byte arrays to UTF8 types that are meaningful.
Issue the following query, that includes the CONVERT_FROM function, to convert the students table to typed data:
Command: SELECT CONVERT_FROM(row_key, ‘UTF8’) AS studentid,
CONVERT_FROM(students.account.name, ‘UTF8’) AS name,
CONVERT_FROM(students.address.state, ‘UTF8’) AS state,
CONVERT_FROM(students.address.street, ‘UTF8’) AS street,
CONVERT_FROM(students.address.zipcode, ‘UTF8’) AS zipcode
From students;
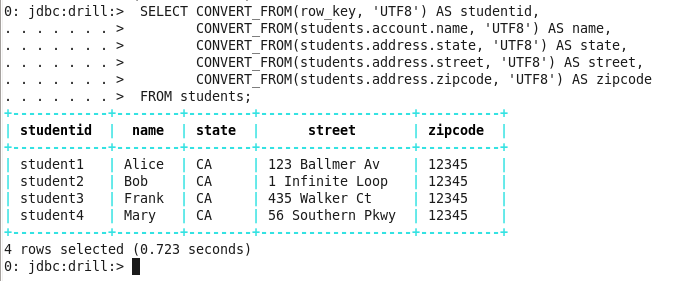

You can now successfully access HBase through Apache Drill.
Got a question for us? Mention them in the comment section and we will get back to you.
Related Posts:
Get Started with Apache Spark and Scala
Get Started with Big Data and Hadoop
Drilling Down On Apache Drill, the New-Age Query Engine Part 1