





Contributed by Prithviraj Bose
Spark’s Resilient Distributed Datasets (the programming abstraction) are evaluated lazily and the transformations are stored as directed acyclic graphs (DAG). So every action on the RDD will make Spark recompute the DAG. This is how the resiliency is attained in Spark because if any worker node fails then the DAG just needs to be recomputed.
It is also mandatory to cache (persist with appropriate storage level) the RDD such that frequent actions on the RDD do not force Spark to recompute the DAG. Topics covered in this blog are essentially required for Apache Spark and Scala Certification. Topics covered in this blog are essentially required for Apache Spark and Scala Certification.
Why Use a Partitioner?
In cluster computing, the central challenge is to minimize network traffic. When the data is key-value oriented, partitioning becomes imperative because for subsequent transformations on the RDD, there’s a fair amount of shuffling of data across the network. If similar keys or range of keys are stored in the same partition then the shuffling is minimized and the processing becomes substantially fast.
Transformations that require shuffling of data across worker nodes greatly benefit from partitioning. Such transformations are cogroup, groupWith, join, leftOuterJoin, rightOuterJoin, groupByKey, reduceByKey, combineByKey andlookup.
Properties of Partition
- Tuples in the same partition are guaranteed to be in the same machine.
- Each node in a cluster can contain more than one partition.
- The total number of partitions are configurable, by default it is set to the total number of cores on all the executor nodes.
Types of Partitioning in Spark
Spark supports two types of partitioning,
- Hash Partitioning: Uses Java’s Object.hashCodemethod to determine the partition as partition = key.hashCode() % numPartitions.

- Range Partitioning: Uses a range to distribute to the respective partitions the keys that fall within a range. This method is suitable where there’s a natural ordering in the keys and the keys are non negative. The below code snippet shows the usage of range partitioner.
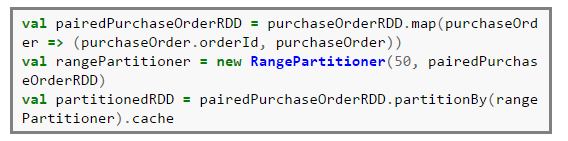
Code Example
Let’s see an example on how to partition data across worker nodes. The full Scala code is available here.
Here’s some test data of 12 coordinates (as tuples),
Create an org.apache.spark.HashPartitioner of size 2, where the keys will be partitioned across these two partitions based on the hash code of the keys.

Then we can inspect the pairs and do various key based transformations like foldByKey and reduceByKey.
Summarizing, partitioning greatly improves speed of execution for key based transformations.
Got a question for us? Please mention it in the comments section and we will get back to you.
Related Posts:
Get Started with Apache Spark and Scala
Why You Should Learn Spark After Mastering Hadoop







































What happens internally when I do the following in pyspark shell which has 2 workers ?
text = sc.parallelize ([ “I stepped on …. , …. , … ])
# some transformations
# some actions
I am new to Spark and here is my current understand : it auto-partitions the list among the workers and when an action is called these workers work in their part of the list and send them back to the driver (when collect is called).
Have I got it right ?
hey Melwin, thanks for checking out our blog. Yes, your understanding is absolutely correct. :) Please feel free to write to us if you have any more questions. Cheers!
from the doc
https://github.com/apache/spark/blob/master/core/src/main/scala/org/apache/spark/Partitioner.scala
” the number of partitions will be the same as the number of partitions in the largest upstream RDD ”
But you have mentioned that , default number of partitioner is depend up on the number of cores in all executor node..
Could you pls clarify.
Check the property spark.default.parallelism at http://spark.apache.org/docs/latest/configuration.html. spark.default.parallelism property is used for default partitioning.
Thanks for the post Prithviraj!
Your example seems a bit off:
Considering the Data -> (2, 10), (4, 3), (5, 8), (7, 10), (6, 11),
the keys should be -> 2, 4, 5, 7, 6
and when partitioned to get desired 4 partitions, the data distribution should be:
partition 1: (4, 3) because (4 % num_partitions) = 0 (assuming partition index starting at 1)
partition 2: (5, 8) because (5 % num_partitions) = 1
partition 3: (2, 10), (6, 11) because (2 % num_partitions) = 2 & 6 % num_partitions = 2
partition 4: (7, 10) because 7 % num_partitions = 3
Ritesh,
I am glad you have asked this question.
Partition ordering does not matter, basically there are 4 partitions, (4,3) will go to a partition collecting remainder 1; (2,10), (6,11) will go to a partition collecting remainder 2…like that.
How the partitions exist or ordered among themselves does not matter as long as the properties of partition are honoured. Clear?
How can key with value 4 have remainder 1 when partitions = 4? 4%4=0, no?
Ritesh, sorry for the typo. I wanted to write (4,3) will go to a partition collecting remainder 0; (5,8) will go to partition collecting remainder 1; (2,10), (6,11) will go to a partition collecting remainder 2…like that. I hope it’s clear else let me know.