





DataFrame is the pinnacle of Spark’s Technological advancements that helped to achieve multiple potentialities in Big-data environment. It is an integrated data structure that helps programmers to perform multiple operations on data with a single API. Ill line up the docket of key points for understanding the DataFrames in Spark as below.
What are DataFrames in Spark?
In simple terms, A Spark DataFrame is considered as a distributed collection of data which is organized under named columns and provides operations to filter, group, process, and aggregate the available data. DataFrames can also be used with Spark SQL. We can construct DataFrames from structured data files, RDDs, tables in Hive, or from an external database as shown below.
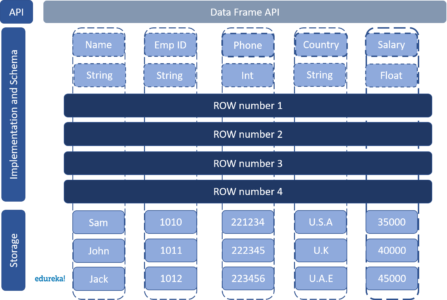
Here we have created a DataFrame about employees which has Name of the employee as string datatype, Employee-ID as string datatype, Employee phone number as an integer datatype, Employee address as a string datatype, Employee salary as a float datatype. The data of each employee is stored in each row as shown above.
Why do we need DataFrames?
DataFrames are designed to be multifunctional. We need DataFrames for:
Multiple Programming languages
- The best property of DataFrames in Spark is its support for multiple languages, which makes it easier for programmers from different programming background to use it.
- DataFrames in Spark support R–Programming Language, Python, Scala, and Java.
Multiple data sources
- DataFrames in Spark can support a large variety of sources of data. We shall discuss one by one in the use case we deal with the upcoming part of this article.
Processing Structured and Semi-Structured Data
- The core requirement for which the DataFrames are introduced is to process the Big-Data with ease. DataFrames in Spark uses a table format to store the data in a versatile way along with the schema for the data it is dealing with.
Slicing and Dicing the data
- DataFrame APIs support slicing and dicing the data. It can perform operations like select and filter upon rows, columns.
- Statistical data is always prone to have Missing values, Range Violations, and Irrelevant values. The user can manage the missing data explicitly by using DataFrames.
Now that we have understood the need for DataFrames, Let us move to the next stage where we would understand the features of DataFrames which give it an edge over other alternatives.
Features of DataFrames in Spark

- DataFrame in spark is Immutable in nature. Like the Resilient Distributed Datasets, the data present in a DataFrame cannot be altered.
- Lazy Evaluation is the key to the remarkable performance offered by the spark. DataFrames in Spark will not throw an output on to the screen unless an action operation is provoked.
- The Distributed Memory technique used to handle data makes them fault tolerant.
- Like Resilient Distributed Datasets, DataFrames in Spark extend the property of Distributed memory model.
- The only way to alter or modify the data in a DataFrame would be by applying Transformations.
So, these were the features of DataFrames, Let us now look into the sources of data for the DataFrames in Spark.
Sources for Spark DataFrame
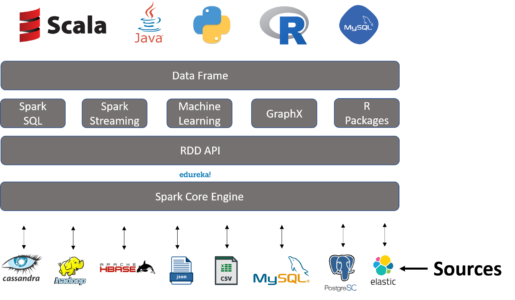
- We use multiple ways to create DataFrames in Spark.
- Data can be loaded in through a CSV, JSON, XML, SQL, RDBMS and many more.
- It can also be created using an existing RDD and through any other database, like Hive, HBase, Cassandra as well. It can also take in data from HDFS or the local file system
- Now that we have finished the theory part of DataFrames in Spark, Let us get our hands on DataFrames and execute the practical part. Creation of a DataFrame happens to be our first part.
Redefine your data analytics workflow and unleash the true potential of big data with Pyspark Course.
Creation of DataFrame in Spark
- Let us use the following code to create a new DataFrame.
- Here, we shall create a new DataFrame using the createDataFrame method.
- First, we ingest the data of all available employees into an Employee RDD.
- Later, we shall design the schema for the data we have entered into Employee RDD.
- Finally, let us use the createDataFrame method to create our DataFrame
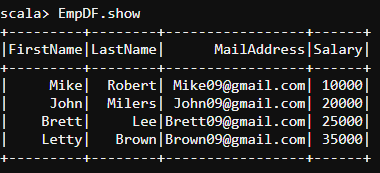
- Hence, we create DataFrame and display it by using the .show method.
val Employee = seq(Row("Mike","Robert","Mike09@gmail.com",10000),Row("John","Milers","John09@gmail.com",20000),Row("Brett","Lee","Brett09@gmail.com",25000),
Row("Letty","Brown","Brown09@gmail.com",35000))
val EmployeeSchema = List(StructField("FirstName", StringType, true), StructField("LastName", StringType, true), StructField("MailAddress", StringType, true), StructField("Salary", IntegerType, true))
val EmpDF = spark.createDataFrame(spark.sparkContext.parallelize(Employee),StructType(EmployeeSchema))
EmpDF.show
- Similarly, Let us also create Department DataFrame.
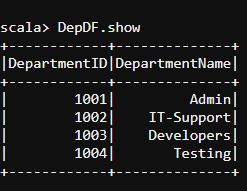
val Department = Seq(Row(1001,"Admin"),Row(1002,"IT-Support"),Row(1003,"Developers"),Row(1004,"Testing"))
val DepartmentSchema = List(StructField("DepartmentID", IntegerType, true), StructField("DepartmentName", StringType, true))
val DepDF = spark.createDataFrame(spark.sparkContext.parallelize(Department),StructType(DepartmentSchema))
DepDF.show
Spark DataFrame Example: FIFA 2k19 Dataset.

- Before we read the data from a CSV file, We need to import certain libraries which we need for processing the DataFrames in Spark.
import org.apache.spark.sql.types._ import org.apache.spark.storage.StorageLevel import scala.io.Source import scala.collection.mutable.HashMap import java.io.File import org.apache.spark.sql.Row import org.apache.spark.sql.types._ import scala.collection.mutable.ListBuffer import org.apache.spark.util.IntParam import org.apache.spark.rdd.RDD import org.apache.spark.SparkContext import org.apache.spark.SparkContext._ import org.apache.spark.SparkConf import org.apache.spark.sql.SQLContext import org.apache.spark.rdd._ val sqlContext = new org.apache.spark.sql.SQLContext(sc) import sqlContext.implicits._ import sqlContext._
- We design the schema for our CSV file once we import libraries,
val schema = StructType(Array(StructField("ID", IntegerType, true),StructField("Name", StringType, true),StructField("Age", IntegerType, true),StructField("
Nationality", StringType, true),StructField("Potential", IntegerType, true),StructField("Club", StringType, true),StructField("Value", StringType, true),StructFiel
d("Preferred Foot", StringType, true),StructField("International Reputation", IntegerType, true),StructField("Skill Moves", IntegerType, true),StructField("Positio
n", StringType, true),StructField("Jersey Number", IntegerType, true),StructField("Crossing", IntegerType, true),StructField("Finishing", IntegerType, true),Struct
Field("HeadingAccuracy", IntegerType, true),StructField("ShortPassing", IntegerType, true),StructField("Volleys", IntegerType, true),StructField("Dribbling", Integ
erType, true),StructField("Curve", IntegerType, true),StructField("FKAccuracy", IntegerType, true),StructField("LongPassing", IntegerType, true),StructField("BallC
ontrol", IntegerType, true),StructField("Acceleration", IntegerType, true),StructField("SprintSpeed", IntegerType, true),StructField("Agility", IntegerType, true),
StructField("Balance", IntegerType, true),StructField("ShotPower", IntegerType, true),StructField("Jumping", IntegerType, true),StructField("Stamina", IntegerType,
true)))

- Let us load the Fifa data from a CSV file from the HDFS as shown below. We are first going to use Spark.read.format(“csv”) method for reading our CSV file from our HDFS.
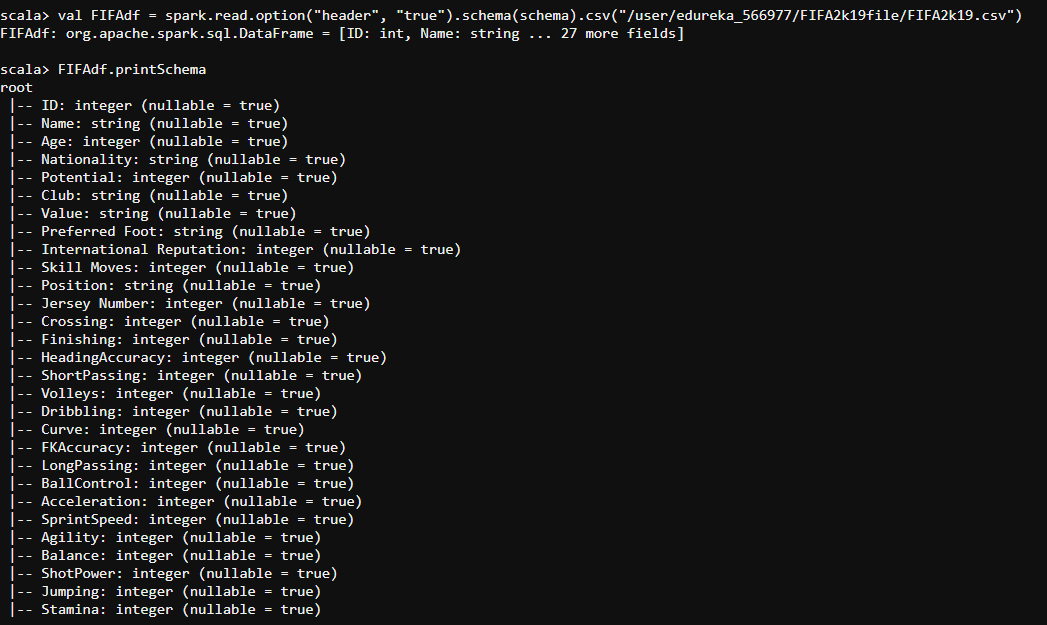
val FIFAdf = spark.read.format("csv").option("header", true").load("/user/edureka_566977/FIFA2k19file/FIFA2k19.csv")
- Let us use .printSchema() method to see the schema of our CSV file.
FIFAdf.printSchema()
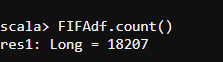
- Let us find out the total number of rows we have using the following code.
#count FIFAdf.count()
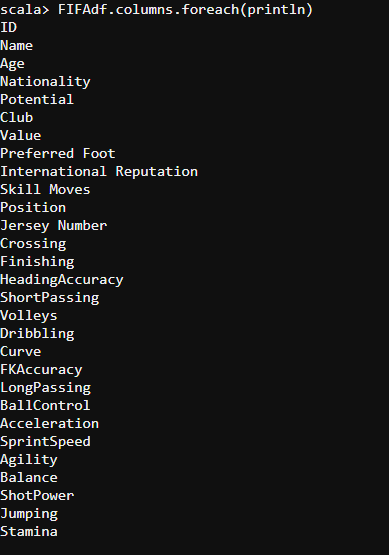
- Let us now find the columns we have in our CSV file. We shall use the following code.
FIFAdf.columns.foreach(println)
- If you wish to look at the summary of a particular column in a DataFrame, we can apply to describe command. This command will give us the statistical summary of a particular selected column if nothing is specified, then it provides the statistical information of the DataFrame.
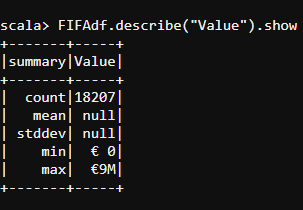
- Let us find out the description of the Value column to know the minimum and maximum values present in it.
#describe
FIFAdf.describe("Value").show
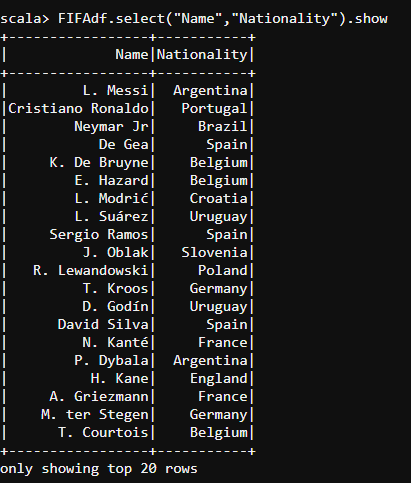
- We shall find out the Nationality of a particular player by using the select command.
#select
FIFAdf.select("Name","Nationality").show
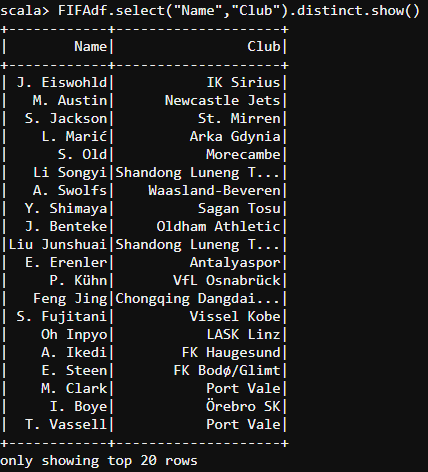
- Let us find out the names of the players and their particular Clubs by using the select and distinct operations.
#select and distinct
FIFAdf.select("Name","Club").distinct.show()
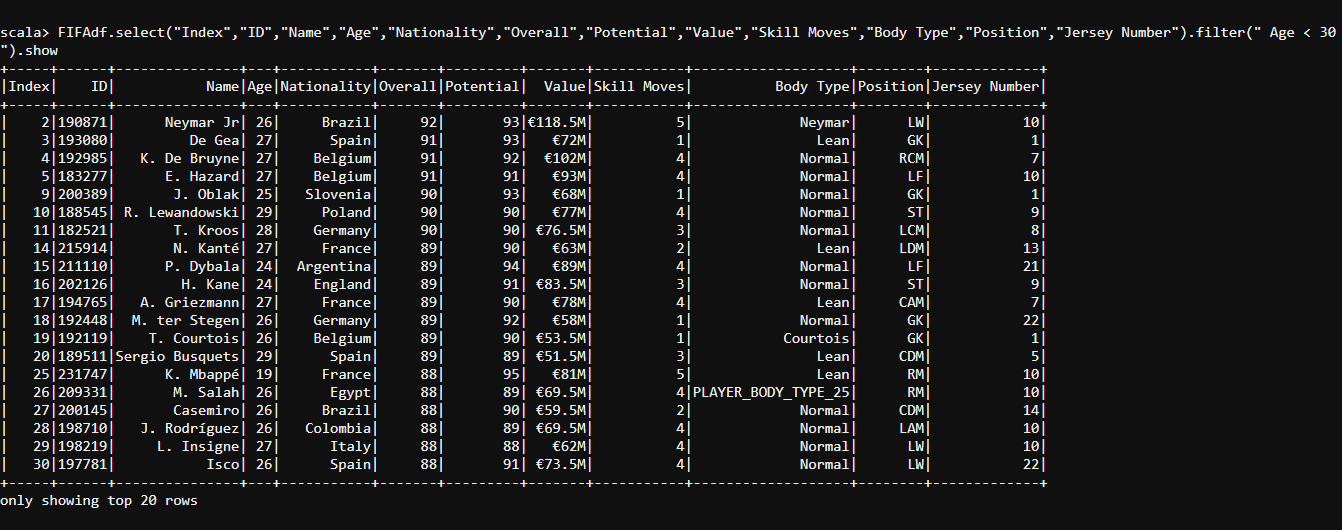
- We shall find out the players under 30 years of age and extract all their details about Player-ID, Nationality, Overall, Potential, Value, Skill Moves, Body Type, Position and Player Jersey Number.
#select and filter
FIFAdf.select("Index","ID","Name","Age","Nationality","Overall","Potential","Value","Skill Moves","Body Type","Position","Jersey Number").filter(" Age < 30 ").show
So, this was about the FIFA 2019 dataset example that we dealt with, Now let me walk you through a use case which will help you learn more about DataFrames in spark with the most trending topic which is none other than “The Game of Thrones”
DataFrames in Spark: Game of Thrones Use Case

- We need to import certain libraries which we need for processing the DataFrames in Spark as we did in our previous example and load our Game of Thrones CSV file.
Now we have successfully loaded all the libraries we needed for processing our DataFrames in Spark.
- First, we shall design the schema for Character-Deaths.csv file as shown below.
val schema = StructType(Array(StructField("Name", StringType, true), StructField("Allegiances", StringType, true), StructField("Death Year", IntegerType, tr
ue), StructField("Book of Death", IntegerType, true), StructField("Death Chapter", IntegerType, true), StructField("Book Intro Chapter", IntegerType, true), Struct
Field("Gender", IntegerType, true), StructField("Nobility", IntegerType, true), StructField("GoT", IntegerType, true), StructField("CoK", IntegerType, true), Struc
tField("SoS", IntegerType, true), StructField("FfC", IntegerType, true), StructField("DwD", IntegerType, true)))

- Next, we shall design the schema for the Battles.csv file as shown below:
val schema2 = StructType(Array(StructField("name", StringType, true), StructField("year", IntegerType, true), StructField("battle_number", IntegerType, true
), StructField("attacker_king", StringType, true), StructField("defender_king", StringType, true), StructField("attacker_1", StringType, true), StructField("attack
er_2", StringType, true), StructField("attacker_3", StringType, true), StructField("attacker_4", StringType, true), StructField("defender_1", StringType, true), St
ructField("defender_2", StringType, true), StructField("defender_3", StringType, true), StructField("defender_4", StringType, true), StructField("attacker_outcome"
, StringType, true), StructField("battle_type", StringType, true), StructField("major_death", StringType, true), StructField("major_capture", IntegerType, true), S
tructField("attacker_size", IntegerType, true), StructField("defender_size", IntegerType, true), StructField("attacker_commander", StringType, true), StructField("
defender_commander", StringType, true), StructField("summer", IntegerType, true), StructField("location", StringType, true), StructField("region", StringType, true
), StructField("note", StringType, true)))

- Once after we design the schema successfully for our CSV files, the next step would be loading them on to the Spark-Shell. The following code will help us to load the CSV files on to the Spark-Shell.
val GOTdf = spark.read.option("header", "true").schema(schema).csv("/user/edureka_566977/GOT/character-deaths.csv")
val GOTbattlesdf = spark.read.option("header", "true").schema(schema2).csv("/user/edureka_566977/GOT/battles.csv")

- Once we load the csv file on to the Spark-Shell, we can print the schema of our CSV files that we can cross verify our design on our data. The following codes will help us to print our schema.
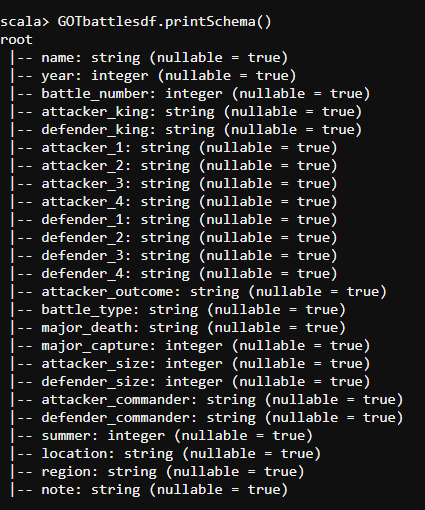
GOTdf.printSchema()
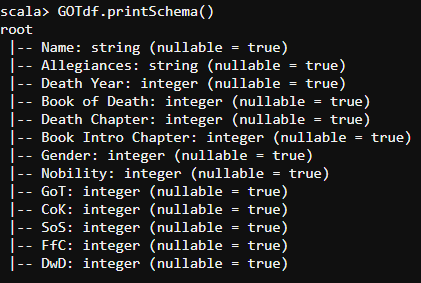
GOTbattlesdf.printSchema()
After verifying the schema, let us print the data present in our DataFrame. We can use the following code to print the data present in our DataFrame.
#select
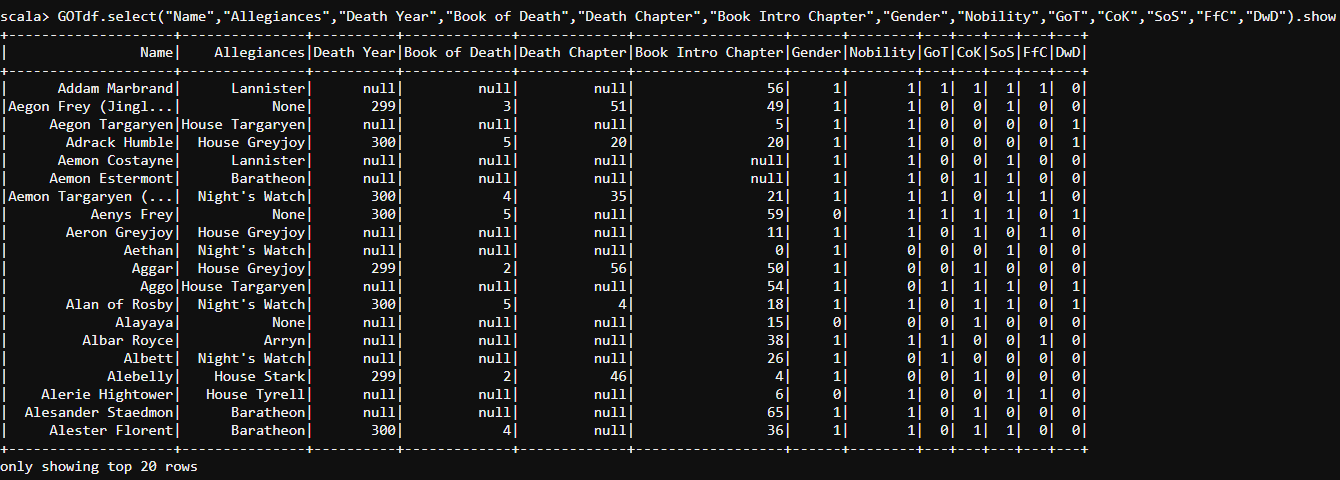
GOTdf.select("Name","Allegiances","Death Year","Book of Death","Death Chapter","Book Intro Chapter","Gender","Nobility","GoT","CoK","SoS","FfC","DwD").show
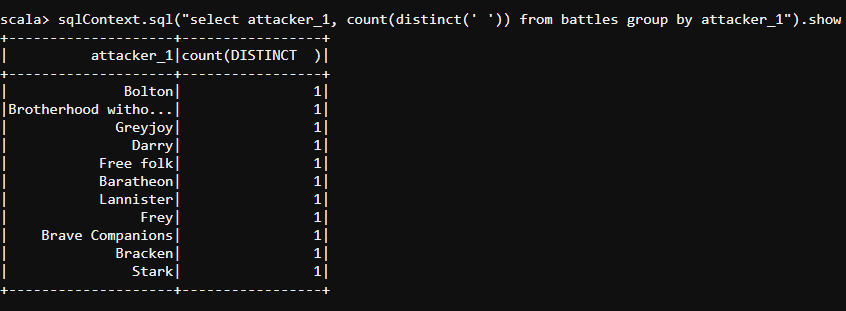
- We know that there are a different number of houses in Game of Thrones. Let us find out every individual house present in our DataFrame.
#select and groupBy
sqlContext.sql("select attacker_1, count(distinct(' ')) from battles group by attacker_1").show
- The battles in Game of Thrones were fought for ages. Let us classify the wars waged with their occurrence according to the year in which they were fought using select and filter transformation by accessing the columns of the details of the battle and the year column. The code below will help us to do so.
- Let us find the battles fought in the year 298using the code below:
#select and filter
GOTbattlesdf.select("name","year","battle_number","attacker_king","defender_king","attacker_outcome","attacker_commander","defender_commander","location").filter("year == 298").show

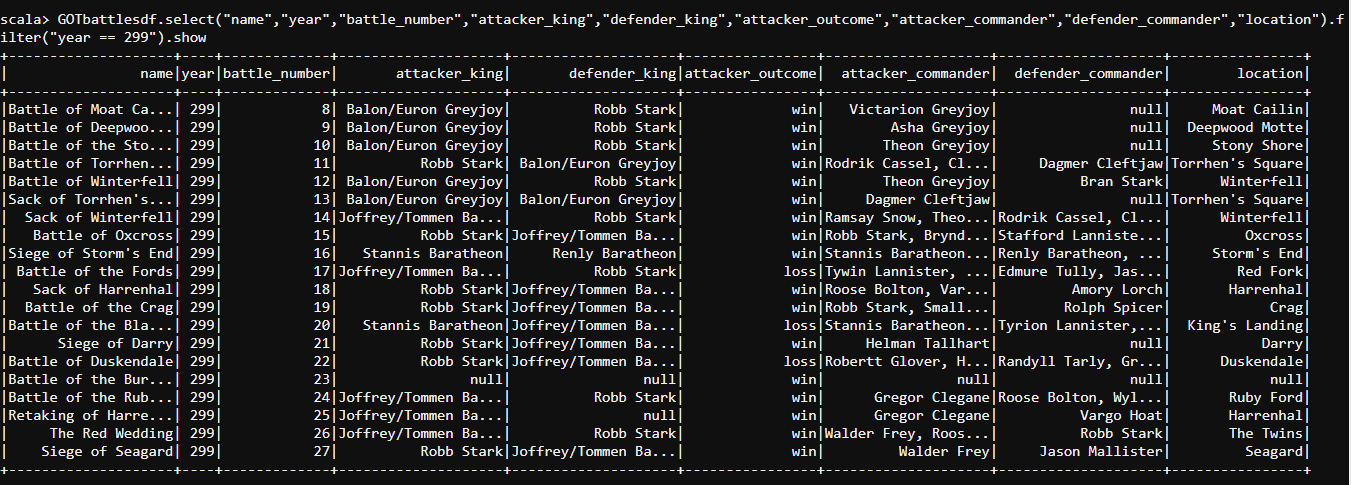
- Let us find the battles fought in the year 299 using the code below:
#select
GOTbattlesdf.select("name","year","battle_number","attacker_king","defender_king","attacker_outcome","attacker_commander","defender_commander","location").filter("year == 299").show
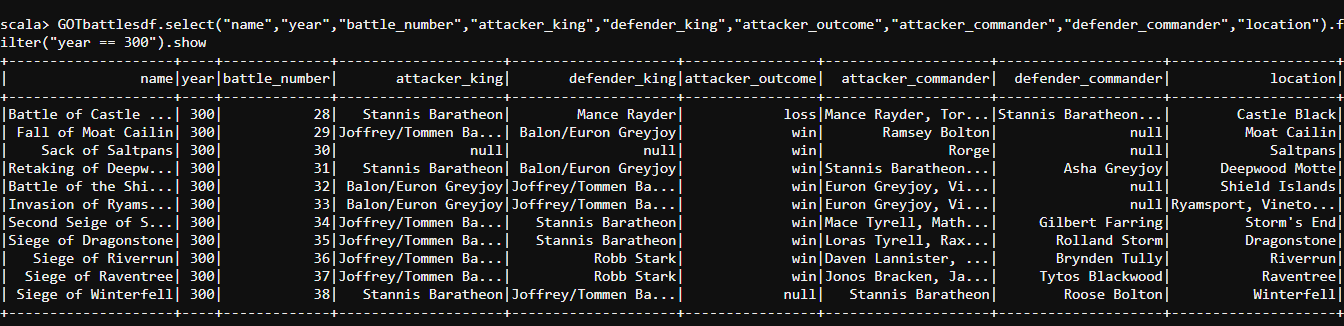
- Let us find the battles fought in the year 300 using the code below:
#select and filter
GOTbattlesdf.select("name","year","battle_number","attacker_king","defender_king","attacker_outcome","attacker_commander","defender_commander","location").filter("year == 300").show
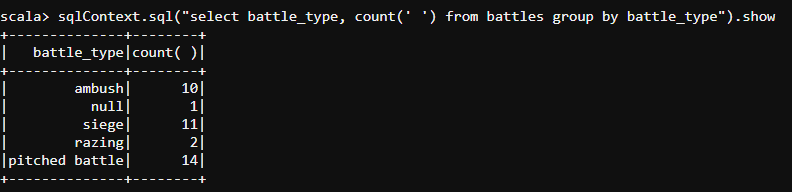
- Now let us find out the tactics used in the wars waged and also find out the total number of wars waged by using each one of those tactics.
#groupBy
sqlContext.sql("select battle_type, count(' ') from battles group by battle_type").show
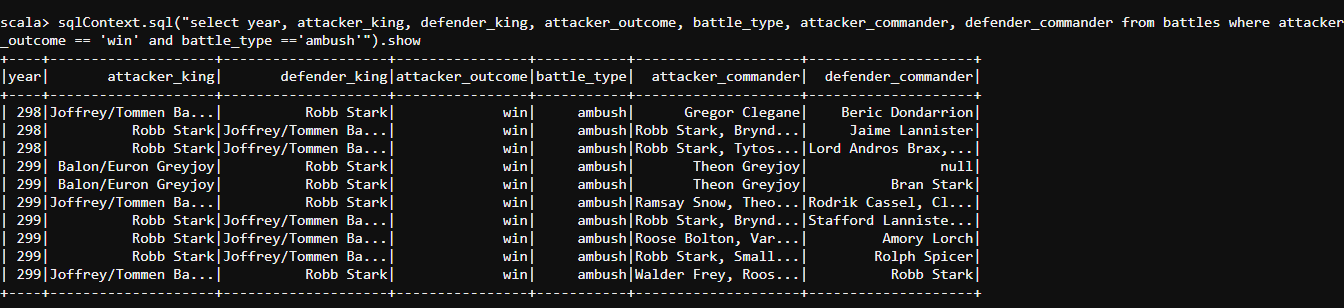
- The ambush type of battles is deadliest ones, here the enemy would never have any clue of an attack. Let us find out the details of the years where which of the kings waged an ambush type of battle against whom and with the details of the commanders of both the kingdoms and the outcome of the attacker.
- The following code must help us find these details.
#and
sqlContext.sql("select year, attacker_king, defender_king, attacker_outcome, battle_type, attacker_commander, defender_commander from battles where attacker_outcome == 'win' and battle_type =='ambush'").show
- Let us now focus on the houses and extract the deadliest house amongst the rest. The code below will help us find out the house details and the battles they waged.
#groupBy
sqlContext.sql("select attacker_1, count(' ') from battles group by attacker_1").show
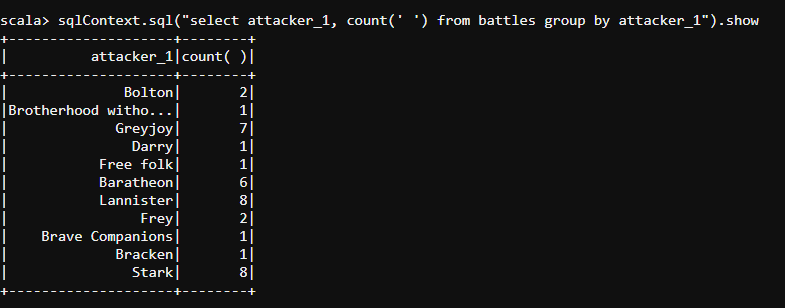
- Now, we shall find out the details of the kings and the total number of battles they fought to visualize the king with highest battles fought.
#select
sqlContext.sql("select attacker_king, count(' ') from battles group by attacker_king").show
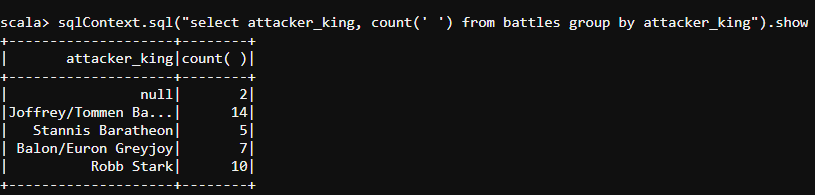
- Let us find out the houses which are successful in defending the battles which are against them along with the total number of wars they have to defend their kingdom from. The following code must help us to find those details.
#count
sqlContext.sql("select defender_1, count(' ') from battles group by defender_1").show
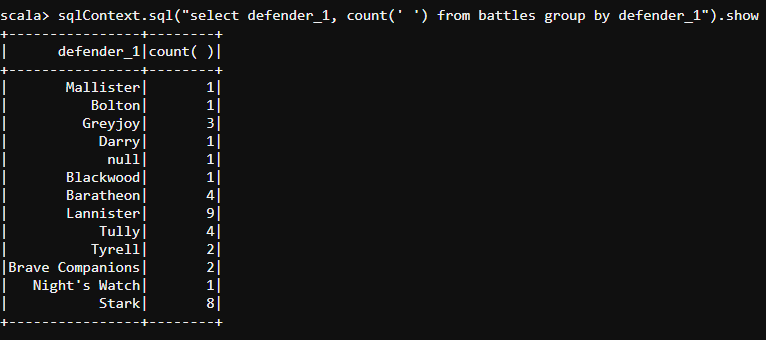
- Let us find out the details of the kings and the number of wars they successfully defended their kingdoms from their enemies. The following code can extract those details.
#groupBy
sqlContext.sql("select defender_king, count(' ') from battles group by defender_king").show
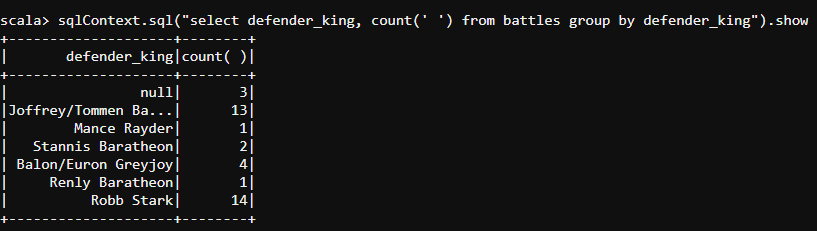
- Since Lannister house is my personal favorite, let me find out the details of the characters in Lannister house which will describe their name and gender(1 -> male, 0 -> female) along with their respective population. The code below will fetch us the details of all the male characters we have in Lannister house.
#select
val df1 = sqlContext.sql("select Name, Allegiances, Gender from deaths where Allegiances == 'Lannister' and Gender == '1'")
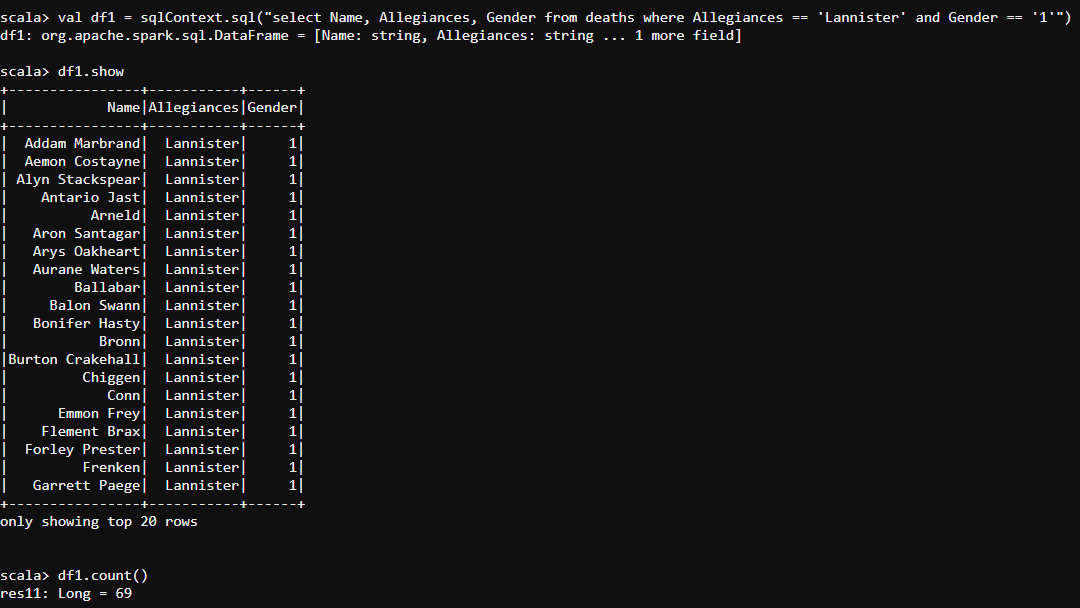
- The code below will fetch us the details of all the female characters we have in Lannister house.
#Select
val df2 = sqlContext.sql("select Name, Allegiances, Gender from deaths where Allegiances == 'Lannister' and Gender == '0'")
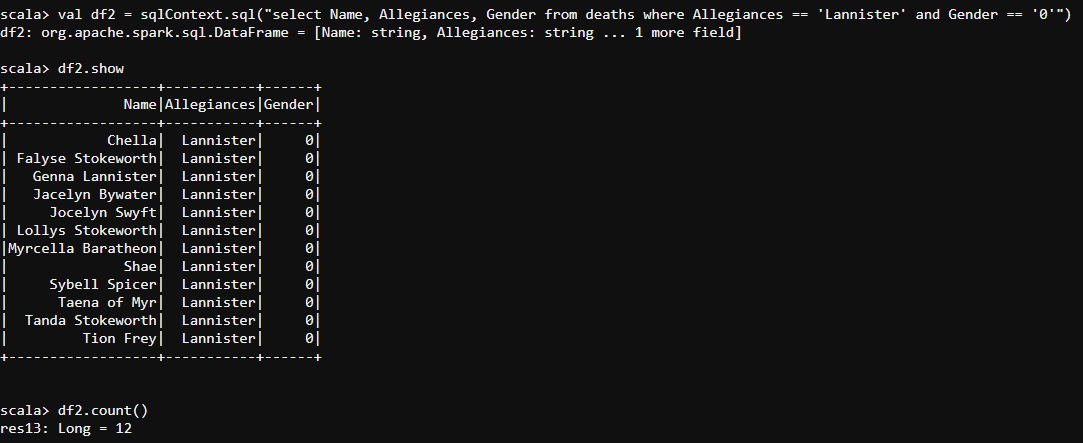
- At the end of the day, Every episode of the game of thrones had a noble character. Let us now find out all the noble characters amongst all the houses we have in our GameOfThrones.csv file.
#where
val df4 = sqlContext.sql("select Name, Allegiances, Gender from deaths where Nobility == '1'")
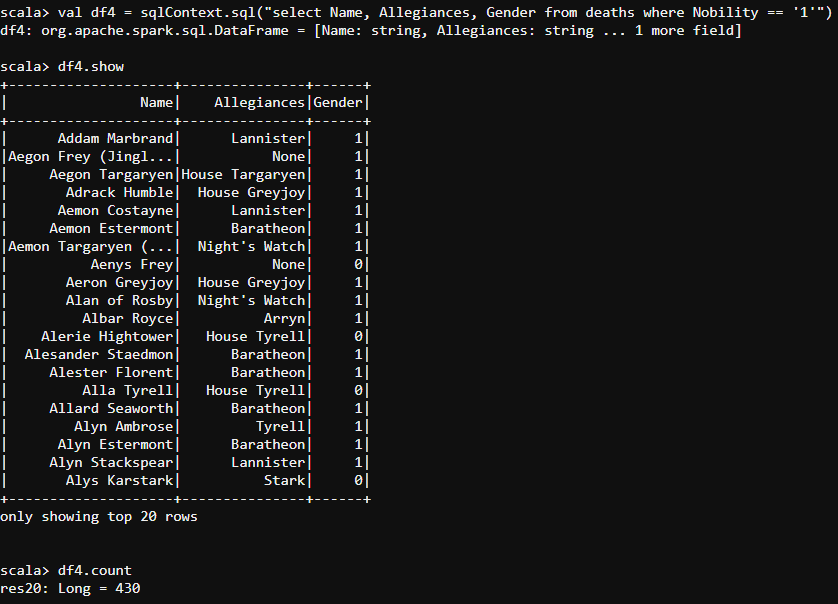
- None the less, there are some commoners whose role in the Game Of Thrones is exceptional. Let us find out the details of the commoners who are highly inspirational in each episode.
#select and where
val df5 = sqlContext.sql("select Name, Allegiances, Gender from deaths where Nobility == '0'")
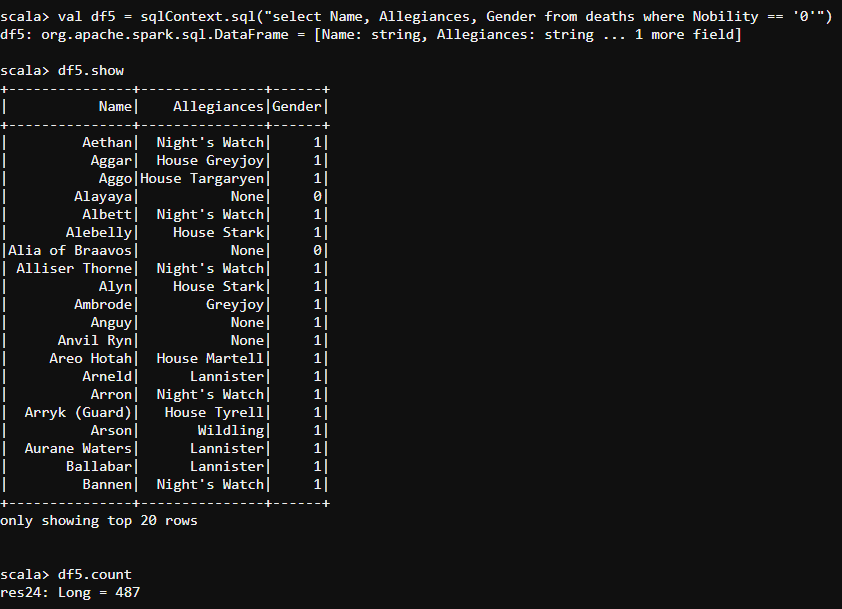
- We consider a few roles as important and equally noble. let the writer carry out the characters until the last book. Let us filter out those characters to find the details of each one of them.
#and
val df6 = sqlContext.sql("select Name, Allegiances, Gender from deaths where GoT == '1' and Cok == '1' and SoS == '1' and FfC == '1' and DwD == '1' and Nobility == '1'")
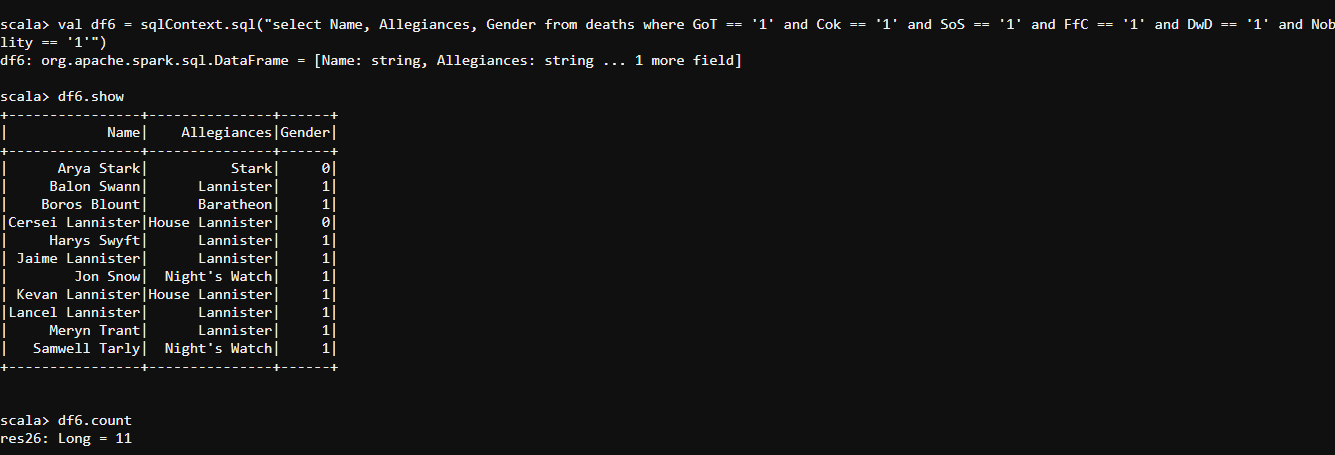
- Amongst all the battles, I found the battles of the last books to be generating more adrenaline in the readers.
- Let us find out the details of those final battles by using the following code.
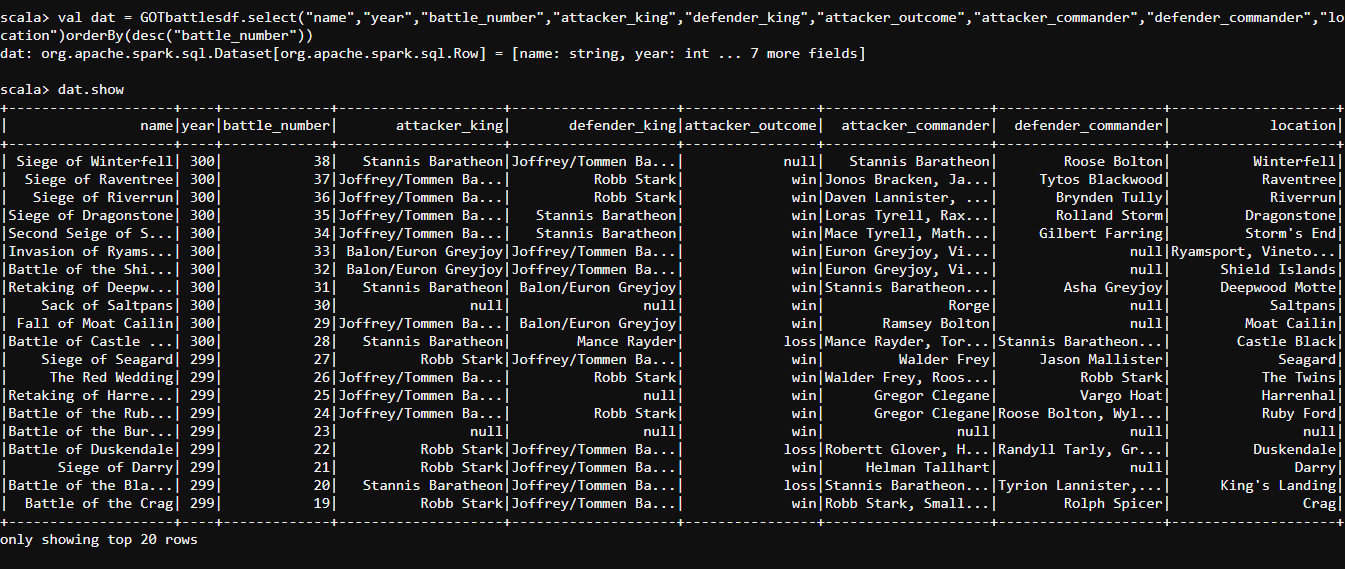
#OrderBy
val dat = GOTbattlesdf.select("name","year","battle_number","attacker_king","defender_king","attacker_outcome","attacker_commander","defender_commander","location")orderBy(desc("battle_number"))
dat.show
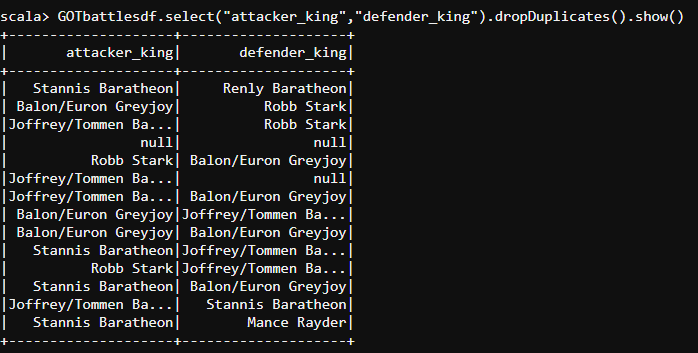
- Let us use the following code to drop down all the duplicate details we have about the attacker kings and their respective kings in the final battles fought.
#DropDuplicates
GOTbattlesdf.select("attacker_king","defender_king").dropDuplicates().show()
So, with this, we come to an end of this DataFrames in Spark article. I hope we sparked a little light upon your knowledge about DataFrames, their features and the various types of operations that can be performed on them.
This article based on Apache Spark and Scala Certification Training is designed to prepare you for the Cloudera Hadoop and Spark Developer Certification Exam (CCA175). You will get in-depth knowledge on Apache Spark and the Spark Ecosystem, which includes Spark DataFrames, Spark SQL, Spark MLlib and Spark Streaming. You will get comprehensive knowledge on Scala Programming language, HDFS, Sqoop, Flume, Spark GraphX and Messaging System such as Kafka.





































