
Data Science with Python Certification Course
- 132k Enrolled Learners
- Weekend
- Live Class
(49300)





 Copy Link!
Copy Link!_1648290501.jpg)
Machine Learning and Data Science are the most significant domains in today’s world. All the sci-fi stuff that you see happening in the world is a contribution from fields like Data Science, Artificial Intelligence (AI) and Machine Learning. In this blog on Data Science vs Machine Learning, we’ll discuss the importance and the distinction between Machine Learning and Data Science.
I’ll be covering the following topics in this Data Science vs Machine learning blog:
What Is Data Science?
Before we get into the details of Data Science, let’s understand how data science came into existence. Do you guys remember when most of the data was stored in Excel sheets? They were simpler times because we generated lesser data and the data was structured. Back then simple Business Intelligence (BI) tools were used to analyze and process the data.
But times have changed. Over 2.5 quintillion bytes of data is created every single day, and this number is only going to grow. By 2020, it’s estimated that 1.7MB of data will be created every second for every person on earth. Can you imagine how much data that is? How are we going to process this much data?

What Is Data Science – Data Science vs Machine Learning – Edureka
Not only that, the data generated these days is mostly unstructured or semi-structured and simple BI tools cannot do the work anymore. We need more complex and effective algorithms to process and extract useful insights from the data. This is where Data science comes in.
For example, surely you have binged watched on Netflix. Netflix data mines movie viewing patterns of its users to understand what drives user interest and uses that to make decisions on which Netflix series to produce.
Similarly, Target identifies each customer’s shopping behavior by drawing out patterns from their database, this helps them make better marketing decisions.
Now that you know why Data Science is important, let’s move ahead and discuss what Machine Learning is.
The idea behind Machine Learning is that you teach machines by feeding them data and letting them learn on their own, without any human intervention. To understand Machine Learning, let’s consider a small scenario.
Let’s say that you’ve enrolled for skating classes and you have no prior experience of skating. Initially, you’d be pretty bad at it because you have no idea about how to skate. But as you observe and pick up more information, you get better. Observing is just another way of collecting data.
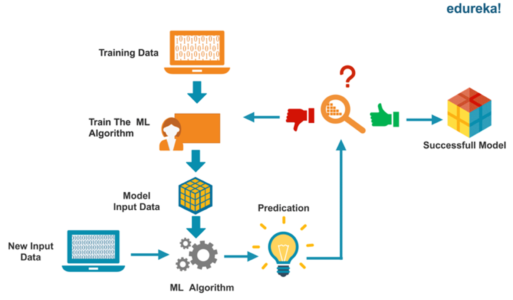 What Is Machine Learning – Data Science vs Machine Learning – Edureka
What Is Machine Learning – Data Science vs Machine Learning – Edureka
Just like how we humans learn from our observations and experience, machines are also capable of learning on their own when they’re fed a good amount of data. This is exactly how Machine Learning works.
Machine Learning begins with reading and observing the training data to find useful insights and patterns in order to build a model that predicts the correct outcome. The performance of the model is then evaluated by using the testing data set. This process is carried out until, the machine automatically learns and maps the input to the correct output, without any human intervention.
I hope you have an idea about what Machine Learning is if you wish to learn more about Machine Learning, check out this video by our Machine Learning experts.
This video gives an introduction to Machine Learning and its various types.
Before we do the Data Science vs Machine Learning comparison, let’s try to understand the different fields covered under Data Science.
Data Science covers a wide spectrum of domains, including Artificial Intelligence (AI), Machine Learning and Deep Learning. Data Science uses various AI, Machine Learning and Deep Learning methodologies in order to analyse data and extract useful insights from it. To make things clearer, let me define these terms for you:
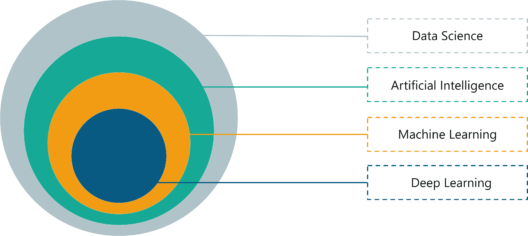
Fields Of Data Science – Data Science vs Machine Learning – Edureka
To conclude, Data Science involves the extraction of knowledge from data. In order to do so, it uses a bunch of different methods from various disciplines, like Machine Learning, AI and Deep Learning. A point to note here is that Data Science is a wider field and does not exclusively rely on these techniques.
Transform yourself into a highly skilled professional and land a high-paying job with the Artificial Intelligence Course.
Now that you have a clear distinction between AI, Machine Learning and Deep Learning, let’s discuss a use case wherein we’ll see how Data Science and Machine Learning is used in the working of recommendation engines.
Before we discuss how Machine learning and Data Science is implemented in a Recommendation system, let’s see what exactly a Recommendation engine is.
Surely, you all have used Amazon for online shopping. Have you noticed that when you look for a particular item on Amazon, you get recommendations for similar products? Well, how does Amazon know this?
The reason why companies like Amazon, Walmart, Netflix, etc are doing so well is because of how they handle user-generated data.
A recommendation system narrows down a list of choices for each user, based on their browsing history, ratings, profile details, transaction details, cart details and so on. Such a system provides useful insights about customers shopping patterns.
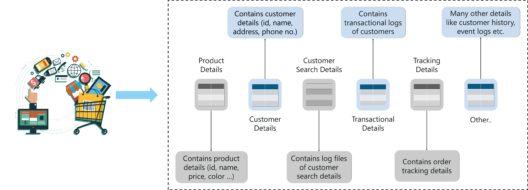
Recommendation Engine – Data Science vs Machine Learning – Edureka
Each user is given a personalized view of the eCommerce website based on his/her profile and this allows them to select relevant products. For example, if you’re looking for a new laptop on Amazon, you might also want to buy a laptop bag. Based on such associations, Amazon will recommend more products to you.
Enroll for the Data Science Post Graduate program by Edureka to elevate your career.
Moving ahead, let’s discuss how Data Science and Machine learning are used in a Recommendation engine.
A Data Science workflow has six well defined stages:
Step 1: Business Requirements
A Data Science project always starts with defining the Business requirements. It is important that you understand the problem you are trying to solve. The main focus of this stage is to identify the different goals of your project.
In our case, the objective is to build a recommendation engine that will suggest relevant items to each customer based on the data generated by them.
Step 2: Data Acquisition
Now that you’ve defined the objectives of your project, it’s time to start collecting the data. Data can be gathered from different sources, such as explicit sources and implicit sources:
Collecting such data is easy because the users don’t have to do any extra work because they’re already using the application.
Since each user is bound to have a different opinion about a product, their data sets will be distinct.
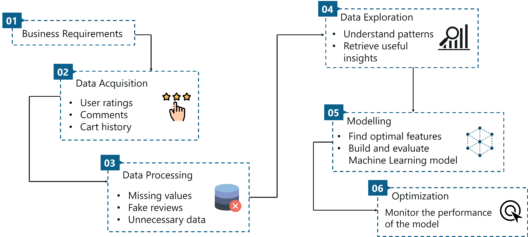
Data Science Process – Data Science vs Machine Learning – Edureka
Step 3: Data Wrangling (Cleaning)
A research was conducted, where a couple of Data Scientists were interviewed about their experience. Majority of them agreed that 50 to 80 percent of their time was spent in cleaning the data. Data cleaning is considered to be one of the most time-consuming tasks in Data Science.
Data cleaning is the process of removing unrelated and inconsistent data. At this stage you must convert your data into a desired format so that your Machine learning model can interpret it. It is necessary to get rid of any inconsistencies as they might result in inaccurate outcomes.
For example, filtering the significant logs from the less significant ones, identifying fake reviews, removing unnecessary comments, missing values, etc. Such issues are dealt with in this stage.
Step 4: Data Exploration
Data Exploration involves understanding the patterns in the data and retrieving useful insights from it. At this stage, each customer’s shopping pattern is evaluated so that relevant products can be suggested to them.
For example, if you’re looking to buy the Harry Potter Book series on Amazon, there is a possibility that you might also want to buy The Lord of the Rings or similar books that fall into the same genre. Therefore, Amazon recommends similar books to you.
Henceforth, as you provide the engine more data, it gets better with its recommendations.
Step 5: Data Modelling
As mentioned earlier, Machine Learning is a part of Data Science and at this stage in our data cycle, Machine Learning is implemented. Machine Learning can also be a part of Data exploration or visualization if needed, but this stage is specifically for building a Machine learning model.
In order to understand Data modelling, lets break down the process of Machine learning.
Machine Learning is carried out in 5 distinctive stages:
Importing Data: At this stage, the data that was gathered is imported for the machine learning process. The data must be in a readable format, such as a CSV file or a table.
Data Cleaning: Data can have multiple duplicate values, missing values or N/A values. Such inconsistencies in the data can cause wrongful predictions and must be dealt with in this stage.
Creating a Model: This stage involves splitting the data set into 2 sets, one for training and the other for testing. After which you must build the model by using the training dataset. The models are built using Machine Learning algorithms like Logistic Regression, Linear Regression, Random Forest, Support Vector Machine and so on.
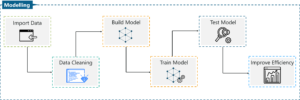
Machine Learning Process – Data Science vs Machine Learning – Edureka
Model training: At this stage, the machine learning model is trained on the training data set. A large portion of the data set is used for training so that the model can learn to map the input to the output, on a set of varied values.
Model Testing: After the model is trained, it is then evaluated by using the testing data set. At this stage, the model is fed new data points and it must predict the outcome by running the new data points on the Machine learning model that was built earlier.
Improve the Model: After the model is evaluated using the testing data, its accuracy is calculated. There is n number of ways in which the model’s efficiency can be improved. Methods such as cross validation are used to make the model more accurate.
So, that was all about the Machine Learning process. Coming to the last stage of the data life cycle.
Step 6: Deployment & Optimization
The goal of this stage is to deploy the final model onto a production environment for final user acceptance. At this stage, users must validate the performance of the models and if there are any issues with the model then they must be fixed in this stage.
Before I end this blog, I want to conclude that Data Science and Machine Learning are interconnected fields and since Machine Learning is a part of Data Science, there isn’t much comparison between them. ML makes computers learn the data and making own decisions and using in multiple industries. It resolves the complex problem very easily and makes well-planned management. Our MLOps Certification course provides certain skills to streamline this process, ensuring scalable and robust machine learning operations.
Machine Learning aids Data Science by providing a set of algorithms for data exploration, data modelling, decision making, etc. On the other hand, Data Science binds together, a set of Machine Learning algorithms to predict the outcome.
With this, we come to the end of this blog on Data Science vs Machine Learning. If you have any queries regarding this topic, please comment down below.
To get in-depth knowledge of Data Science, you can enroll for live Python for Data Science Course Training by Edureka with 24/7 support and lifetime access.
Also, If you are looking for online structured training in Data Science, edureka! has a specially curated Data Scientist Course that helps you gain expertise in Statistics, Data Wrangling, Exploratory Data Analysis, and Machine Learning Algorithms like K-Means Clustering, Decision Trees, Random Forest, Naive Bayes. You’ll learn the concepts of Time Series, Text Mining, and an introduction to Deep Learning as well. New batches for this course are starting soon!!



































 Thank you for registering Join Edureka Meetup community for 100+ Free Webinars each month JOIN MEETUP GROUP
Thank you for registering Join Edureka Meetup community for 100+ Free Webinars each month JOIN MEETUP GROUP
impressive article