
Data Science with Python Certification Course
- 131k Enrolled Learners
- Weekend
- Live Class
(49300)





 Copy Link!
Copy Link!_1648290501.jpg)
Want to start your career as a Data Scientist, but don’t know where to start? You are at the right place! Hey Guys, welcome to this awesome Data Science Tutorial blog, it will give you a kick start into data science world.
It’s been said that Data Scientist is the “Sexiest Job of the 21st century”. Why? Because over the past few years, companies have been storing their data. And this being done by each and every company, it has suddenly led to data explosion. Data has become the most abundant thing today.
But, what will you do with this data? Let’s understand this using an example:
Say, you have a company which makes mobile phones. You released your first product, and it became a massive hit. Every technology has a life, right? So, now its time to come up with something new. But you don’t know what should be innovated, so as to meet the expectations of the users, who are eagerly waiting for your next release?
Somebody, in your company comes up with an idea of using the user-generated feedback and pick things which we feel users are expecting in the next release.
You can even check out the details of successful Spark developer with the Pyspark online course.
Comes in Data Science, you apply various data mining techniques like sentiment analysis etc and get the desired results.
It’s not only this, you can make better decisions, you can reduce your production costs by coming out with efficient ways, and give your customers what they actually want!
With this, there are countless benefits that Data Science can result in, and hence it has become absolutely necessary for your company to have a Data Science Team. Requirements like these led to “Data Science” as a subject today, and hence we are writing this blog on Data Science Tutorial for you. :)
The term Data Science has emerged recently with the evolution of mathematical statistics and data analysis. The journey has been amazing, we have accomplished so much today in the field of Data Science.
In the next few years, we will be able to predict the future as claimed by researchers from MIT. They already have reached a milestone in predicting the future, with their awesome research. They can now predict what will happen in the next scene of a movie, with their machine! How? Well it might be a little complex for you to understand as of now, but don’t worry by the end of this blog, you shall have an answer to that as well.
Coming back, we were talking about Data Science, it is also known as data driven science, which makes use of scientific methods, processes and systems to extract knowledge or insights from data in various forms, i.e either structured or unstructured.
What are these methods and processes, is what we are going to discuss in this Data Science Tutorial today.
Moving forward, who does all this brain storming, or who practices Data Science? A Data Scientist.
Enroll for Data Science Course, a Masters program by Edureka to elevate your career.
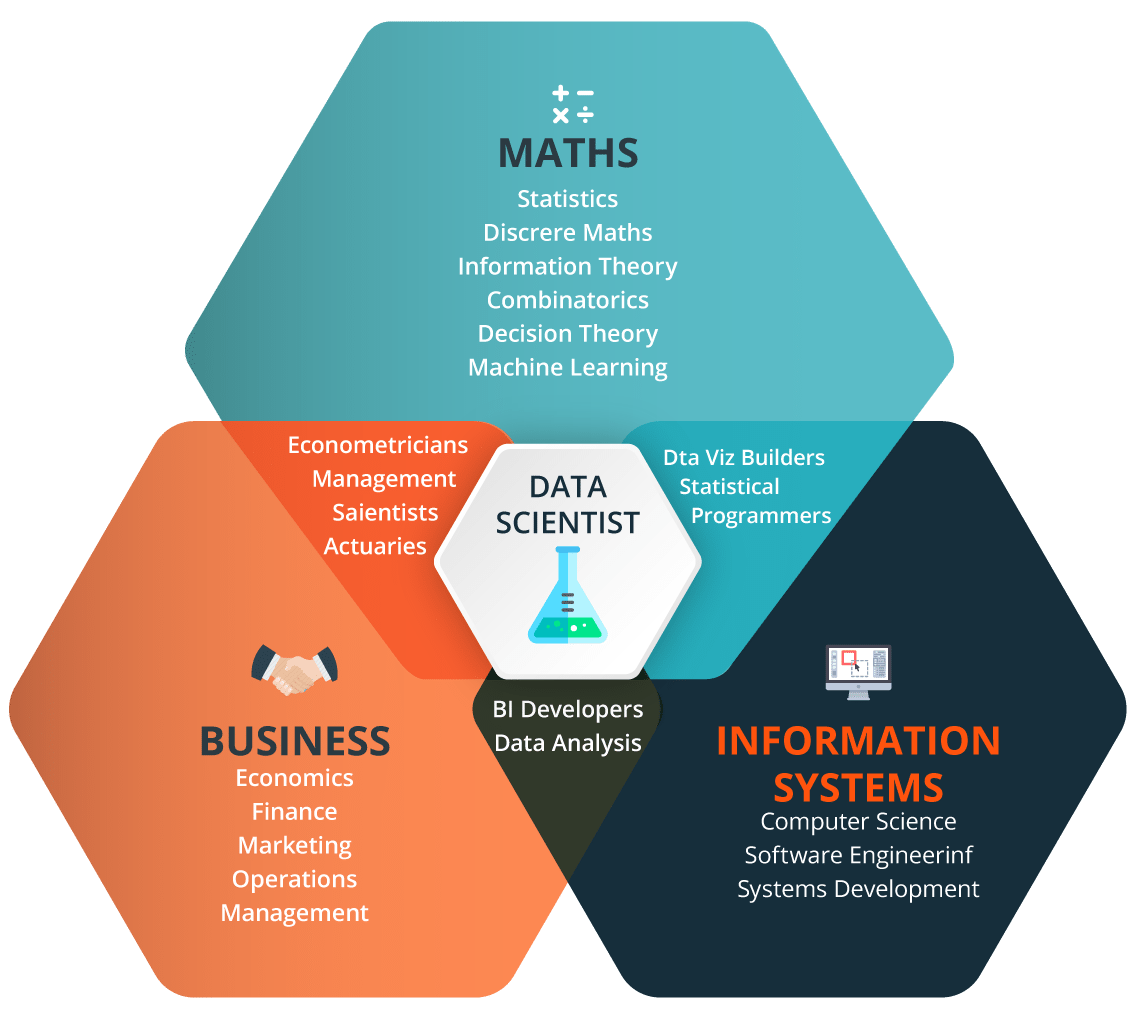

As you can see in the image, a Data Scientist is the master of all trades! He should be proficient in maths, he should be acing the Business field, and should have great Computer Science skills as well. Scared? Don’t be. Though you need to be good in all these fields, but even if you aren’t, you’re not alone! There is no such thing as “a complete data scientist”. If we talk about working in a corporate environment, the work is distributed among teams, wherein each team has their own expertise. But the thing is, you should be proficient in atleast one of these fields. Also, even if these skills are new to you, chill! It may take time, but these skills can be developed, and believe me it would be worth the time you will be investing. Why? Well, let’s look at the job trends.
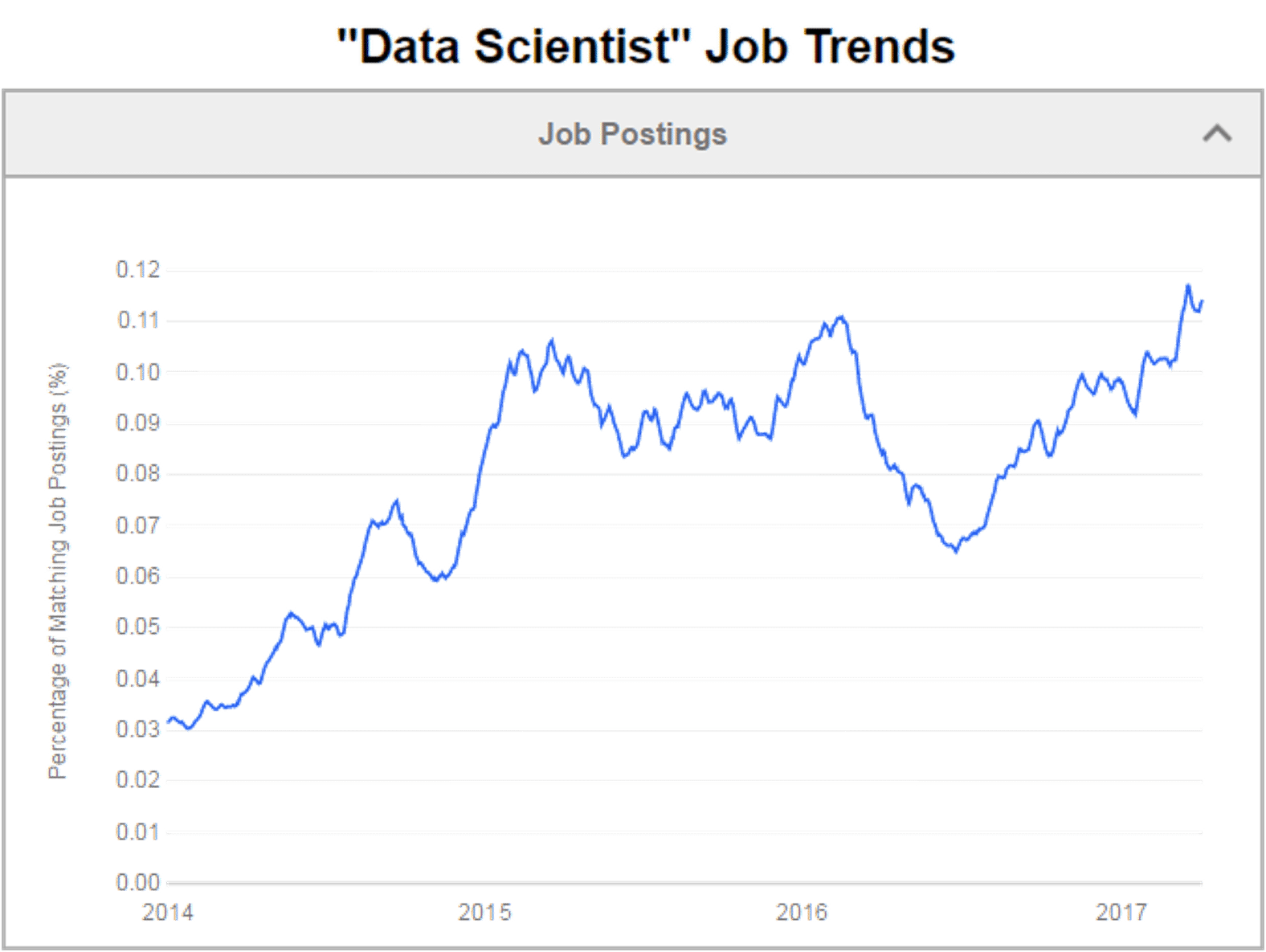
Well, the graph says it all, not only there are lot of job openings for a data scientist, but the jobs are well-paid too! And no, our blog will not cover the salary figures, go google!
Well, we now know, learning data science actually makes sense, not only because it is very useful, but also you have a great career in it in the near future.
Let’s start our journey in learning data science now and begin with,
Business Analysts engage with business leaders and users to understand how data-driven changes to process, services, products, software and hardware can improve efficiencies and add value. BAs must articulate those ideas but also balance them against what’s technologically feasible and functionally and financially reasonable.
| Feature | Data Science | Data Analytics |
| Definition | Data science uses scientific methods, algorithms, processes and systems to extract insights and knowledge from structured and unstructured data, and applying algorithms and actionable insights from data across a wide range of application domains. | Data analysis is a process of inspecting, cleansing, exploring, transforming, and modelling data with the goal of discovering useful information & patterns, informing conclusions, and supporting decision-making. |
| Working | The main difference between a data analyst and a data scientist is heavy coding which the Data Scientists need to be skilled in. Data scientists can arrange undefined sets of data using multiple tools at the same time, and build their own automation systems and frameworks. | Data analysts, analyze well-defined sets of data using a collection of different tools to answer substantial business needs E.g. why sales dropped in a certain region, why a marketing campaign fared better in a certain quarter, how some internal features affect revenue. |
| Major Domains | Machine learning, AI, Feature engineering, corporate analytics, Statistical modelling. | Healthcare, gaming, travel, industries, ecommerce with immediate data needs |
| Skills | Machine learning, Deep Learning, NLP, software development, Hadoop, Statistics, data mining/data warehouse, data analysis, Python. | Data mining/data warehouse, data modeling, R or SAS, SQL, statistical analysis, data visualization, database management & reporting, and data analysis. |
| Roles & Responsibilities | Data scientists are tasked with designing data modeling processes, as well as creating machine learning algorithms and predictive models to extract & organize the information needed by an organization to solve complex business problems. | Data analysts hold the responsibility to design and maintain data systems and databases, using statistical tools to interpret data sets, and preparing reports that effectively communicate trends, patterns, and predictions based on relevant findings. |
| Job Tasks | Data Cleansing, Pattern recognition, extracting meaningful insights & business insights from data using machine learning techniques | Data Processing, Data Cleansing, Exploratory data analysis, pattern recognition, database designing, developing visualizations & KPI’s. |
| Feature | Data Science | Business Intelligence |
| Definition | Data science uses scientific methods, processes, algorithms and systems to extract knowledge and insights from structured and unstructured data, and apply algorithms and actionable insights from data across a wide range of application domains. | Business intelligence comprises the strategies and technologies used by organizations for the data analysis of business information. BI technologies provide historical, current, and predictive views of business operations. |
| Data | It deals with both Structured & Unstructured Data. | It deals majorly with Structured Data. |
| Method | It is a Scientific method. | It is an Analytical method. |
| Complexity | MHighly complex | Comparatively simpler |
| Flexible | Data science is much more flexible as data sources can be added as per requirement. | It is less flexible as data sources need to be pre-planned in case of business intelligence. |
So now, let’s discuss how should one approach a problem and solve it with data science. Problems in Data Science are solved using Algorithms. But, the biggest thing to judge is which algorithm to use and when to use it?
Basically there are 5 kinds of problems which you can face in data science.
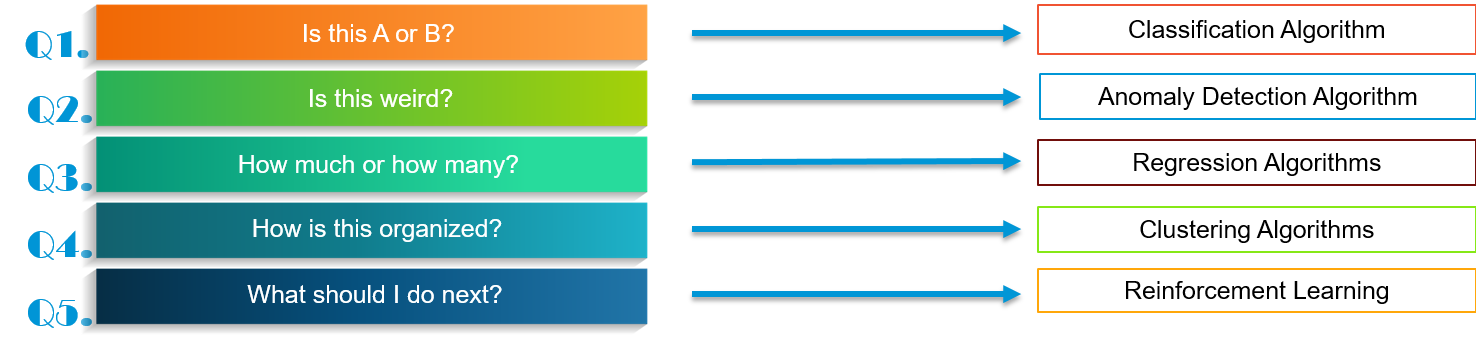
Let’s address each of these questions and the associated algorithms one by one:
Is this A or B?
With this question, we are referring to problems which have a categorical answer, as in problems which have a fixed solution, the answer could either be a yes or a no, 1 or 0, interested, maybe or not interested.
For Example:
Q. What will you have, Tea or Coffee?
Here, you cannot say you would want a coke! Since the question only offers tea or coffee, and hence you may answer one of these only.
When we have only two type of answers i.e yes or no, 1 or 0, it is called 2 – Class Classification. With more than two options, it is called Multi Class Classification.
Concluding, whenever you come across questions, the answer to which is categorical, in Data Science you will be solving these problems using Classification Algorithms.
The next problem in this Data Science Tutorial, that you may come across, maybe something like this,
Is this weird?
Questions like these deal with patterns and can be solved using Anomaly Detection algorithms.
For Example:
Try associating the problem “is this weird?” to this diagram,

What is weird in the above pattern? The red guy, isn’t it?
Whenever there is a break in pattern, the algorithm flags that particular event for us to review. A real world application of this algorithm has been implemented by Credit Card companies where in, any unusual transaction by a user is flagged for review. Hence implementing security and reducing human’s effort on surveillance.
Let’s look at the next problem in this Data Science Tutorial, don’t be scared, deals with maths!
How much or How many?
Those of you, who don’t like maths, be relieved! Regression algorithms are here!
So, whenever there is a problem which may ask for figures or numerical values, we solve it using Regression Algorithms.
For Example:

What will be the temperature for tomorrow?
Since we expect a numeric value in the response to this problem, we will solve it using Regression Algorithms.
Moving along in this Data Science Tutorial, let’s discuss the next algorithm,
How is this organised?
Say you have some data, now you don’t have any idea, how to make sense out of this data. Hence the question, how is this organised?
Well, you can solve it using clustering algorithms. How do they solve these problems? Let’s see:
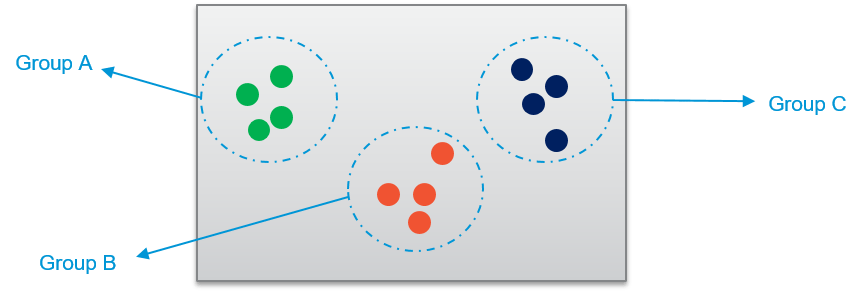
Clustering algorithms group the data in terms of characteristics which are common. For example in the above diagram, the dots are organised based on colors. Similarly, be it any data, clustering algorithms try to apprehend what is common between them and hence “clusters” them together.
The next and final kind of problem in this Data Science Tutorial, that you may encounter is,
What should I do next?
Whenever you encounter a problem, wherein your computer has to make a decision based on the training that you have given it, it involves Reinforcement Algorithms.
For Example:

Your temperature control system, when it has to decide whether it should lower the temperature of the room, or increase it.
How do these algorithms work?
These algorithms are based on human psychology. We like being appreciated right? Computers implement these algorithms, and expect being appreciated when being trained. How? Let’s see.
Rather than teaching the computer what to do, you let it decide what to do, and at the end of that action, you give either a positive or a negative feedback. Hence, rather than defining what is right and what is wrong in your system, you let your system “decide” what to do, and in the end give a feedback.
It’s just like training your dog. You cannot control what your dog does, right? But you can scold him when he does wrong. Similarly, maybe patting him on the back when he does what is expected.
Let’s apply this understanding in the example above, imagine you are training the temperature control system, so whenever the no. of people in the room increase, there has to be an action taken by the system. Either lower the temperature or increase it. Since our system doesn’t understand anything, it takes a random decision, let’s suppose, it increases the temperature. Therefore, you give a negative feedback. With this, the computer understands whenever the number of people increase in the room, never increase the temperature.
Similarly for other actions, you shall give feedback. With each feedback your system is learning and hence becomes more accurate in its next decision, this type of learning is called Reinforcement Learning.
Now, the algorithms that we learnt above in this Data Science Tutorial involve a common “learning practice”. We are making the machine learn right?

It is a type of Artificial Intelligence that makes the computers capable of learning on their own i.e without explicitly being programmed. With machine learning, machines can update their own code, whenever they come across a new situation.
Concluding in this Data Science Tutorial, we now know Data Science is backed by Machine Learning and its algorithms for its analysis. How we do the analysis, where do we do it. Data Science further has some components which aids us in addressing all these questions.
Before that let me answer how MIT can predict the future, because I think you guys might be able to relate it now. So, researchers in MIT trained their model with movies and the computers learnt how humans respond, or how do they act before doing an action.
For example, when you are about shake hands with someone you take your hand out of your pocket, or maybe lean in on the person. Basically there is a “pre action” attached to every thing we do. The computer with the help of movies was trained on these “pre actions”. And by observing more and more movies, their computers were then able to predict what the character’s next action could be.
Easy ain’t it? Let me throw one more question at you then in this Data Science Tutorial! Which algorithm of Machine Learning they must have implemented in this?
1. Datasets
What will you analyze on? Data, right? You need a lot of data which can be analyzed, this data is fed to your algorithms or analytical tools. You get this data from various researches conducted in the past.
2. R Studio![]()
R is an open source programming language and software environment for statistical computing and graphics that is supported by the R foundation. The R language is used in an IDE called R Studio.
Why is it used?



R Studio was sufficient for analysis, until our datasets became huge, also unstructured at the same time. This type of data was called Big Data.
3. Big Data

Big data is the term for a collection of data sets so large and complex that it becomes difficult to process using on-hand database management tools or traditional data processing applications.
Now to tame this data, we had to come up with a tool, because no traditional software could handle this kind of data, and hence we came up with Hadoop.
4. Hadoop

Hadoop is a framework which helps us to store and process large datasets in parallel and in a distribution fashion.
Let’s focus on the store and process part of Hadoop.
Store
The storage part in Hadoop is handled by HDFS i.e Hadoop Distributed File System. It provides high availability across a distributed ecosystem. The way it function is like this, it breaks the incoming information into chunks, and distributes them to different nodes in a cluster, allowing distributed storage.
Process
MapReduce is the heart of Hadoop processing. The algorithms do two important tasks, map and reduce. The mappers break the task into smaller tasks which are processed parallely. Once, all the mappers do their share of work, they aggregate their results, and then these results are reduced to a simpler value by the Reduce process. To learn more on Hadoop you can go through our Hadoop Tutorial blog series.
If we use Hadoop as our storage in Data Science it becomes difficult to process the input with R Studio, due to its inability to perform well in distributed environment, hence we have Spark R.
It is an R package, that provides a lightweight way of using Apache Spark with R. Why will you use it over tradition R applications? Because, it provides a distributed data frame implementation that supports operation like selection, filtering, aggregation etc but on large datasets.
Take a breather now ! We are done with the technical part in this Data Science Tutorial, let’s look at it from your job perspective now. I think you would have googled the salaries by now for a data scientist, but still, let’s discuss the job roles which are available for you as a data scientist.
Some of the prominent Data Scientist job titles are:
The Payscale.com chart in this Data Science Tutorial below shows the average Data Scientist salary by skills in the USA and India.

The time is ripe to up-skill in Data Science and Big Data Analytics to take advantage of the Data Science career opportunities that come your way. This brings us to the end of Data Science tutorial blog. I hope this blog was informative and added value to you. Now is the time to enter the Data Science world and become a successful Data Scientist.
Also, If you are looking for online structured training in Data Science, edureka! has a specially curated Data Science PGP Program that helps you gain expertise in Statistics, Data Wrangling, Exploratory Data Analysis, and Machine Learning Algorithms like K-Means Clustering, Decision Trees, Random Forest, and Naive Bayes. You’ll also learn the concepts of Time Series, Text Mining, and an introduction to Deep Learning. New batches for this course are starting soon!!
Also, To get in-depth knowledge on Data Science, you can enroll for live Python for Data Science Course by Edureka with 24/7 support and lifetime access.
Got a question for us in Data Science Tutorial? Please mention it in the comments section and we will get back to you.







































 Thank you for registering Join Edureka Meetup community for 100+ Free Webinars each month JOIN MEETUP GROUP
Thank you for registering Join Edureka Meetup community for 100+ Free Webinars each month JOIN MEETUP GROUP
you are doing a great work with up to date and technology
Nice tutorial! There can be an introductory course on deep learning methods with applications to machine translation, image recognition, game playing, image generation and more. Otherwise, this tutorial was really wonderful and worth spreading. Thanks for sharing!
I am complete novice on data science except that am quite into statistical data analysis for researches. What is best option to start a career in Data science and Big data
Hi, my name is Galih. I am interested in Data Science thing. In Hadoop-process part, it mention that hadoop produce distributed environment. Actually I don’t understand this one, can you explain a little more the definition of it and compared with another thing?? Hopely it will help another one who has a question similar like that. Big thanks.
I found this article and blog is very interesting helpful. Thank for sharing the knowledgeable article. I have been preparing to
become Big data analytics. can you share any resource for learning Big
Data?
Thank you for your post. This is excellent information. It is amazing and
wonderful to visit your site.
data science training services
hi
my name is Anwar…..i am a fresher with Computer Science Engineering background… am i learn data science easily?
Hey Anwar, if you are looking to truly master the technology then, do check out our Data Science course here: https://www.edureka.co/data-science-r-programming-certification-course
Hope this helps :)
Hi
I am from Mainframe background having 6.5 years of experience.
I have some knowledge in python dont know Java.
Which course should if go for datascience/hadoop etc ?
Hey Trushant, you can check out our Big Data Hadoop course here: https://www.edureka.co/big-data-hadoop-training-certification
This is the link to our Data Science Masters Program: https://www.edureka.co/masters-program/data-scientist-certification
You do not need to master Java and SQL for learning Big Data and Data Science. However, having functional knowledge of these languages can be beneficial. We provide complementary courses with our certification program which will help you in brushing up with Java before you start out.
Hope this helps :)
Hi. I’m very intrigued into Data Science and have a doubt. Which one of the two will be worth to do ? A PG degree in Data Analytics or Machine Learning and then looking for job or Mastering the required knowledge and skills on my own (using online/offline learning) and then looking for job?
Hey Tanvir! Going for a PG in Data and ML is a good option but won’t be that beneficial for you because at the end of that day having hands-on experience is what matters. Plus the time takn for you to complete PG will be a lot more than just getting certified. So, think of certifications and learning it by online/offline modules. This way, your focus will be directly on ML and Data analytics only. In college you will have a lot of other things to do/study which will deviate you from your goal.