





One of the most attractive features of Hadoop framework is its utilization of commodity hardware. However, this leads to frequent DataNode crashes in a Hadoop cluster. Another striking feature of Hadoop Framework is the ease of scale in accordance to the rapid growth in data volume. Because of these two reasons, one of the most common task of a Hadoop administrator is to commission (Add) and decommission (Remove) Data Nodes in a Hadoop Cluster.
Commissioning and Decommissioning Nodes in a Hadoop Cluster:
 Data Nodes in a Hadoop Cluster")
Above diagram shows a step by step process to decommission a DataNode in the cluster.
The first task is to update the ‘exclude‘ files for both HDFS (hdfs-site.xml) and MapReduce (mapred-site.xml).
The ‘exclude’ file:
- for jobtracker contains the list of hosts that should be excluded by the jobtracker. If the value is empty, no hosts are excluded.
- for Namenode contains a list of hosts that are not permitted to connect to the Namenode.
Here is the sample configuration for the exclude file in hdfs-site.xml and mapred-site.xml:
hdfs-site.xml
<property>
<name>dfs.hosts.exclude</name>
<value>/home/hadoop/excludes</value>
<final>true</final>
</property>
mapred-site.xml
<property>
<name>mapred.hosts.exclude</name>
<value>/home/hadoop/excludes</value>
<final>true</final>
</property>
Note: The full pathname of the files must be specified.
Similarly, we have the ‘include’ files:
- for jobtracker containing the list of nodes that may connect to the JobTracker. If the value is empty, all hosts are permitted.
- for Namenode containing a list of hosts that are permitted to connect to the Namenode. If the value is empty, all hosts are permitted.
The ‘dfsadmin’ and ‘mradmin’ commands refresh the configuration with the changes to make them aware of the new node.
The ‘slaves’ file on master server contains the list of all data nodes. This must also be updated to ensure any issues in future hadoop daemon start/stop.
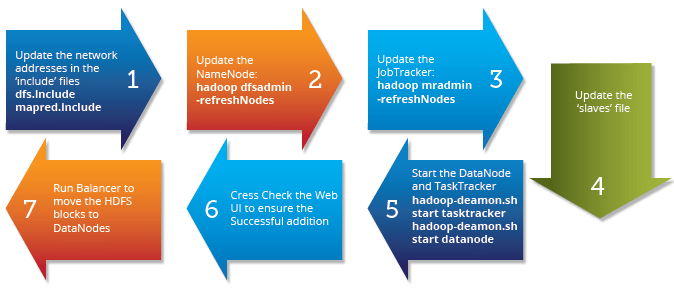
The important step in data node commission process is to run the Cluster Balancer.
>hadoop balancer -threshold 40
Balancer attempts to provide a balance to a certain threshold among data nodes by copying block data from older nodes to newly commissioned nodes.
So, this is how you can do – Commissioning and Decommissioning Nodes in a Hadoop Cluster.
Get a better understanding of the Hadoop Cluster from this Big Data Course.
Got a question for us? Please mention it in the comments section and we will get back to you.
Related Links:








































Hi, I am gonna start Hadoop cluster setup project. Could anyone help me in identifying the list of task/activities involved in this. I need to create a project plan for this.
Greetings, we’d recommend you to go through our blogs on Hadoop single node installation first and then our blog on Hadoop multi node installation. This will help you in getting a better idea and draw out a project plan better. Here is the link:
1. https://www.edureka.co/blog/install-hadoop-single-node-hadoop-cluster
2. https://www.edureka.co/blog/setting-up-a-multi-node-cluster-in-hadoop-2.X
You can revert back to us for any other query. Hope this helps :)
/home/hadoop/excludes – In this path is it EXCLUDES or EXCLUDE?
Hey Dinesh, thanks for checking out our blog.
Well, dfs.hosts.exclude is just a property in hdfs-site.xml and mapred-site.xml. You can check the content of these files by going to the place where hadoop is installed and then you can check for these hdfs-site.xml and mapred-site.xml. These are configuration files so you will find these in etc folder of hadoop. Basically, the main attribute is dfs.hosts.exclude whose name is fixed and hadoop expects only “exclude” word here. And it’s value is the file which has the list. In our example our filename is excludes. It’s name can even be /home/hadoop/myCoolName and then in you will have to write
dfs.hosts.exclude
/home/hadoop/myCoolName
true
Hope this helps. Cheers!
Thanks for reverting me back
I got the enough information from your website.. But there is a mistake in the Flow Diagram of “Commissioning” .. In the 3rd block hadoop mraadmin -refreshNodes should come.. Please check and update so that everyone know the exact flow.
Thanks for taking the time out to go through our blog in detail. We are sorry you encountered an error. We have flagged this to the concerned folks and they are working on fixing it ASAP. Thanks again and do keep checking back in whenever you have the time.
Beautiful !! Thanks a ton !!
You are welcome Akshat!!
very good explanation..!
Thanks Sandeep. Feel free to check out our other posts as well.
Good blog
Thanks Santosh!
Super Explanation.
Thanks Bala! Feel free to go through our other blog posts as well.