
Data Science with Python Certification Course
- 131k Enrolled Learners
- Weekend
- Live Class
(49300)





 Copy Link!
Copy Link!Are you a Python programmer looking for a powerful library for machine learning? If yes, then you must take scikit-learn into your consideration. Scikit learn in python plays an integral role in the concept of machine learning and is needed to earn your Python for Data Science Certification. This scikit-learn cheat sheet is designed for the one who has already started learning about the Python package but wants a handy reference sheet. Don’t worry if you are a beginner and have no idea about how scikit-learn works, this scikit-learn cheat sheet for machine learning will give you a quick reference of the basics that you must know to get started.
🐍 Ready to Unleash the Power of Python? Sign Up for Edureka’s Comprehensive Python Language Certification Course with access to hundreds of Python learning Modules and 24/7 technical support.
Scikit-learn is an open source Python library used for machine learning, preprocessing, cross-validation and visualization algorithms. It provides a range of supervised and unsupervised learning algorithms in Python.
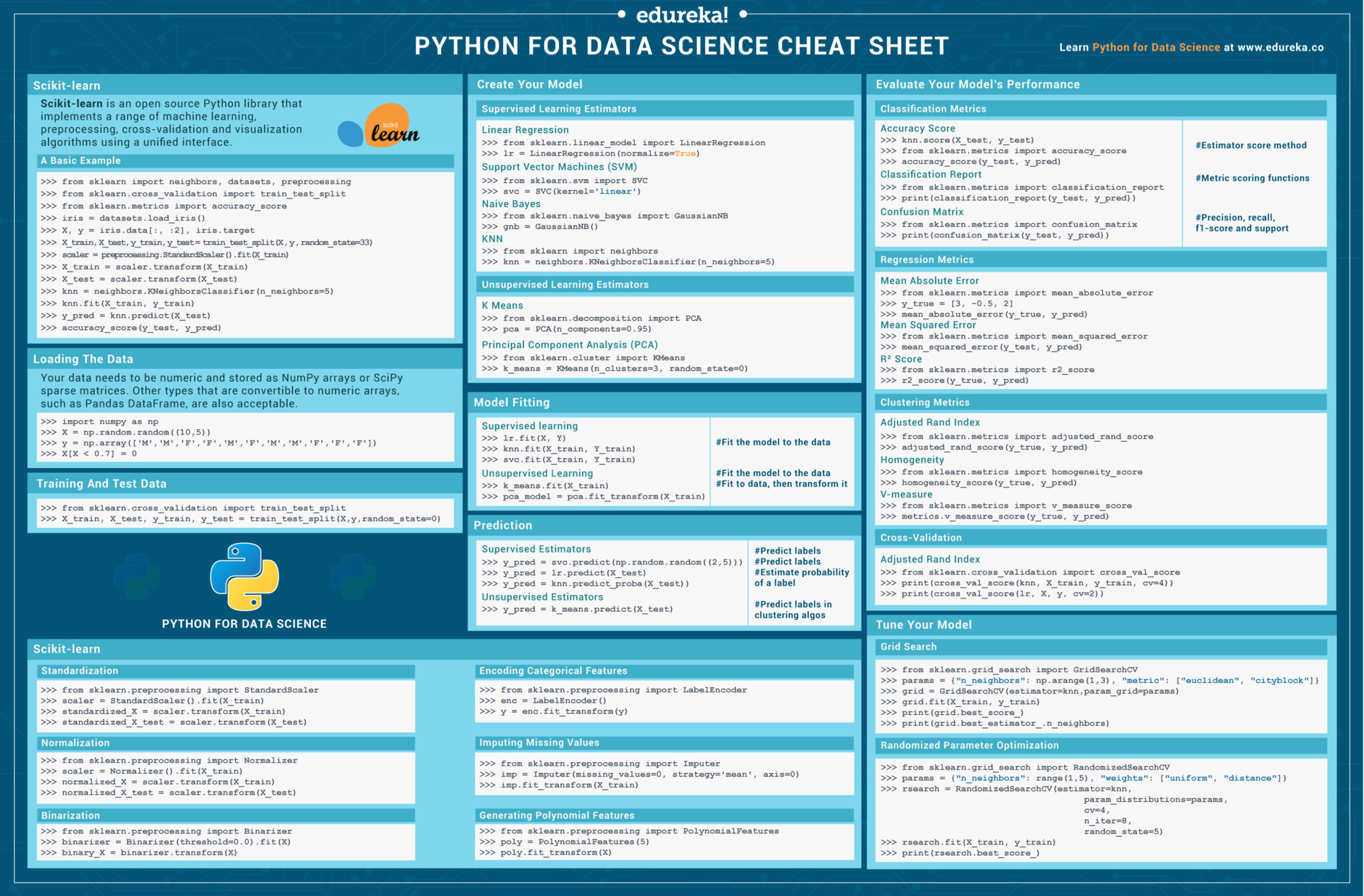
Let’s create a basic example using scikit-learn library which will be used to
>>> from sklearn import neighbors, datasets, preprocessing >>> from sklearn.model_selection import train_test_split >>> from sklearn.metrics import accuracy_score >>> iris = datasets.load_iris() >>> X, y = iris.data[:, :2], iris.target >>> X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=33) >>> scaler = preprocessing.StandardScaler().fit(X_train) >>> X_train = scaler.transform(X_train) >>> X_test = scaler.transform(X_test) >>> knn = neighbors.KNeighborsClassifier(n_neighbors=5) >>> knn.fit(X_train, y_train) >>> y_pred = knn.predict(X_test) >>> accuracy_score(y_test, y_pred)
You need to have a numeric data stored in NumPy arrays or SciPy sparse matrices. You can also use other numeric arrays, such as Pandas DataFrame.
>>> import numpy as np
>>> X = np.random.random((10,5))
>>> y = np.array(['M','M','F','F','M','F','M','M','F','F','F'])
>>> X[X < 0.7] = 0Once the data is loaded, your next task would be split your dataset into training data and testing data.
>>> from sklearn.model_selection import train_test_split >>> X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=0)
Data standardization is one of the data preprocessing step which is used for rescaling one or more attributes so that the attributes have a mean value of 0 and a standard deviation of 1. Standardization assumes that your data has a Gaussian (bell curve) distribution.
>>> from sklearn.preprocessing import StandardScaler
>>> scaler = StandardScaler().fit(X_train)
>>> standardized_X = scaler.transform(X_train)
>>> standardized_X_test = scaler.transform(X_test)Binarization is a common operation performed on text count data. Using binarization the analyst can decide to consider the presence or absence of a feature rather than having a quantified number of occurrences for instance.
>>> from sklearn.preprocessing import Binarizer >>> binarizer = Binarizer(threshold=0.0).fit(X) >>> binary_X = binarizer.transform(X)
Normalization is a technique generally used for data preparation for machine learning. The main goal of normalization is to change the values of numeric columns in the dataset so that we can have a common scale, without losing the information or distorting the differences in the ranges of values.
>>> from sklearn.preprocessing import Normalizer >>> scaler = Normalizer().fit(X_train) >>> normalized_X = scaler.transform(X_train) >>> normalized_X_test = scaler.transform(X_test)
The LabelEncoder is another class used in data-preprocessing for encoding class levels. It can also be used to transform non-numerical labels into numerical labels.
>>> from sklearn.preprocessing import LabelEncoder >>> enc = LabelEncoder() >>> y = enc.fit_transform(y)
The Imputer class in python will provide you with the basic strategies for imputing/filling missing values. It does this by using the mean, median values or the most frequent value of the row or column in which the missing values are located. This class also allows for encoding different missing values.
>>> from sklearn.preprocessing import Imputer >>> imp = Imputer(missing_values=0, strategy='mean', axis=0) >>> imp.fit_transform(X_train)
Polynomial Feature generates a new feature matrix which consists of all polynomial combinations of the features with degree less than or equal to the specified degree. For example, if an input sample is two dimensional and of the form [a, b], then the 2-degree polynomial features are [1, a, b, a^2, ab, b^2].
>>> from sklearn.preprocessing import PolynomialFeatures >>> poly = PolynomialFeatures(5) >>> poly.fit_transform(X)
Supervised learning is a type of machine learning that enables the model to predict future outcomes after they are trained on labelled data.
Unsupervised learning is a type of machine learning that enables the model to predict future outcomes without being trained on the labelled data.
# Linear Regression Algorithm >>> from sklearn.linear_model import LinearRegression >>> lr = LinearRegression(normalize=True) # Naive Bayes Algorithm >>> from sklearn.naive_bayes import GaussianNB >>> gnb = GaussianNB() # KNN Algorithm >>> from sklearn import neighbors >>> knn = neighbors.KNeighborsClassifier(n_neighbors=5) # Support Vector Machines (SVM) >>> from sklearn.svm import SVC >>> svc = SVC(kernel='linear’)
# Principal Component Analysis (PCA) >>> from sklearn.decomposition import PCA >>> pca = PCA(n_components=0.95) # K Means Clustering Algorithm >>> from sklearn.cluster import KMeans >>> k_means = KMeans(n_clusters=3, random_state=0)
Fitting is a measure of how well a machine learning model generalizes to similar data to that on which it was trained
# For Supervised learning >>> lr.fit(X, y) #Fits data into the model >>> knn.fit(X_train, y_train) >>> svc.fit(X_train, y_train) # For Unsupervised Learning >>> k_means.fit(X_train)#Fits data into the model >>> pca_model = pca.fit_transform(X_train) #Fit to data, then transform it
Fitting is a measure of how well a machine learning model generalizes to similar data to that on which it was trained
# For Supervised learning >>> y_pred=svc.predict(np.random((2,5))) #predict label >>> y_pred=lr.predict(x_test) #predict label >>> y_pred=knn.predict_proba(x_test)#estimate probablity of a label # For Unsupervised Learning >>> y_pred=k_means.predict(x_test) #predict labels in clustering algorithm
The sklearn.metrics module implements several loss, score, and utility functions to measure classification performance.
# Mean Absolute Error
>>> from sklearn.metrics import mean_absolute_error
>>> y_true = [3, -0.5, 2]
>>> mean_absolute_error(y_true, y_pred)
# Mean Squared Error
>>> from sklearn.metrics import mean_squared_error
>>> mean_squared_error(y_test, y_pred)
# R² Score
>>> from sklearn.metrics import r2_score
>>> r2_score(y_true, y_pred)The sklearn.metrics module implements several loss, score, and utility functions to measure regression performance.
# Accuracy Score >>> knn.score(X_test, y_test) >>> from sklearn.metrics import accuracy_score >>> accuracy_score(y_test, y_pred) # Classification Report >>> from sklearn.metrics import classification_report >>> print(classification_report(y_test, y_pred)) # Confusion Matrix >>> from sklearn.metrics import confusion_matrix >>> print(confusion_matrix(y_test, y_pred))
# Adjusted Rand Index >>> from sklearn.metrics import adjusted_rand_score >>> adjusted_rand_score(y_true, y_pred) # Homogeneity >>> from sklearn.metrics import homogeneity_score >>> homogeneity_score(y_true, y_pred) # V-measure >>> from sklearn.metrics import v_measure_score >>> metrics.v_measure_score(y_true, y_pred)
>>> from sklearn.cross_validation import cross_val_score
>>> print(cross_val_score(knn, X_train, y_train, cv=4))
>>> print(cross_val_score(lr, X, y, cv=2))GridSearchCV implements a “fit” and a “score” method. It also implements “predict”, “predict_proba”, “decision_function”, “transform” and “inverse_transform” if they are implemented in the estimator used.
>>> from sklearn.grid_search import GridSearchCV >>> params = {"n_neighbors": np.arange(1,3), "metric": ["euclidean", "cityblock"]} >>> grid = GridSearchCV(estimator=knn, param_grid=params) >>> grid.fit(X_train, y_train) >>> print(grid.best_score_) >>> print(grid.best_estimator_.n_neighbors)
RandomizedSearchCV performs the random search on hyper parameters. In contrast to GridSearchCV, not all parameter values are tried out, but rather a fixed number of parameter settings is sampled from the specified distributions. The number of parameter settings that are tried is given by n_iter.
>>> from sklearn.grid_search import RandomizedSearchCV
>>> params = {"n_neighbours": range(1,5), "weights":["uniform", "distance"]}
>>>rserach = RandomizedSearchCV(estimator=knn,param_distribution=params, cv=4, n_iter=8, random_state=5)
>>> rsearch.fit(X_train, Y_train)
>>> print(rsearch.best_score)






































 Thank you for registering Join Edureka Meetup community for 100+ Free Webinars each month JOIN MEETUP GROUP
Thank you for registering Join Edureka Meetup community for 100+ Free Webinars each month JOIN MEETUP GROUP
Hi all can anybody suggest me exact responsibilities of Data Science