CCA-175 Spark and Hadoop Developer Certification is the emblem of Precision, Proficiency, and Perfection in Apache Hadoop Development. There is a lofty demand for CCA-175 Certified Developers in the current IT-industry. Let us understand more about this.
- What is CCA-175 Spark and Hadoop Developer Certification?
- CCA-175 Spark and Hadoop Developer Certification Exam Format
- Required Skills for CCA-175
- Sample Question from CCA-175 exam
- Edureka CCA-175 Certification
- Salary of a Hadoop Developer
What is CCA-175 Spark and Hadoop Developer Certification?
CCA-175 is basically an Apache Hadoop with Apache Spark and Scala Training and Certification Program. The major objective of this program is to help Hadoop developers to establish a formidable command, over the current traditional Hadoop Development protocols with advanced tools and operational procedures.
The program deals with the following segments:
- Apache Hadoop
- Apache Spark
- Scala Programming Language
Apache Hadoop

Apache Hadoop is a powerful software framework designed to provide distributed storage and processing system. It is open-source software designed an deployed by the Apache Foundation.
Apache Spark
![]()
Apache Spark is a Lightning Fast Data Processing Tool used on top of Apache Hadoop Distributed File System(HDFS). It is an Open-Source Data Processing tool developed by Apache Foundation.
Scala Programming Language
![]()
Scala is an advanced programmed language developed using Java Programming language. It is used to execute data processing commands in Spark on top of Hadoop.
CCA-175 Spark and Hadoop Developer Certification Exam Format
Let me give you a brief understanding of CCA-175 Spark and Hadoop Developer Certification Exam.
- Number of Questions

The total number of questions asked in this particular exam will be in between 8 to 12. The questions will be purely performance-based (hands-on) tasks on Cloudera Enterprise cluster.
- Examination Time Limit

The total time limit provided for this particular exam is exactly 120 minutes.
- Cut-off score to pass

Any Hadoop Developer attending this Examination is expected to score at least 70% to clear this examination and get certified.
- Price of the examination

The current pricing of this examination is US$ 295$ to 300$. (21,000 rupees INR to 22,000 INR)
Sample Question from CCA-175 exam

Using Apache Sqoop, you have to import orders table into HDFS to folder location “/user/cloudera/problem1/orders”. The file should be loaded as Avro File and use snappy compression
Using Apache Sqoop, you have to import order_items table into HDFS to folder location “/user/cloudera/problem1/order-items”. The files should be loaded as Avro file and use snappy compression
Using ApacheSparkScala, You have to load data at locations “/user/cloudera/problem1/orders” and “/user/cloudera/problem1/orders-items items as dataframes.
Expected Intermediate Result: Order_Date , Order_status, total_orders, total_amount. In layman terms, please find total orders and total amount per status per day. The result should be sorted by order date in descending, order status in ascending and total amount in descending and total orders in ascending. Aggregation should be done using the below methods. However, sorting can be done using a dataframe or RDD. Perform aggregation in each of the following ways
Just by using Data Frames API – here order_date should be YYYY-MM-DD format
Using Spark SQL – here order_date should be YYYY-MM-DD format
By using combineByKey function on RDDS — No need of formatting order_date or total_amount
Store the result as parquet file into HDFS using gzip compression under the folder
/user/cloudera/problem1/result4a-gzip
/user/cloudera/problem1/result4b-gzip
/user/cloudera/problem1/result4c-gzip
Store the result as parquet file into HDFS using snappy compression under the folder
/user/cloudera/problem1/result4a-snappy
/user/cloudera/problem1/result4b-snappy
/user/cloudera/problem1/result4c-snappy
Store the result as CSV file into HDFS using No compression under the folder
/user/cloudera/problem1/result4a-csv
/user/cloudera/problem1/result4b-csv
/user/cloudera/problem1/result4c-csv
Create a mysql table named result and load data from “/user/cloudera/problem1/result4a-csv” to “mysql” table named result
Solution:

Step 1:
sqoop import --connect "jdbc:mysql://quickstart.cloudera:3306/retail_db" --username retail_dba --password cloudera --table orders --compress --compression-codec org.apache.hadoop.io.compress.SnappyCodec --target-dir /user/cloudera/problem1/orders --as-avrodatafile;
Step 2:
sqoop import --connect "jdbc:mysql://quickstart.cloudera:3306/retail_db" --username retail_dba --password cloudera --table order_items --compress --compression-codec org.apache.hadoop.io.compress.SnappyCodec --target-dir /user/cloudera/problem1/order-items --as-avrodatafile;
Step3:
//start a new terminal and fire this command.
spark-shell
//now, continue executing these commands below.
import com.databricks.spark.avro._;
var ordersDF = sqlContext.read.avro("/user/cloudera/problem1/orders");
var orderItemDF = sqlContext.read.avro("/user/cloudera/problem1/order-items");
Step 4:
var joinedOrderDataDF = ordersDF.join(orderItemDF,ordersDF("order_id")===orderItemDF("order_item_order_id"))
Step 4a:
import org.apache.spark.sql.functions._;
var dataFrameResult = joinedOrderDataDF.groupBy(to_date(from_unixtime(col("order_date")/1000)).alias("order_formatted_date"),col("order_status")).agg(round(sum("order_item_subtotal"),2).alias("total_amount"),countDistinct("order_id").alias("total_orders")).orderBy(col("order_formatted_date").desc,col("order_status"),col("total_amount").desc,col("total_orders"));
dataFrameResult.show();
Step 4b:
joinedOrderDataDF.registerTempTable("order_joined");
var sqlResult = sqlContext.sql("select to_date(from_unixtime(cast(order_date/1000 as bigint))) as order_formatted_date, order_status, cast(sum(order_item_subtotal) as DECIMAL (10,2)) as total_amount, count(distinct(order_id)) as total_orders from order_joined group by to_date(from_unixtime(cast(order_date/1000 as bigint))), order_status order by order_formatted_date desc,order_status,total_amount desc, total_orders");
sqlResult.show();
Step 4c:
var comByKeyResult =joinedOrderDataDF.map(x=> ((x(1).toString,x(3).toString),(x(8).toString.toFloat,x(0).toString))).combineByKey((x:(Float, String))=>(x._1,Set(x._2)),(x:(Float,Set[String]),y:(Float,String))=>(x._1 + y._1,x._2+y._2),(x:(Float,Set[String]),y:(Float,Set[String]))=>(x._1+y._1,x._2++y._2)).map(x=> (x._1._1,x._1._2,x._2._1,x._2._2.size)).toDF().orderBy(col("_1").desc,col("_2"),col("_3").desc,col("_4"));
comByKeyResult.show();
Step 5:
sqlContext.setConf("spark.sql.parquet.compression.codec","gzip");
dataFrameResult.write.parquet("/user/cloudera/problem1/result4a-gzip");
sqlResult.write.parquet("/user/cloudera/problem1/result4b-gzip");
comByKeyResult.write.parquet("/user/cloudera/problem1/result4c-gzip");
Step 6:
sqlContext.setConf("spark.sql.parquet.compression.codec","snappy");
dataFrameResult.write.parquet("/user/cloudera/problem1/result4a-snappy");
sqlResult.write.parquet("/user/cloudera/problem1/result4b-snappy");
comByKeyResult.write.parquet("/user/cloudera/problem1/result4c-snappy");
Step 7:
dataFrameResult.map(x=> x(0) + "," + x(1) + "," + x(2) + "," + x(3)).saveAsTextFile("/user/cloudera/problem1/result4a-csv")
sqlResult.map(x=> x(0) + "," + x(1) + "," + x(2) + "," + x(3)).saveAsTextFile("/user/cloudera/problem1/result4b-csv")
comByKeyResult.map(x=> x(0) + "," + x(1) + "," + x(2) + "," + x(3)).saveAsTextFile("/user/cloudera/problem1/result4c-csv")
Step 8a:
Fire up a new terminal and type in this command mysql -h localhost -u retail_dba -p //default password is: cloudera
Step 8b:
create table retail_db.result(order_date varchar(255) not null,order_status varchar(255) not null, total_orders int, total_amount numeric, constraint pk_order_result primary key (order_date,order_status));
Step 8c:
sqoop export --table result --connect "jdbc:mysql://quickstart.cloudera:3306/retail_db" --username retail_dba --password cloudera --export-dir "/user/cloudera/problem1/result4a-csv" --columns "order_date,order_status,total_amount,total_orders"
Let us now get into the CCA-175 Spark and Certification offered by Edureka.
Edureka CCA-175 Certification

Apache Spark and Scala Certification Training is designed to prepare you for the Cloudera Hadoop and Spark Developer Certification Exam (CCA175). You will gain in-depth knowledge on Apache Spark and the Spark Ecosystem,
Edureka Training includes RDD, Spark SQL, Spark MLlib and Spark Streaming. You will get comprehensive knowledge on Scala Programming language, HDFS, Sqoop, Flume, Spark GraphX and Messaging System such as Kafka.
Required Skills for CCA-175
Data Ingestion:
- Import data from a MySQL database into HDFS using Sqoop
- Export data to a MySQL database from HDFS using Apache Sqoop
- Change the delimiter and file format of data during import using Sqoop
- Ingest real-time and near-real-time (NRT) streaming data into HDFS using Flume
- Load data into and out of HDFS using the Hadoop File System (FS) commands
Transform Stage Store:
- Load data from HDFS and store results back to HDFS using Spark
- Join disparate datasets together using Spark
- Calculate aggregate statistics using Spark. Example: average or sum
- Filter data into a smaller dataset using Spark
- Write a query that produces ranked or sorted data using Spark
Data Analysis:
- Read and create a table in the Hive meta-store in a given schema
- Extract an Avro schema from a set of data files using Avro-tools
- Create a table in the Hive meta-store using the Avro file format and an external schema file
- Improve query performance by creating partitioned tables in the Hive meta-store
- Evolve an Avro schema by changing JSON files
Salary of a Hadoop Developer
Hadoop Developer is one of the most highly paid profiles in the current IT Industry. The Salary trends for a Hadoop developer have increased decently since last few years. Let us check out the raise in the salary trends for Hadoop developers compared to other profiles.

Let us now discuss the salary trends for a Hadoop Developer in different countries based on the experience. Firstly, let us consider the United States of America. Based On Experience, the Big Data professionals working in the domains are offered with respective salaries as described below.

The freshers or entry-level salaries start at 75,000 USD to 80,000 USD while the candidates with considerable experience are being offered 125,000 USD to 150,000 USD per annum.
Followed by the United Nations of America, we will now discuss the Hadoop Developer Salary Trends in India.
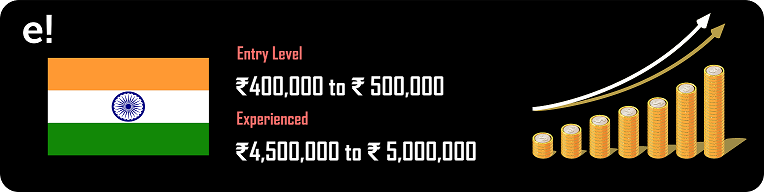
The Salary trends for a Hadoop Developer in India for the freshers or entry-level salaries start at 400,00 INR to 500,000 INR while the candidates with considerable experience are being offered 4,500,000 ₹ to 5,000,000 ₹.
Next, let us take a look at the salary trends for Hadoop Developers in the United Kingdom.

The Salary trends for a Hadoop Developer in India for the freshers or entry-level salaries start at 25,000 Pounds to 30,000 Pounds and on the other hand, for an experienced candidate, the salary offered is 80,000 Pounds to 90,000 Pounds.
So, with this, we come to an end of this “CCA-175 Spark and Hadoop Developer Certification” article. I hope we sparked a little light upon your knowledge about Spark, Scala and Hadoop along with CCA-175 certification features and its importance.
This article highlights concepts relevant to the Microsoft Fabric Data Engineer Associate training, helping you build a solid foundation in modern data engineering. While it covers Apache Spark and the Spark Ecosystem—including Spark RDD, Spark SQL, Spark MLlib, and Spark Streaming—it also touches upon complementary tools like Scala, HDFS, Sqoop, Flume, GraphX, and Kafka to give you a complete picture of end-to-end data pipelines.