
Advanced Certification in Agentic AI Engineer ...
- 66k Enrolled Learners
- Weekend
- Live Class
(45931)





 Copy Link!
Copy Link!With so many advancements in healthcare, marketing, business and so on, it has become necessary to develop more advanced and complex Machine Learning techniques. Boosting Machine Learning is one such technique that can be used to solve complex, data-driven, real-world problems. This blog is entirely focused on how Boosting Machine Learning works and how it can be implemented to increase the efficiency of Machine Learning models.
Here’s a list of topics that will be covered in this blog:
To solve convoluted problems we require more advanced techniques. Let’s suppose that on given a data set of images containing images of cats and dogs, you were asked to build a model that can classify these images into two separate classes. Like every other person, you will start by identifying the images by using some rules, like given below:
The image has pointy ears: Cat
The image has cat shaped eyes: Cat
The image has bigger limbs: Dog
The image has sharpened claws: Cat
The image has a wider mouth structure: Dog
All these rules help us identify whether an image is a Dog or a cat, however, if we were to classify an image based on an individual (single) rule, the prediction would be flawed. Each of these rules, individually, are called weak learners because these rules are not strong enough to classify an image as a cat or dog.
Therefore, to make sure that our prediction is more accurate, we can combine the prediction from each of these weak learners by using the majority rule or weighted average. This makes a strong learner model.
In the above example, we have defined 5 weak learners and the majority of these rules (i.e. 3 out of 5 learners predict the image as a cat) gives us the prediction that the image is a cat. Therefore, our final output is a cat.
So this brings us to the question,
Boosting is an ensemble learning technique that uses a set of Machine Learning algorithms to convert weak learner to strong learners in order to increase the accuracy of the model.
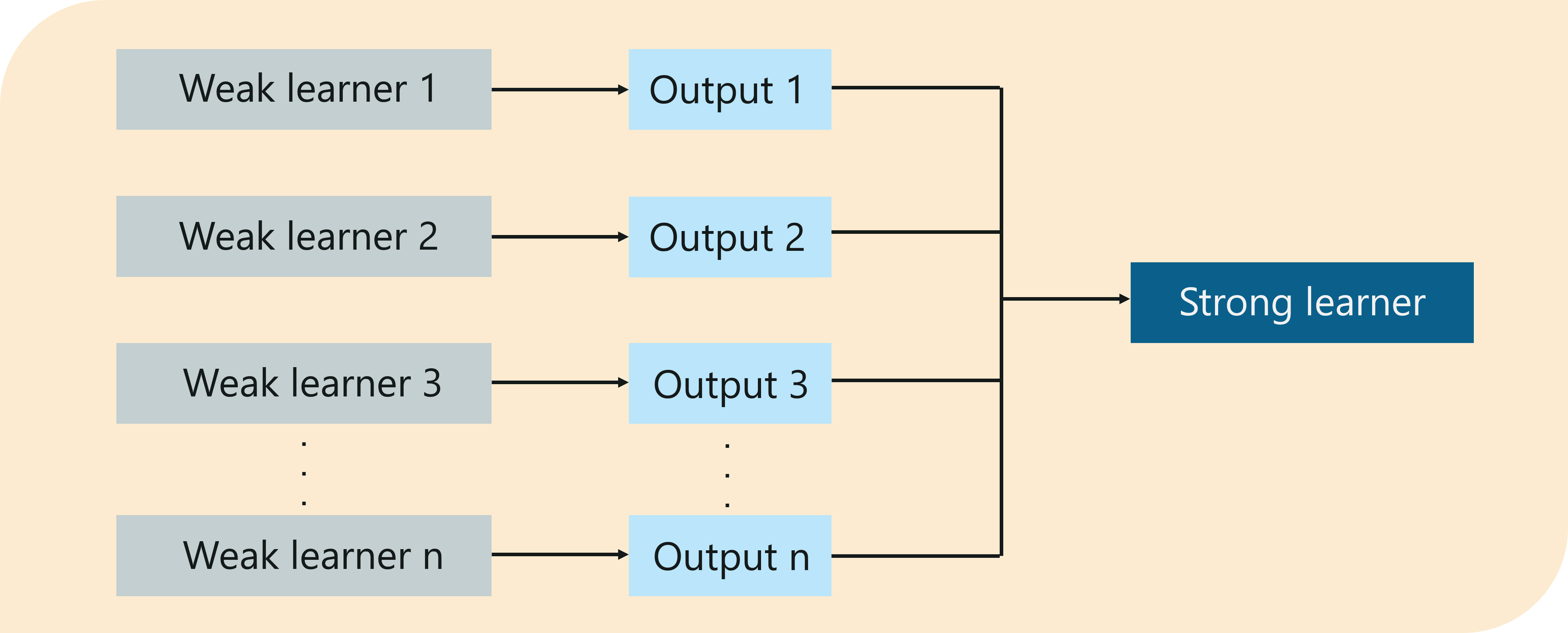
What Is Boosting – Boosting Machine Learning – Edureka
Like I mentioned Boosting is an ensemble learning method, but what exactly is ensemble learning?
Ensemble learning is a method that is used to enhance the performance of Machine Learning model by combining several learners. When compared to a single model, this type of learning builds models with improved efficiency and accuracy. This is exactly why ensemble methods are used to win market leading competitions such as the Netflix recommendation competition, Kaggle competitions and so on.
What Is Ensemble Learning – Boosting Machine Learning – Edureka
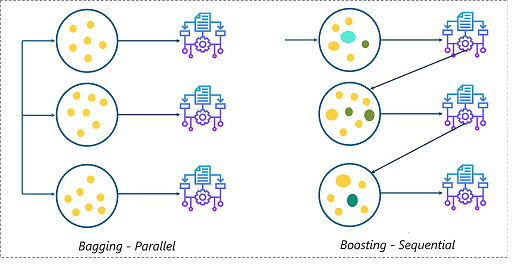
Below I have also discussed the difference between Boosting and Bagging.
Ensemble learning can be performed in two ways:
Sequential ensemble, popularly known as boosting, here the weak learners are sequentially produced during the training phase. The performance of the model is improved by assigning a higher weightage to the previous, incorrectly classified samples. An example of boosting is the AdaBoost algorithm.
Parallel ensemble, popularly known as bagging, here the weak learners are produced parallelly during the training phase. The performance of the model can be increased by parallelly training a number of weak learners on bootstrapped data sets. An example of bagging is the Random Forest algorithm.
In this blog, I’ll be focusing on the Boosting method, so in the below section we will understand how the boosting algorithm works.
The basic principle behind the working of the boosting algorithm is to generate multiple weak learners and combine their predictions to form one strong rule. These weak rules are generated by applying base Machine Learning algorithms on different distributions of the data set. These algorithms generate weak rules for each iteration. After multiple iterations, the weak learners are combined to form a strong learner that will predict a more accurate outcome.
How Does Boosting Algorithm Work – Boosting Machine Learning – Edureka
Here’s how the algorithm works:
Step 1: The base algorithm reads the data and assigns equal weight to each sample observation.
Step 2: False predictions made by the base learner are identified. In the next iteration, these false predictions are assigned to the next base learner with a higher weightage on these incorrect predictions.
Step 3: Repeat step 2 until the algorithm can correctly classify the output.
Therefore, the main aim of Boosting is to focus more on miss-classified predictions.
Now that we know how the boosting algorithm works, let’s understand the different types of boosting techniques.
There are three main ways through which boosting can be carried out:
Adaptive Boosting or AdaBoost
Gradient Boosting
XGBoost
I’ll be discussing the basics behind each of these types.
AdaBoost is implemented by combining several weak learners into a single strong learner.
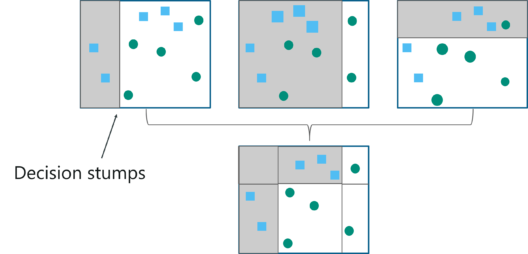
The weak learners in AdaBoost take into account a single input feature and draw out a single split decision tree called the decision stump. Each observation is weighed equally while drawing out the first decision stump.
The results from the first decision stump are analyzed and if any observations are wrongfully classified, they are assigned higher weights.
Post this, a new decision stump is drawn by considering the observations with higher weights as more significant.
Again if any observations are misclassified, they’re given higher weight and this process continues until all the observations fall into the right class.
Adaboost can be used for both classification and regression-based problems, however, it is more commonly used for classification purpose.
Gradient Boosting is also based on sequential ensemble learning. Here the base learners are generated sequentially in such a way that the present base learner is always more effective than the previous one, i.e. the overall model improves sequentially with each iteration.
The difference in this type of boosting is that the weights for misclassified outcomes are not incremented, instead, Gradient Boosting method tries to optimize the loss function of the previous learner by adding a new model that adds weak learners in order to reduce the loss function.
The main idea here is to overcome the errors in the previous learner’s predictions. This type of boosting has three main components:
Loss function that needs to be ameliorated.
Weak learner for computing predictions and forming strong learners.
An Additive Model that will regularize the loss function.
Like AdaBoost, Gradient Boosting can also be used for both classification and regression problems.
XGBoost is an advanced version of Gradient boosting method, it literally means eXtreme Gradient Boosting. XGBoost developed by Tianqi Chen, falls under the category of Distributed Machine Learning Community (DMLC).
The main aim of this algorithm is to increase the speed and efficiency of computation. The Gradient Descent Boosting algorithm computes the output at a slower rate since they sequentially analyze the data set, therefore XGBoost is used to boost or extremely boost the performance of the model.

XGBoost – Boosting Machine Learning – Edureka
XGBoost is designed to focus on computational speed and model efficiency. The main features provided by XGBoost are:
Parallelly creates decision trees.
Implementing distributed computing methods for evaluating large and complex models.
Using Out-of-Core Computing to analyze huge datasets.
Implementing cache optimization to make the best use of resources.
So these were the different types of Boosting Machine Learning algorithms. To make things interesting, in the below section we will run a demo to see how boosting algorithms can be implemented in Python.
A short disclaimer: I’ll be using Python to run this demo, so if you don’t know Python, you can go through the following blogs:
Now it’s time to get your hands dirty and start coding.
Problem Statement: To study a mushroom data set and build a Machine Learning model that can classify a mushroom as either poisonous or not, by analyzing its features.
Data Set Description: This data set provides a detailed description of hypothetical samples in accordance with 23 species of gilled mushrooms. Each species is classified as either edible mushrooms or non-edible (poisonous) ones.
Logic: To build a Machine Learning model by using one of the Boosting algorithms in order to predict whether or not a mushroom is edible.
Step 1: Import the required packages
from sklearn.ensemble import AdaBoostClassifier from sklearn.preprocessing import LabelEncoder from sklearn.tree import DecisionTreeClassifier import pandas as pd # Import train_test_split function from sklearn.model_selection import train_test_split #Import scikit-learn metrics module for accuracy calculation from sklearn import metrics
Step 2: Import the data set
# Load in the data
dataset = pd.read_csv('C://Users//NeelTemp//Desktop//mushroomsdataset.csv')
Step 3: Data Processing
#Define the column names dataset.columns = ['target','cap-shape','cap-surface','cap-color','bruises','odor','gill-attachment','gill-spacing', 'gill-size','gill-color','stalk-shape','stalk-root','stalk-surface-above-ring','stalk-surface-below-ring','stalk-color-above-ring', 'stalk-color-below-ring','veil-type','veil-color','ring-number','ring-type','spore-print-color','population', 'habitat'] for label in dataset.columns: dataset[label] = LabelEncoder().fit(dataset[label]).transform(dataset[label]) #Display information about the data set print(dataset.info()) Int64Index: 8124 entries, 6074 to 686 Data columns (total 23 columns): target 8124 non-null int32 cap-shape 8124 non-null int32 cap-surface 8124 non-null int32 cap-color 8124 non-null int32 bruises 8124 non-null int32 odor 8124 non-null int32 gill-attachment 8124 non-null int32 gill-spacing 8124 non-null int32 gill-size 8124 non-null int32 gill-color 8124 non-null int32 stalk-shape 8124 non-null int32 stalk-root 8124 non-null int32 stalk-surface-above-ring 8124 non-null int32 stalk-surface-below-ring 8124 non-null int32 stalk-color-above-ring 8124 non-null int32 stalk-color-below-ring 8124 non-null int32 veil-type 8124 non-null int32 veil-color 8124 non-null int32 ring-number 8124 non-null int32 ring-type 8124 non-null int32 spore-print-color 8124 non-null int32 population 8124 non-null int32 habitat 8124 non-null int32 dtypes: int32(23) memory usage: 793.4 KB
Step 4: Data Splicing
X = dataset.drop(['target'], axis=1) Y = dataset['target'] X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size=0.3)
Step 5: Build the model
model = DecisionTreeClassifier(criterion='entropy', max_depth=1) AdaBoost = AdaBoostClassifier(base_estimator=model, n_estimators=400, learning_rate=1)
In the above code snippet, we have implemented the AdaBoost algorithm. The ‘AdaBoostClassifier’ function takes three important parameters:
#Fit the model with training data boostmodel = AdaBoost.fit(X_train, Y_train)
Step 6: Model Evaluation
#Evaluate the accuracy of the model
y_pred = boostmodel.predict(X_test)
predictions = metrics.accuracy_score(Y_test, y_pred)
#Calculating the accuracy in percentage
print('The accuracy is: ', predictions * 100, '%')
The accuracy is: 100.0 %
We’ve received an accuracy of 100% which is perfect!
So with this, we come to an end of this Boosting Machine Learning Blog. If you wish to learn more about Machine Learning, you can give these blogs a read:
Are you wondering how to advance once you know the basics of what Machine Learning is? Take a look at Edureka’s Machine Learning Certification, which will help you get on the right path to succeed in this fascinating field. Learn the fundamentals of Machine Learning, machine learning steps and methods that include unsupervised and supervised learning, mathematical and heuristic aspects, and hands-on modeling to create algorithms. You will be prepared for the position of Machine Learning engineer.
If you’re trying to grow your career in Deep learning, check out our Deep Learning Course. This course equips students with information about the tools, techniques, and tools they require to advance their careers.















 Thank you for registering Join Edureka Meetup community for 100+ Free Webinars each month JOIN MEETUP GROUP
Thank you for registering Join Edureka Meetup community for 100+ Free Webinars each month JOIN MEETUP GROUP


