







Most of us have an idea about who a data engineer is, but we are confused about the roles & responsibilities of Big Data Engineer. This ambiguity increases once we start mapping those roles & responsibilities with apt skill sets and finding the most effective and efficient learning path. But don’t worry, you have landed at the right place. This “Big Data Engineer Skills” blog will help you understand the different responsibilities of a data engineer. Henceforward, I will map those responsibilities with the proper skill set & will guide you through the apt learning path.
Who is a Data Engineer?
In simple words, Data Engineers are the ones who develops, constructs, tests & maintains the complete architecture of the large-scale processing system.
Next, let’s further drill down on the job role of a Data Engineer.
What does a Data Engineer do?
The crucial tasks included in Data Engineer’s job role are:

- Building highly scalable, robust & fault-tolerant systems.
- Taking care of the complete ETL(Extract, Transform & Load) process.
- Ensuring architecture is planned in such a way that it meets all the business requirements.
- Discover various opportunities for data acquisitions and exploring new ways of using existing data.
- Proposing ways to improve data quality, reliability & efficiency of the whole system.
- Creating a complete solution by integrating a variety of programming languages & tools together.
- Creating data models to reduce system complexity and hence increase efficiency & reduce cost.
- Deploying Disaster Recovery Techniques
- Introducing new data management tools & technologies into the existing system to make it more efficient.

The best way to become a Data Engineer is by getting the Azure Data Engineer Associate Certification Course. Next, I would like to address a very common confusion, i.e., the difference between the data & big data engineer.

Also Read : Azure Databricks Architecture Overview
Difference Between Data Engineer & Big Data Engineers
We are in the age of data revolution, where data is the fuel of the 21st century. Various data sources & numerous technologies have evolved over the last two decades, & the major ones are NoSQL databases & Big Data frameworks.
With the advent of Big Data in data management system, the Data Engineer now has to handle & manage Big Data, and their role has been upgraded to Big Data Engineer. Due to Big Data, the whole data management system is becoming more & more complex. So, now Big Data Engineers have to learn multiple Big Data frameworks & NoSQL databases, to create, design & manage the processing systems.
Advancing in this Big Data Engineer Skills blog lets us know the responsibilities of a Big Data Engineer. This would help us to map the Data Engineer responsibilities with the required skill sets.
Also Read Data Engineer Salary
Data Engineer Responsibilities
Data ingestion

Data Engineers need skills to efficiently extract the data from a source, which can include different data ingestion approaches like batch & real-time extraction. There are various other skills which could make the data ingestion more efficient like incremental load, loading the data parallelly, etc.
When it comes to Big Data World, Data ingestion becomes more complex as the amount of data starts accelerating, & the data is also present in different formats. Data Engineer also needs to know data mining & different data ingestion APIs to capture & inject more data into data lakes.
Data Transformation


Performance Optimization


Building a system which is both scalable & efficient is challenging work. Data Engineers need to understand how to improve the performance of individual data pipeline & optimize the overall system.
Again, when we are dealing with Big Data platforms, performance becomes a major factor. Big Data engineer needs to make sure that the complete process, from the query execution to visualizing the data through report & interactive dashboards should be optimized. This requires various concepts like partitioning, indexing, de-normalization, etc.
Apart from these, a variety of responsibilities can be found in Data Engineer job based on the tools & technologies which the industry is using.
Summarizing the responsibilities of a Big Data Engineer:
- Design, create, build & maintain data pipelines
- Aggregate & Transform raw data coming from a variety of data sources to fulfill the functional & non-functional business needs
- Performance optimization: Automating processes, optimizing data delivery & re-designing the complete architecture to improve performance.
- Handling, transforming & managing Big Data using Big Data Frameworks & NoSQL databases.
- Building complete infrastructure to ingest, transform & store data for further analysis & business requirement.
Related Learning: Automation Testing Skills
Required Skills To Become A Big Data Engineer
- Big Data Frameworks/Hadoop-based technologies: With the rise of Big Data in the early 21st century, a new framework was born. This is Hadoop! All thanks to Doug Cutting, for introducing a framework which not only stores Big Data in a distributed manner but also processes the data parallelly.
There are a number of tools in the Hadoop Ecosystem which caters for different purposes & professionals belonging to different backgrounds.
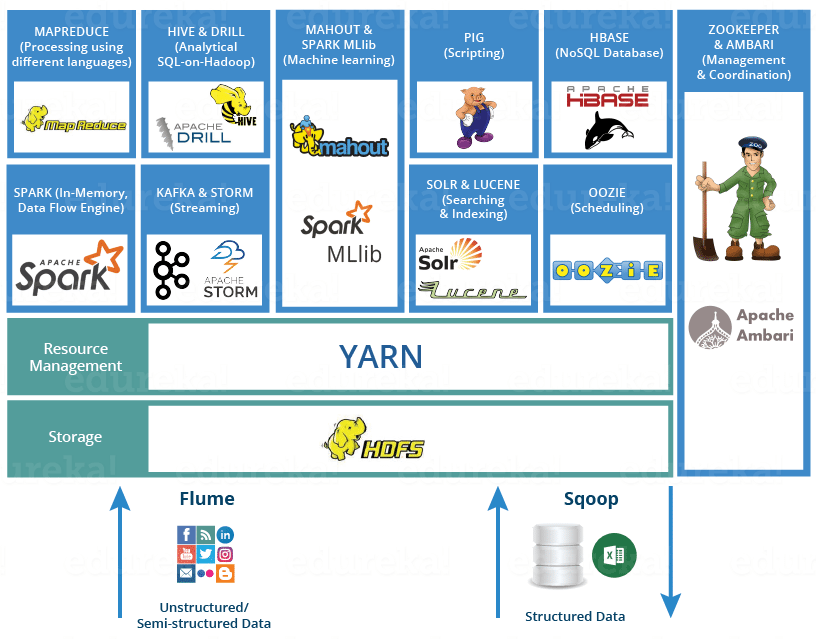

- HDFS (Hadoop Distributed File System): As the name suggests, it is the storage part of Hadoop, which stores the data in a distributed cluster. Being the base of Hadoop, knowledge of HDFS is a must to start working with Hadoop framework.
- YARN: YARN performs resource management by allocating resources to different applications and scheduling jobs. YARN was introduced in Hadoop 2.x. With the introduction of YARN, Hadoop became more flexible, efficient & scalable.
- MapReduce: MapReduce is a parallel processing paradigm which allows data to be processed parallelly on top of Distributed Hadoop Storage i.e. HDFS.
- PIG & HIVE: Hive is a data warehousing tool on top of HDFS. Hive caters to professionals from SQL backgrounds to perform analytics. Whereas Apache Pig is a high-level scripting language which is used for data transformation on top of Hadoop. Hive is generally used by the data analyst for creating reports whereas Pig is used by researchers for programming. Both are easy to learn if you are familiar with SQL.
- Flume & Sqoop: Flume is a tool which is used to import unstructured data to HDFS, whereas Sqoop is used to import & export structured data from RDBMS to HDFS.
- ZooKeeper: Zookeeper acts as a coordinator among the distributed services running in Hadoop environment. It helps in configuration management and synchronizing services.
- Oozie: Oozie is a scheduler which binds multiple logical jobs together and helps in accomplishing a complete task.
- Real-time processing Framework (Apache Spark): Real-time processing with quick actions is the need of the hour. Either it is a credit card fraud detection system or it is a recommendation system, each and every one of them needs real-time processing. It is very important for a Data Engineer to have knowledge of real-time processing frameworks. Apache Spark is a distributed real-time processing framework. It can be easily integrated with Hadoop leveraging HDFS. You can refer to Edureka’s Hadoop & Spark videos to gain comprehensive knowledge.
- Database architecture: One of the most prominent data sources are databases. It is critically important for a Data Engineer to understand database design & database architecture like 1-tier, 2-tier, 3-tier and n-tier. Data Models & Data Schema are also amongst the key skills which a Data Engineer should possess.
- SQL-based technologies (e.g. MySQL): Structured Query Language is used to structure, manipulate & manage data stored in databases. As Data Engineers work closely with the relational databases, they need to have a strong command on SQL. PL/SQL is also prominently used in the industry. PL/SQL provides procedural programming features on top of SQL.
- NoSQL technologies (e.g. Cassandra and MongoDB): As the requirements of organizations have grown beyond structured data, NoSQL databases have been introduced. It can store large volumes of structured, semi-structured & unstructured data with quick iteration and agile structure as per application requirements.


Some of the most prominently used databases are:
HBase is column-oriented NoSQL database on top of HDFS which is good for scalable & distributed big data stores. It is good for applications with optimized read & range based scan. It provides CP(Consistency & Partitioning) out of CAP.
Cassandra is a highly scalable database with incremental scalability. The best part of Cassandra is minimal administration and no single point in failure. It is good for applications with fast & random, read & writes. It provides AP(Available & Partitioning) out of CAP.
MongoDB is a document-oriented NoSQL database which is schema-free, i.e. your schema can evolve as the application grows. It also gives full index support for high performance & replication for fault tolerance. It has a master-slave architecture & provides CP out of CAP. It is rigorously used by the web application & semi-structured data handling.
- Python/R: Various programming languages can serve the same purpose. Knowledge of one programming language is enough, as the flavor changes but the logic remains the same. If you are a beginner, you can go ahead with Python as it is easy to learn due to its easy syntax and good community support. Whereas R has a steep learning curve which is developed by statisticians. R is mostly used by analyst & data scientist to perform data analytics.
- ETL/Data warehousing solutions(Talend, Informatica): Data Warehousing is very important when it comes to managing a huge amount of data coming in from heterogeneous sources where you need to apply ETL(Extract Transform Load). The Data Warehouse is used for data analytics & reporting, and is a very crucial part of Business Intelligence. It is very important for a Big Data Engineer to master a Data Warehousing or ETL tool. After mastering one, it becomes easy to learn new tools as the fundamental remains the same.


- UNIX, Linux, Solaris or MS Windows – Industry-wide various operating systems are used. Unix & Linux are some of the prominently used operating systems & Big Data Engineers need to master one of them at least.
Also Read :What is Azure Cosmos DB
Apart from the understanding of the complete data flow & business model, one of the motivations behind becoming a Data Engineer is the salary.
Unleash the power of distributed computing and scalable data processing with our Spark Course.
Big Data Engineer Jobs & Salaries
The average salary for “Big Data Engineer” ranges from $94,944 to $126,138 as per indeed. Whereas according to Glassdoor, the national average salary for a Senior Data Engineer is $181,773 in the United States.
As of Nov 2019, the total number of jobs listed in renowned job portals are:
- LinkedIn(IN) – 2,746 jobs
- LinkedIn(US) – 39,647 jobs
- Indeed -127,091 jobs
- Glassdoor(US) – 143,304 jobs
I hope this Big Data Engineer Skills blog has helped you in figuring out the right skill set that you need to become a Big Data Engineer. In our next Big Data Resume blog, we will be focusing on how to make an attractive Big Data Engineer Resume that will get you hired.
If you also want to learn Big data and make your career in it, then I would suggest you must take up the following Big Data Architect Masters Program.