





What is Big Data?
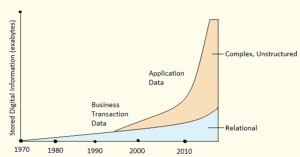
Big Data is a term used for collection of data sets that are large and complex, that is difficult to process using available database management tools or traditional data processing applications. The challenge includes capturing, curating, storing, searching, sharing, transferring, analyzing and visualization of data.
You can even check out the details of Big Data with the Microsoft Azure Data Engineering Certification Course (DP-203)
Common Big Data Customer Scenarios:
eBay – Web and Retailing:
- Recommended Engines
- Ad Targeting
- Search Quality
- Abuse and Click Fraud Detection
China Mobile – Telecommunications:
- Customer Churn Prevention
- Network Performance Optimization
- Calling Data Record (CDR) Analysis
- Analyzing Network to Predict Failure
JP Morgan Chase – Banks and Financial Services:
- Modeling True Risk
- Threat Analysis
- Fraud Detection
- Trade Surveillance
- Credit Scoring and Analysis
Sears – Retail:
- Point of Sales Transaction Analysis
- Customer Churn Analysis
- Sentiment Analysis
Case Study – Sears Holding Corporation
Sears is a retail store based in the United States. Sears was initially using traditional systems like Oracle Exadata, Teradata, SAS, etc. to store and process customer activity and sales data. Sears wanted to analyse the customer behaviour and know more about their buying patterns and come up with recommended products based on their behaviour. This requires big time data analysis capabilities.
You can get a better understanding with the Azure Data Engineering Certification in London.
Challenges Faced With Existing Data Analytics Structure & Steps To Overcome Them

The data collected at Instrumentation and Collection is huge in size and is stored in a Grid. As a result of the humongous amount of data, almost 90% of data was being archived and after certain point this data was simply too huge to handle in the storage grid. Consequently, you have limited amount of data to analyze. The limitations were that, at any point of time, only 10% of the data would be available to generate reports and gain meaningful insights from this data.

So, how did Sears overcome this limitation? Sears moved to a 300 Node Hadoop cluster to keep 100% of its data available for processing instead of the meagre 10% available with the previous data analysis structure, i.e. Non-Hadoop solution. Sears completely removed the ETL and storage grid from the data analysis structure. With the implementation of Hadoop, the entire data is now available for analysis.
With Hadoop, sears is now able to gain business insights and use it to their advantage, gather key early indicators that are of business value and able to perform precise analysis with more data.
Got a question for us? Mention them in the comments section and we will get back to you.
 Related Posts:
Related Posts:




































can you give me example architecture for the complete flow of big data analytics concept(how analysis done with hadoop eco systems )
Hi Ram, thanks for checking out the blog.