
Data Science with Python Certification Course
- 132k Enrolled Learners
- Weekend/Weekday
- Live Class
(49300)





 Copy Link!
Copy Link!In Machine Learning, a model’s performance is based on its predictions and how well it generalizes towards unseen, independent data. One way to measure a model’s accuracy is by keeping account of the bias and variance in the model. In this article, we will learn how bias-variance plays an important role in determining the authenticity of the model. The following topics are discussed in this article:
Any model in Machine Learning is assessed based on the prediction error on a new independent, unseen data set. Error is nothing but the difference between the actual output and the predicted output. To calculate the error, we do the summation of reducible and irreducible error a.k.a bias-variance decomposition.
Irreversible error is nothing but those errors that cannot be reduced irrespective of any algorithm that you use in the model. It is caused by unusual variables that have a direct influence on the output variable. So in order to make your model efficient, we are left with the reducible error that we need to optimize at all costs.
A reducible error has two components – Bias and Variance, presence of bias and variance influence the model’s accuracy in several ways like overfitting, underfitting, etc. Let us take a look at bias and variance to understand how to deal with the reducible error in Machine Learning.
Bias is basically how far we have predicted the value from the actual value. We say the bias is too high if the average predictions are far off from the actual values.
A high bias will cause the algorithm to miss a dominant pattern or relationship between the input and output variables. When the bias is too high, it is assumed that the model is quite simple and does not fathom the complexity of the data set to determine the relationship and thus, causing underfitting.
Transform yourself into a highly skilled professional and land a high-paying job with the Artificial Intelligence Course.
On an independent, unseen data set or a validation set. When a model does not perform as well as it does with the trained data set, there is a possibility that the model has a variance. It basically tells how scattered the predicted values are from the actual values.
A high variance in a data set means that the model has trained with a lot of noise and irrelevant data. Thus causing overfitting in the model. When a model has high variance, it becomes very flexible and makes wrong predictions for new data points. Because it has tuned itself to the data points of the training set.
Let us also try to understand the concept of bias-variance mathematically. Let the variable that we are predicting to be Y and the other independent variables to be X. Now let us assume there is a relationship between the two variables such that:
Y = f(X) + e
In the above equation, Here e is the estimated error with a mean value 0. When we make a classifier using algorithms like linear regression, SVM, etc, the expected squared error at point x will be:
err(x) = Bias2 + Variance + irreducible error
Let us also understand how the Bias-Variance will affect a Machine Learning model’s performance.
We can put the relationship between bias-variance in four categories listed below:
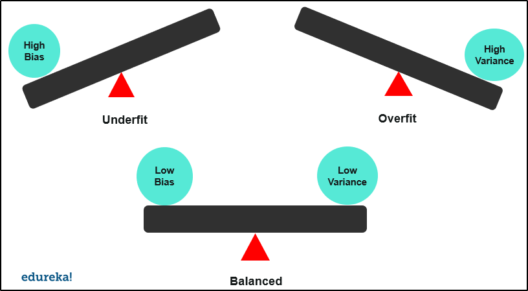
Although detecting bias and variance in a model is quite evident. A model with high variance will have a low training error and high validation error. And in the case of high bias, the model will have high training error and validation error is the same as training error.
While detecting seems easy, the real task is to reduce it to the minimum. In that case, we can do the following:
Now that we know what is bias and variance and how it affects our model, let us take a look at a bias-variance trade-off.
Finding the right balance between the bias and variance of the model is called the Bias-Variance trade-off. It is basically a way to make sure the model is neither overfitted or underfitted in any case.
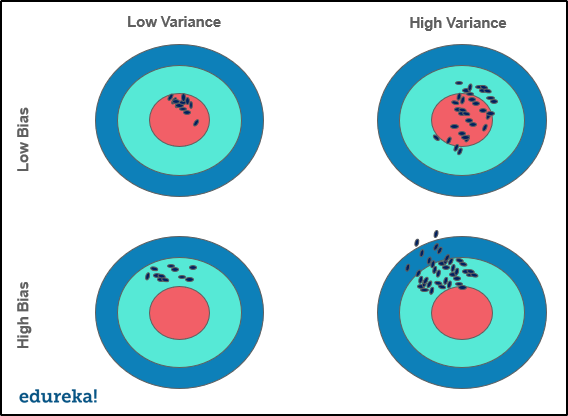
If the model is too simple and has very few parameters, it will suffer from high bias and low variance. On the other hand, if the model has a large number of parameters, it will have high variance and low bias. This trade-off should result in a perfectly balanced relationship between the two. Ideally, low bias and low variance is the target for any Machine Learning model.
In any Machine Learning model, a good balance between the bias and variance serves as a perfect scenario in terms of predictive accuracy and avoiding overfitting, underfitting altogether. An optimal balance between the bias and variance, in terms of algorithm complexity, will ensure that the model is never overfitted or underfitted at all.
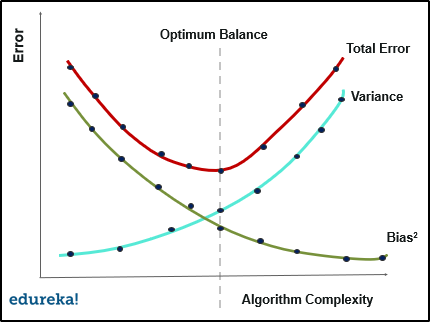
The mean squared error in a statistical model is considered as the sum of squared bias and variance and variance of error. All this can be put inside a total error where we have bias, variance and irreducible error in a model.
Let us understand how we can reduce the total error with the help of a practical implementation.
We have created a linear regression classifier in the Linear Regression in Machine Learning article on Edureka using the diabetes data set in the datasets module of scikit learn library.
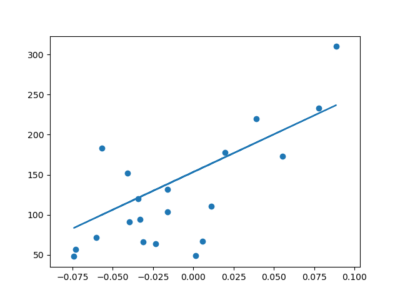
When we evaluated the mean squared error of the classifier, we got a total error around 2500.

To reduce the total error, we fed more data to the classifier and in return the Mean squared error was reduced to 2000.

It is a simple implementation of reducing the total error by feeding more training data to the model. Similarly we can apply other techniques to reduce the error and maintain a balance between bias and variance for an efficient Machine Learning model.
This brings us to the end of this article where we have learned Bias-Variance in Machine Learning with its implementation and use case. I hope you are clear with all that has been shared with you in this tutorial.
With immense applications and easier implementations of Python with data science, there has been a significant increase in the number of jobs created for data science every year. Enroll for Edureka’s Data Science with Python and get hands-on experience with real-time industry projects along with 24×7 support, which will set you on the path of becoming a successful Data Scientist,
We are here to help you with every step on your journey and come up with a curriculum that is designed for students and professionals who want to be a Machine Learning Engineer. The course is designed to give you a head start into Python programming and train you for both core and advanced Python concepts along with various Machine learning Algorithms like SVM, Decision Tree, etc.
If you come across any questions, feel free to ask all your questions in the comments section of “Bias-Variance In Machine Learning” and our team will be glad to answer.
Related Post: bias in generative AI models








































 Thank you for registering Join Edureka Meetup community for 100+ Free Webinars each month JOIN MEETUP GROUP
Thank you for registering Join Edureka Meetup community for 100+ Free Webinars each month JOIN MEETUP GROUP