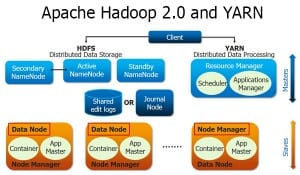
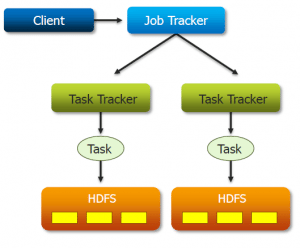
HBase is an open source, non-relational, distributed database modelled after Google’s BigTable and is written in Java. It is developed by Apache Software Foundation and is a part of Apache Hadoop project. HBase runs on top of HDFS (Hadoop Distributed Filesystem), providing BigTable-like capabilities for Hadoop.
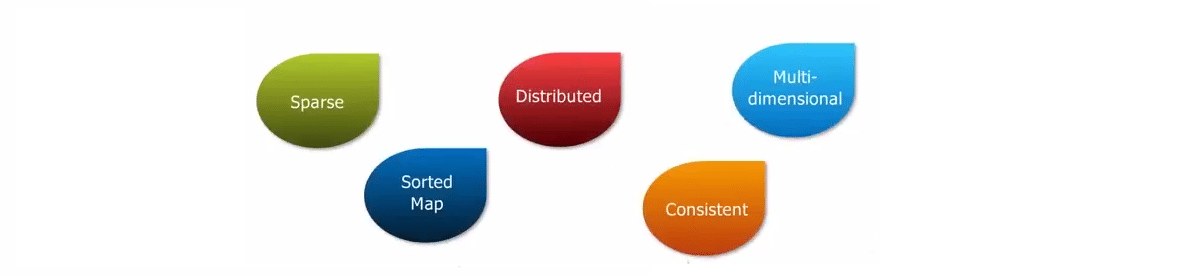
HBase is a key/ value store. HBase is specifically Sparse, Distributed, Multi-dimensional, sorted Maps and consistent.
The best way to become a Data Engineer is by getting the Azure Data Engineering Certification in Bangalore.
HBase can be used in the following scenarios:
- Huge Data
- Fast Random Access
- Structured Data
- Variable Schema
- Need of Compression
- Need of Sharding
NoSQL Landscape:
The NoSQL databases can be classified as follows:
- Key-Value Stores – Dynamo (Amazon), Voldemort (LinkedIn), Citrusleaf, Membasae, Riak, Tokyo Cabinet, etc.
- Big Table Clones – BigTable(Google), Cassandra, HBase, Hypertable, etc.
- Document Database – CouchOne, MongoDB, Terrastore, OrientDB, etc.
- Graph Databases – FlockDB (Twitter), AllegroGraph, DEX, InfoGRid, Neo4J, Sones, etc.
You can get a better understanding with the Azure Data Engineering Certification.
Features of HBase:
 History of HBase:
History of HBase:
 History of HBase:
History of HBase:
Basics of HBase:
The following keywords are required to gain an understanding of the subjects that forms the core foundation of HBase:
- Rowkey
- Column Family
- Column
- Timestamp
An HBase table contains column families, which are the logical and physical grouping of columns. Column families contain columns with time stamped versions. Columns only exist when they are inserted. All column associates of the same column family have the same column family prefix. Each column value is identified by a key. The row key is the implicit primary key. The Rows are sorted by the row key.
Become a master of data architecture and shape the future with our comprehensive Data Architect Certification.
Got a question for us? Mention them in the comments section and we will get back to you.
Related Posts: