
Advanced Certification in Agentic AI Engineer ...
- 68k Enrolled Learners
- Weekend
- Live Class
(45931)





 Copy Link!
Copy Link!Backpropagation is a supervised learning algorithm, for training Multi-layer Perceptrons (Artificial Neural Networks).
I would recommend you to check out the following Deep Learning Certification blogs too:
But, some of you might be wondering why we need to train a Neural Network or what exactly is the meaning of training.
While designing a Neural Network, in the beginning, we initialize weights with some random values or any variable for that fact.
Now obviously, we are not superhuman. So, it’s not necessary that whatever weight values we have selected will be correct, or it fits our model the best.
Okay, fine, we have selected some weight values in the beginning, but our model output is way different than our actual output i.e. the error value is huge.
Now, how will you reduce the error?
Basically, what we need to do, we need to somehow explain the model to change the parameters (weights), such that error becomes minimum.
Let’s put it in an another way, we need to train our model.
One way to train our model is called as Backpropagation. Consider the diagram below:
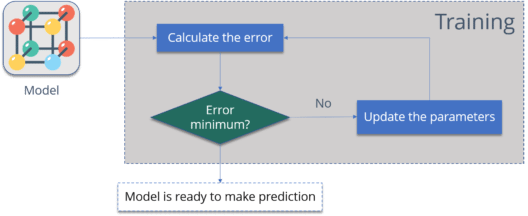
Let me summarize the steps for you:
I am pretty sure, now you know, why we need Backpropagation or why and what is the meaning of training a model.
Now is the correct time to understand what is Backpropagation.
The Backpropagation algorithm looks for the minimum value of the error function in weight space using a technique called the delta rule or gradient descent. The weights that minimize the error function is then considered to be a solution to the learning problem.
Let’s understand how it works with an example:
You have a dataset, which has labels.
Consider the below table:
| Input | Desired Output |
| 0 | 0 |
| 1 | 2 |
| 2 | 4 |
Now the output of your model when ‘W” value is 3:
| Input | Desired Output | Model output (W=3) |
| 0 | 0 | 0 |
| 1 | 2 | 3 |
| 2 | 4 | 6 |
Notice the difference between the actual output and the desired output:
| Input | Desired Output | Model output (W=3) | Absolute Error | Square Error |
| 0 | 0 | 0 | 0 | 0 |
| 1 | 2 | 3 | 1 | 1 |
| 2 | 4 | 6 | 2 | 4 |
Let’s change the value of ‘W’. Notice the error when ‘W’ = ‘4’
| Input | Desired Output | Model output (W=3) | Absolute Error | Square Error | Model output (W=4) | Square Error |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 1 | 2 | 3 | 1 | 1 | 4 | 4 |
| 2 | 4 | 6 | 2 | 4 | 8 | 16 |
Now if you notice, when we increase the value of ‘W’ the error has increased. So, obviously there is no point in increasing the value of ‘W’ further. But, what happens if I decrease the value of ‘W’? Consider the table below:
| Input | Desired Output | Model output (W=3) | Absolute Error | Square Error | Model output (W=2) | Square Error |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 1 | 2 | 3 | 2 | 4 | 3 | 0 |
| 2 | 4 | 6 | 2 | 4 | 4 | 0 |
Now, what we did here:
So, we are trying to get the value of weight such that the error becomes minimum. Basically, we need to figure out whether we need to increase or decrease the weight value. Once we know that, we keep on updating the weight value in that direction until error becomes minimum. You might reach a point, where if you further update the weight, the error will increase. At that time you need to stop, and that is your final weight value.
Consider the graph below:
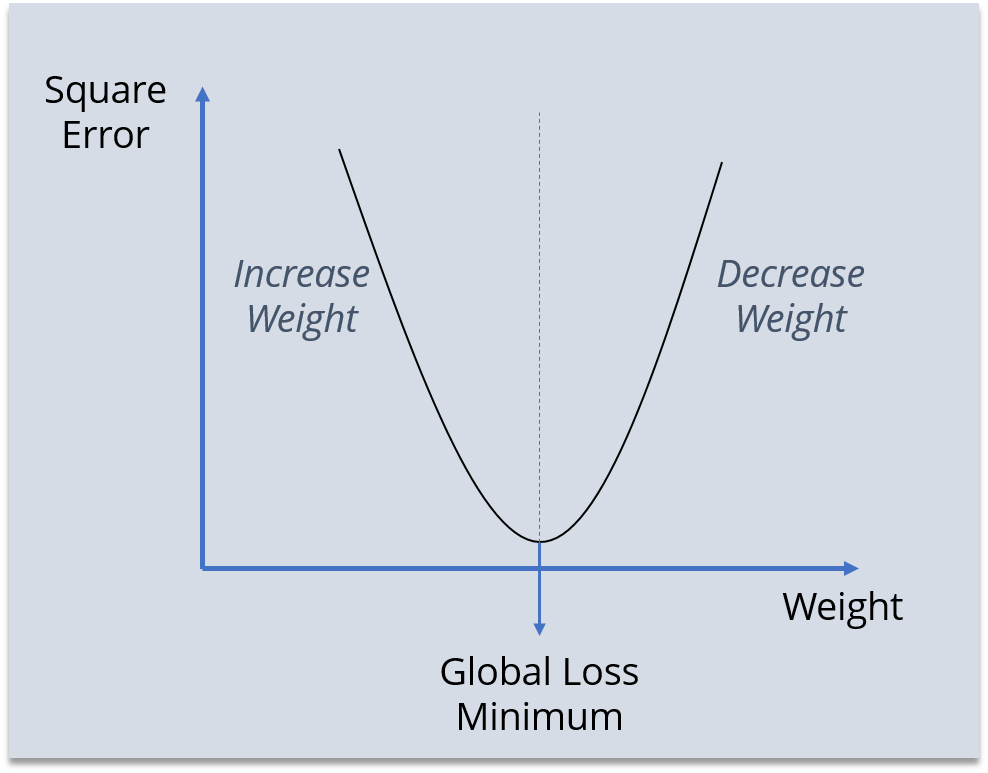
We need to reach the ‘Global Loss Minimum’.
This is nothing but Backpropagation.
Let’s now understand the math behind Backpropagation.
Consider the below Neural Network:
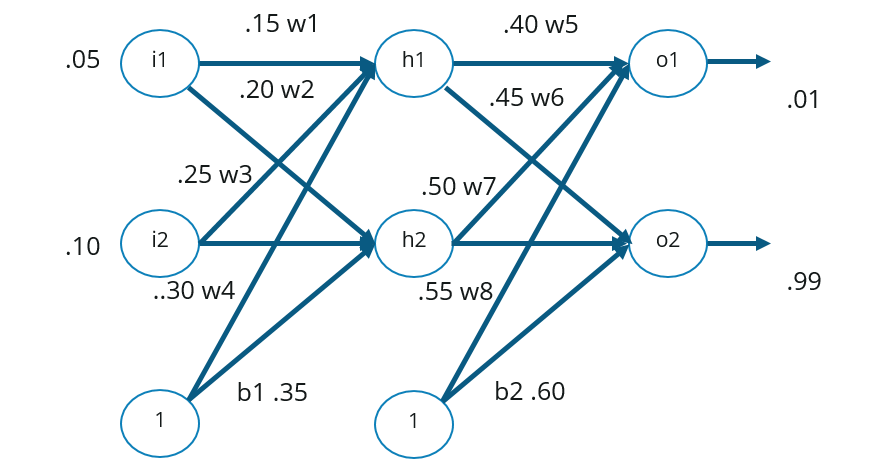
The above network contains the following:
Below are the steps involved in Backpropagation:
We will start by propagating forward.
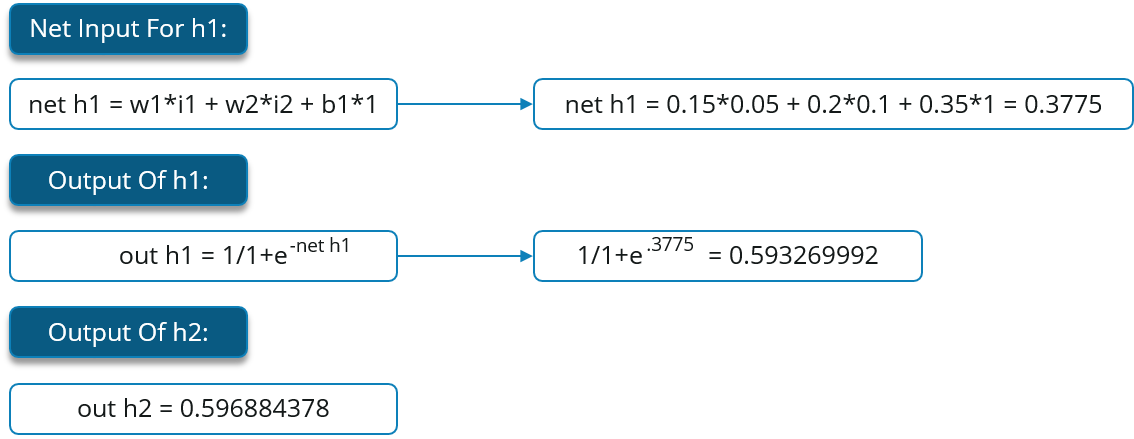
We will repeat this process for the output layer neurons, using the output from the hidden layer neurons as inputs.
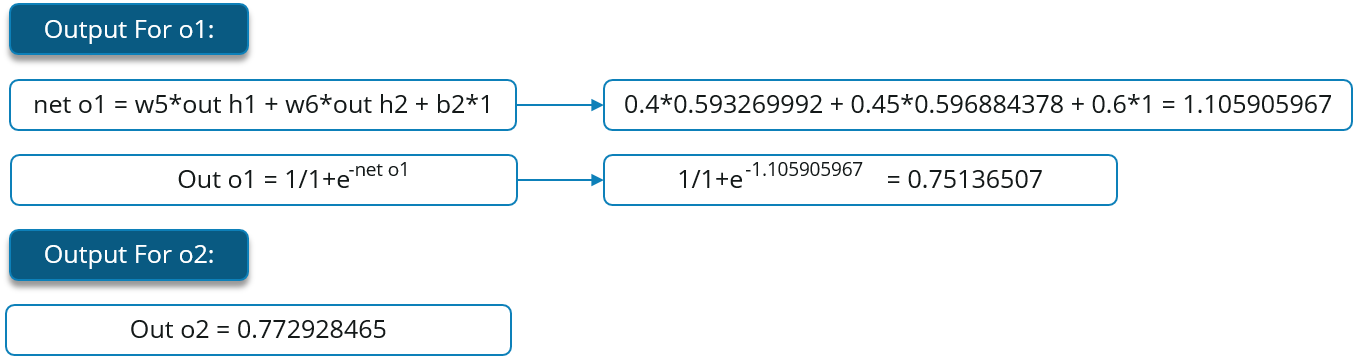
Now, let’s see what is the value of the error:
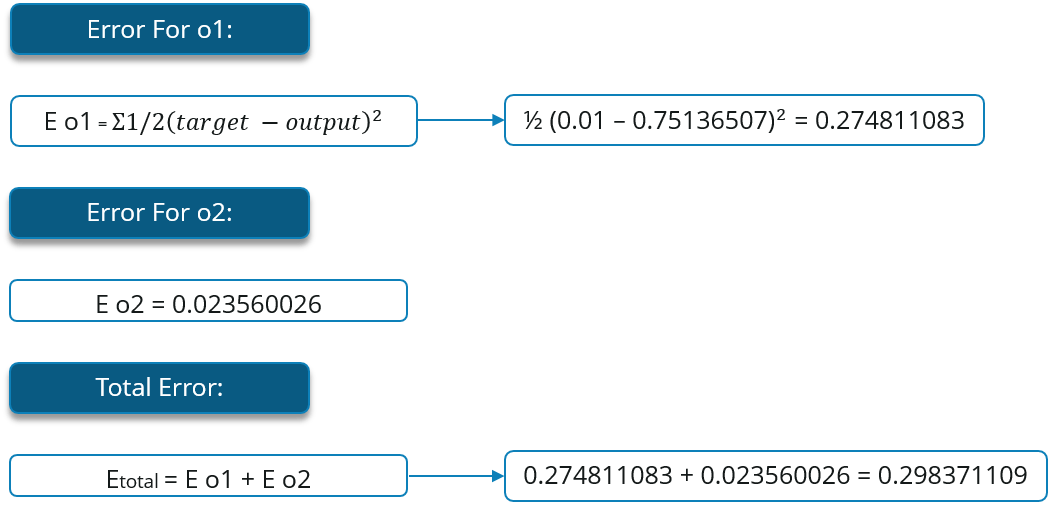
Now, we will propagate backwards. This way we will try to reduce the error by changing the values of weights and biases.
Consider W5, we will calculate the rate of change of error w.r.t change in weight W5.

Since we are propagating backwards, first thing we need to do is, calculate the change in total errors w.r.t the output O1 and O2.
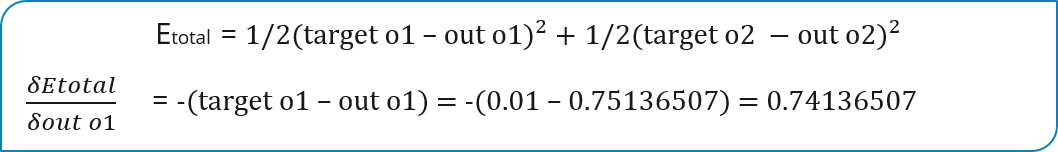
Now, we will propagate further backwards and calculate the change in output O1 w.r.t to its total net input.
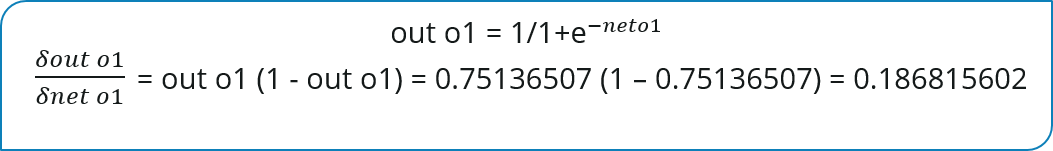
Let’s see now how much does the total net input of O1 changes w.r.t W5?

Now, let’s put all the values together:
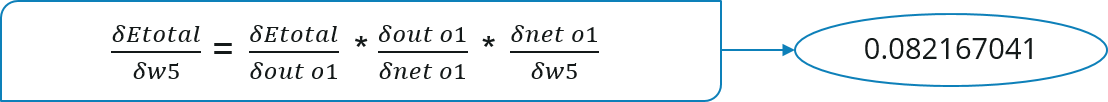
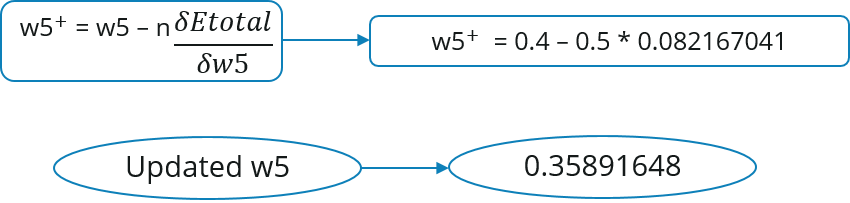
Let’s calculate the updated value of W5:
Well, if I have to conclude Backpropagation, the best option is to write pseudo code for the same.
initialize network weights (often small random values) do forEach training example named ex prediction = neural-net-output(network, ex) // forward pass actual = teacher-output(ex) compute error (prediction - actual) at the output units compute {displaystyle Delta w_{h}} for all weights from hidden layer to output layer // backward pass compute {displaystyle Delta w_{i}} for all weights from input layer to hidden layer // backward pass continued update network weights // input layer not modified by error estimate until all examples classified correctly or another stopping criterion satisfied return the network
I hope you have enjoyed reading this blog on Backpropagation, check out the Deep Learning with TensorFlow Training by Edureka, a trusted online learning company with a network of more than 250,000 satisfied learners spread across the globe. The Edureka Deep Learning with TensorFlow Certification Training course helps learners become expert in training and optimizing basic and convolutional neural networks using real time projects and assignments along with concepts such as SoftMax function, Auto-encoder Neural Networks, Restricted Boltzmann Machine (RBM).
Got a question for us? Please mention it in the comments section and we will get back to you.









 Thank you for registering Join Edureka Meetup community for 100+ Free Webinars each month JOIN MEETUP GROUP
Thank you for registering Join Edureka Meetup community for 100+ Free Webinars each month JOIN MEETUP GROUP





Great post! More complex mathematical description of backpropagation algorithm.
What is n in the last formulae of updated value of w5 and how is it 0.5
Do you have any video which explains the same?
A very nice article – made it look very simple – thanks
Hey Satya, thank you for appreciating our work. Do browse through our other blogs and let us know how you liked our content. Cheers :)
amazing article easy to understand. thanks for writing!
Hey @disqus_nX9E2gADqb:disqus Thank you for appreciating our work. Do check out our website to know more about the Deep Learning courses we provide: https://www.edureka.co/ai-deep-learning-with-tensorflow
Hope this helps :)