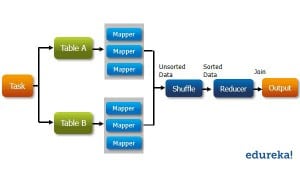
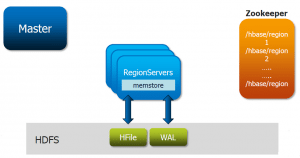
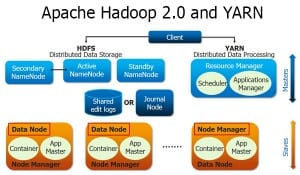
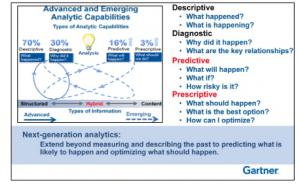
Both Microsoft Azure Synapse Analytics and Databricks are strong contenders in the cloud space.
For Spark users, the main distinction between the two lies in optimization and language support. Synapse has an open-source Spark version with built-in support for .NET – a big plus for those comfortable with C# or F#, and Visual Basic. Databricks runs on an optimized Spark version and gives you the option to select GPU-enabled clusters, making it more suitable for complex data processing.
In this Azure Synapse vs. Databricks comparison post, we will break down the core concepts and differences between these two to help you select the best fit for your intended use.
Azure Synapse vs. Databricks – Which One Is Better and Why?
Although Databricks gives you a more streamlined experience, it comes at the cost of some functionalities (lack of no-code ML). Synapse, with granular access control and easy integration with other Microsoft tools like Azure Active Directory and Power BI, is better for designing the serving layer.
New to Azure DB and Synapse. No worries. let’s start with the basics and then we will move onto in-depth side-by-side analysis.
What is Azure Synapse?
Azure Synapse is Microsoft’s cloud-based analytics powerhouse. It’s a Swiss Army knife for data pros, merging data integration, warehousing, and big data analytics into one sleek package. In other words, Synapse lets users ingest, prepare, manage, and serve data for immediate BI and machine learning needs.
At its core, Azure Synapse combines the power of SQL and Apache Spark technologies. The SQL component offers both serverless and dedicated resource models, allowing you to handle unpredictable workloads with the always-available serverless endpoint or reserve processing power for predictable workloads using dedicated SQL pools.
On the other hand, thanks to the Spark component, you can perform data preparation, data engineering, ETL, and machine learning tasks using industry-standard Apache Spark.
Key Advantages of Azure Synapse
No Code AI or Analytics Capabilities
Azure Synapse takes a significant leap forward in democratizing data analytics and AI by offering robust no-code options. Through an intuitive drag-and-drop interface, users can create sophisticated data pipelines, perform complex transformations, and even implement AI models without writing a single line of code.
But it doesn’t stop there. Synapse goes the extra mile by integrating Azure AI directly into its Studio environment. Users can extract insights from handwritten forms, transcribe and analyze audio recordings, or derive meaning from video content, all without the need for a data science degree or coding expertise.
Scalable Compute
Synapse offers flexible compute options to fit your needs. Choose between serverless or dedicated SQL pools for a cost-effective approach. Resources can dynamically scale up or down based on demand, ensuring optimal performance during peak times and cost savings during lulls.
The platform’s massive parallel processing (MPP) architecture empowers you with high-performance querying of even massive datasets.
Polyglot Data Processing
Synapse speaks your language! It supports multiple programming languages including T-SQL, Spark SQL, Python, and Scala. This flexibility allows your data team to leverage their existing skills and preferred tools, boosting productivity. Collaboration across teams with different language expertise is also a breeze.
Advanced Security Features
Security is top-notch with Synapse. You can be confident about your data security with features like column-level security, dynamic data masking, and automated threat detection.
Azure Synapse offers a second layer of encryption for data at rest using customer-managed keys stored in Azure Key Vault, providing enhanced data security and control over key management.
Cost-Effective Data Lake Integration
Azure Synapse lets you ditch the traditional separation between SQL and Spark for data lake exploration. Here’s the magic: you can directly analyze various file formats like Parquet, CSV, TSV, and JSON stored right there in the data lake. No need to move the data around first.
By letting you query data directly in the lake without the need for movement, Synapse cuts down the storage costs and eliminates data duplication. This capability fosters a more flexible data architecture where data can be processed and analyzed in its raw form.
Limitations of Azure Synapse
- Limited Language Support: While Synapse supports multiple languages, its support is not as extensive as some competitors. This can be restrictive for teams with diverse programming language preferences or specific language requirements for certain tasks.
- Complexity for Small-Scale Operations: The learning curve and setup complexity of Synapse outweigh the benefits for projects that don’t require its full capabilities.
What Is Azure Databricks?
With Databricks, you can simplify DevOps tasks for data teams.
It creates a collaborative workspace for data engineers, scientists, and analysts to process and analyze large-scale data using SQL, Python, Scala, and R.
Under the hood, Azure Databricks operates on a control plane and a compute plane. The control plane manages the backend services, while the compute plane processes the data. It provides both serverless and classic compute options, with the serverless plane running within a network boundary for enhanced security and isolation.
The platform is packed with features like automated cluster management, interactive notebooks, and built-in machine-learning libraries. You can easily integrate Databricks with other Azure services, e.g., such as Azure Data Lake Storage, Azure Blob Storage, and Azure Active Directory, to build end-to-end data pipelines.
Key Advantages of Azure Databricks
Cloud-Agnostic Architecture
While integrated with Azure, Databricks isn’t confined to a single cloud ecosystem. If you don’t want to run Databricks on Azure, that’s fine. Use Databricks on AWS or GCP instead. This flexibility prevents vendor lock-in and allows businesses to leverage multi-cloud strategies for optimal performance and cost efficiency.
Unified Analytics Workspace
The unified ecosystem allows data engineers, scientists, and analysts to work together without hiccups. Its interactive notebooks support multiple languages and enable real-time collaboration, code sharing, and version control. This unified approach accelerates project delivery and fosters innovation across data teams.
Advanced Machine Learning Capabilities
With features like MLflow for experiment tracking and model management, Databricks streamlines the entire machine-learning lifecycle. It supports both traditional ML algorithms and deep learning frameworks, catering to a wide range of AI applications.
Lakehouse Architecture Pioneer
Databricks brought the best elements of data lakes and data warehouses to create Lakehouse. With Lakehouse, organizations that handle both structured and unstructured data efficiently while enjoying the performance and reliability traditionally associated with data warehouses.
Limitations of Databricks:
- Steep Learning Curve: Despite its user-friendly interface, Databricks requires a solid understanding of Apache Spark for optimal use. Debugging, especially for SparkR scripts, can be quite a challenge at times.
- Cluster Management Challenges: Databricks clusters frequently exhibit unpredictable behavior. It can be quite a headache during time-sensitive analyses.
Azure Synapse vs. Databricks – Detailed Comparison
Now that we have dissected the architecture of both Synapse and Databricks, let’s go over the key distinctions between these two platforms:
Core Architecture and Design Philosophy
Tl;dr: For a unified environment with ease of use, choose Synapse. If you have experienced Spark users who require maximum flexibility and control, Databricks might be a better fit.
The way these platforms are built fundamentally shapes their capabilities. Azure Synapse leverages a unified architecture, seamlessly integrating SQL Data Warehouse with Apache Spark.
This means you can query structured data in your data warehouse and perform complex analytics on unstructured or semi-structured data in your data lake using the same platform.
Databricks, on the other hand, takes a more modular approach. It relies on Apache Spark as its core engine, offering separate clusters for SQL and data science workloads. This can provide greater flexibility for experienced Spark users but requires some additional configuration and management overhead.
Financial Considerations and Service Reach
Tl;dr: Synapse offers more flexible pricing options, while Databricks uses a straightforward consumption model. Databricks is generally a more cost-effective for large-scale operations.
However, depending on your budget and usage patterns, the flexible pricing options of Synapse might be a better alternative for some organizations.
When considering costs, Azure Synapse presents flexible pricing options with pay-as-you-go and reserved capacity models, but costs can unexpectedly spike. Databricks also operates on a pay-as-you-go model, with additional reserved instance options.
While both services guarantee high availability with robust SLAs, Databricks often stands out for its cost-efficiency in large-scale data operations. Are predictable costs more important to you, or are you prepared to optimize for performance regardless of price fluctuations?
AI and Predictive Analytics Capabilities
Tl;dr: For user-friendly ML development with built-in Azure integration, choose Synapse. If your team consists of experienced Spark users who require advanced ML flexibility, Databricks is the way to go.
Both platforms excel in machine learning, but their methodologies differ. Synapse incorporates Azure AI directly into its studio, enabling AI applications across various data types with minimal coding. Databricks, rooted in data science, provides a more hands-on experience, featuring MLflow integration and support for diverse ML libraries.
Notebooks and Version Control
Tl;dr: Databricks is the clear winner here with its superior collaboration features and version control.
For data exploration and code development, both systems provide notebook interfaces. Synapse delivers a Jupyter-esque experience within its integrated environment.
Databricks enhances this concept with advanced team collaboration features and smooth Git integration for version control. Ultimately, the choice between notebook environments depends on your team’s familiarity and preferred functionalities.
Data Security and Regulatory Compliance
Tl:dr: Both platforms are designed to meet industry standards like HIPAA, GDPR, and FedRAMP, Synapse might offer a slight edge due to its native integration with Azure security features.
Azure Active Directory for identity management, role-based access control, and column-level security. Synapse also offers a second layer of encryption for data at rest using customer-managed keys stored in Azure Key Vault. This gives organizations greater control over their data encryption.
In contrast, Azure Databricks inherits many of Azure’s security features, including Azure AD integration and network isolation. However, Databricks’ security model is more focused on the workspace level, with less granular control compared to Synapse’s data warehouse-centric approach.
Computational Muscle and Adaptability
Tl;dr: The choice depends on your data processing requirements. Synapse is best suited for SQL processing, while Databricks is better engineered for Spark-based big data tasks.
In this regard, both contenders pack quite a punch. Synapse shines with its Massively Parallel Processing (MPP) architecture for SQL workloads and integrated Spark for big data tasks. Databricks, built on Spark’s foundation, boasts an optimized runtime and Delta Engine for enhanced performance.
Ecosystem Compatibility and Extensibility
Tl;dr: If you are looking for flexibility to switch between different cloud providers, Databricks would be the clear choice. That said, Synapse is a better choice for broad data integration within the Azure ecosystem.
Owing to Synapse’s deep-rooted connection within the Azure Ecosystem, the compatibility with other Azure services is impeccable – like peas in a pod! Databricks is not connected to one cloud vendor. This means you can run it on both AWS and GCP as well, in case you don’t want to run it on Azure.
Looking to upskill as a data engineer? Check out the strategically curated Data Engineering courses by Edureka to explore the features of top data analytics platforms like Azure Databricks and Synapse.
FAQs
1. Is Azure Synapse an ETL tool?
Ans. Yes, it is a very capable cloud-based ETL tool designed to build data pipelines for big data analytics and data warehousing.
2. What is the difference between Azure DB and Azure Synapse?
Ans. Azure Synapse offers an open-source Spark version with built-in .NET support, ideal for those familiar with the .NET framework. Databricks, on the other hand, provides an optimized Spark version
3. Is Azure Synapse the same as Azure Data Factory?
Ans. No, they’re different services. Azure Synapse incorporates Data Factory’s capabilities while DB comes with Data Factory features plus additional analytics tools.
Conclusion
The age of Big Data is upon us! Are you ready? If you want to make a career as a data engineer, having a solid understanding of both DB and synapse is going to come in handy. We hope this Azure Synapse vs Databricks comparison post helped you figure out the right choice for your specific use case.