The other day, I was looking at how our company handles data, and honestly, it seemed pretty disorganized. Customer information was in one place, sales data in another, and marketing stats were scattered everywhere. I started wondering how big companies manage to bring all their data together in a way that actually works.
That led me to explore ETL. ETL is a way to move data from the source to a data warehouse. It seems easy, but it may get very hard, especially when you have a lot of data from numerous places.
That’s when I discovered AWS Glue.
It’s a serverless tool from Amazon that makes the whole ETL process much easier. It automatically discovers your data, cleans it up, and moves it to the right place. AWS Glue helps businesses organize their data so they can make better choices.
In this blog, I’ll explain what AWS Glue is, why it’s a game-changer for data teams, and how it helps businesses make better use of their data without all the usual ETL headaches.
So, let us begin with our first topic.
What is AWS Glue?
AWS Glue is a fully managed ETL service. It makes it simple and cost-effective to categorize data, clean it, enrich it, and move it swiftly and reliably between various data stores.
It comprises of components such as a central metadata repository known as the AWS Glue Data Catalog, an ETL engine that automatically generates Python or Scala code, and a flexible scheduler that handles dependency resolution, job monitoring, and retries.
AWS Glue is serverless, which means that there’s no infrastructure to set up or manage.
AWS Glue Features
Now that we’ve gone over the basics, let’s look at the robust features that make AWS Glue a great tool for combining data.
AWS Glue offers these capabilities:
- Run ETL jobs as newly collected data arrives – For example, AWS Glue enables automatic execution of ETL jobs whenever new data is added to your Amazon Simple Storage Service (S3) buckets.
- Data Catalog – Utilize it to quickly explore and search various AWS datasets without having to relocate the data. The cataloged data is readily searchable and can be queried using Amazon Athena, Amazon Redshift Spectrum, and Amazon EMR.
- AWS Glue Studio – It facilitates no-code ETL tasks. AWS Glue Studio allows you to visually construct, execute, and oversee AWS Glue ETL jobs. You can move and transform data using a drag-and-drop interface. AWS Glue automatically generates the code.
- Multi-method support – Accommodates a range of data processing techniques and workloads, including ETL, ELT, batch, and streaming. Additionally, you can utilize your preferred method, whether by dragging and dropping, coding, or linking to your notebook.
- AWS Glue Data Quality – Automatically establishes, oversees, and checks data quality rules. This guarantees high-quality data across your data lakes and pipelines.
- AWS Glue DataBrew – This allows you to explore and engage with data straight from your data lake, data warehouses, and databases. You can accomplish this using Amazon S3, Amazon Redshift, AWS Lake Formation, Amazon Aurora, and Amazon Relational Database Service (RDS).
DataBrew also has more than 250 prebuilt transformations that can help you automate operations like filtering out bad data, fixing wrong numbers, and making sure that formats are the same.
AWS Glue has capabilities that allow you design strong and efficient data pipelines, so you can focus on insights instead of wrangling data.
What are the Components of AWS Glue?
Understanding AWS Glue main parts will help you completely understand how it works. Let’s look at the main pieces that work together to make your ETL operations operate.
Behind the scenes, you’ll discover these AWS Glue components:
- The console – The AWS Glue console serves as the platform for defining and orchestrating your workflow. From this interface, you can utilize various API operations to carry out tasks, including defining AWS Glue objects, editing transformation scripts, and setting up events or job schedules for triggers.
- AWS Glue Data Catalog – This serves as a central repository for your metadata, designed to store information in metadata tables, each linked to a specific data store. Essentially, it functions as an index for your data schema, location, and runtime metrics, which help in identifying the targets and sources for your ETL (Extract, Transform, Load) processes.
- Job Scheduling System – Conversely, the job scheduling system is designed to assist in automating and linking your ETL pipelines. It features a versatile scheduler that can configure event-based triggers and execution timelines for jobs.
- Script – The AWS Glue service creates a script to transform your data. You also have the option to upload your script through the AWS Glue API or console. These scripts extract data from your source, transform it, and load it into your target location. In AWS Glue, these scripts operate within an Apache Spark environment.
- Connection – This describes a Data Catalog object that includes properties needed to connect to a specific data store.
- Data store – Here is where your data is stored permanently, including relational databases and Amazon S3.
- Data source – This is a data repository that acts as input for a transformation or procedure.
- Data target – This is the storage where a process records data.
- Transform – Relates to the coding logic applied to alter your data’s format.
- ETL Engine – The ETL engine of AWS Glue is responsible for generating ETL code. It automatically produces this code in Python or Scala, and even offers options for customization.
- Crawler and Classifier – A crawler retrieves data from the source using either integrated or custom classifiers. This component of AWS Glue creates or utilizes metadata tables that are pre-defined in the data catalog.
- Job – This is the business logic responsible for executing an ETL task in AWS Glue. Internally, Apache Spark, using either Python or Scala, implements this business logic.
- Trigger – This initiates the ETL job either at a predetermined time or as needed.
- Development endpoint – This establishes a development environment where your ETL job script can be developed, tested, and debugged.
- Database – It generates or connects to source and target databases.
- Table – You can set up one or more tables in the database for the source and target.
- Notebook server – A web platform for executing PySpark commands, which is a Python variant used in ETL programming. Utilizing AWS Glue extensions, you can execute PySpark commands on a notebook server.
These components work together seamlessly, providing a comprehensive environment for your ETL needs and streamlining your data integration processes.
When Should I Use AWS Glue?
1. To build a data warehouse to organize, cleanse, validate, and format data.
You can transform as well as move AWS Cloud data into your data store.
You can also load data from disparate sources into your data warehouse for regular reporting and analysis.
By storing it in a data warehouse, you integrate information from different parts of your business and provide a common source of data for decision making.
2. When you run serverless queries against your Amazon S3 data lake.
AWS Glue can catalog your Amazon Simple Storage Service (Amazon S3) data, making it available for querying with Amazon Athena and Amazon Redshift Spectrum.
With crawlers, your metadata stays in synchronization with the underlying data. Athena and Redshift Spectrum can directly query your Amazon S3 data lake with the help of the AWS Glue Data Catalog.
With AWS Glue, you access as well as analyze data through one unified interface without loading it into multiple data silos.
3. When you want to create event-driven ETL pipelines
You can run your ETL jobs as soon as new data becomes available in Amazon S3 by invoking your AWS Glue ETL jobs from an AWS Lambda function.
You can also register this new dataset in the AWS Glue Data Catalog considering it as part of your ETL jobs.
4. To understand your data assets.
You can store your data using various AWS services and still maintain a unified view of your data using the AWS Glue Data Catalog.
View the Data Catalog to quickly search and discover the datasets that you own, and maintain the relevant metadata in one central repository.
The Data Catalog also serves as a drop-in replacement for your external Apache Hive Metastore.
AWS Glue Tutorial
Key Benefits of AWS Glue
1. Less hassle
 AWS Glue is integrated across a very wide range of AWS services. AWS Glue natively supports data stored in Amazon Aurora and all other Amazon RDS engines, Amazon Redshift, and Amazon S3, along with common database engines and databases in your Virtual Private Cloud (Amazon VPC) running on Amazon EC2.
AWS Glue is integrated across a very wide range of AWS services. AWS Glue natively supports data stored in Amazon Aurora and all other Amazon RDS engines, Amazon Redshift, and Amazon S3, along with common database engines and databases in your Virtual Private Cloud (Amazon VPC) running on Amazon EC2.2. Cost-effective
AWS Glue is serverless. There is no infrastructure to provision or manage. AWS Glue handles provisioning, configuration, and scaling of the resources required to run your ETL jobs on a fully managed, scale-out Apache Spark environment. You pay only for the resources that you use while your jobs are running.3. More power
 AWS Glue automates a significant amount of effort in building, maintaining, and running ETL jobs. It crawls your data sources, identifies data formats as well as suggests schemas and transformations. AWS Glue automatically generates the code to execute your data transformations and loading processes.
AWS Glue automates a significant amount of effort in building, maintaining, and running ETL jobs. It crawls your data sources, identifies data formats as well as suggests schemas and transformations. AWS Glue automatically generates the code to execute your data transformations and loading processes.AWS Glue Concepts
You define jobs in AWS Glue to accomplish the work that’s required to extract, transform, and load (ETL) data from a data source to a data target. You typically perform the following actions:
Firstly, you define a crawler to populate your AWS Glue Data Catalog with metadata table definitions. You point your crawler at a data store, and the crawler creates table definitions in the Data Catalog.In addition to table definitions, the Data Catalog contains other metadata that is required to define ETL jobs. You use this metadata when you define a job to transform your data.
- AWS Glue can generate a script to transform your data or you can also provide the script in the AWS Glue console or API.
You can run your job on-demand, or you can set it up to start when a specified trigger occurs. The trigger can be a time-based schedule or an event.
When your job runs, a script extracts data from your data source, transforms the data, and loads it to your data target. This script runs in an Apache Spark environment in AWS Glue.
You can learn more about AWS and its services from the AWS Masters Program.
AWS Glue Terminology
Your Path to Cloud Mastery Begins with AWS SysOps Certification Training!
How Does AWS Glue Work?
Here I am going to demonstrate an example where I will create a transformation script with Python and Spark. I will also cover some basic Glue concepts such as crawler, database, table, and job.
Create a data source for AWS Glue:
Glue can read data from a database or S3 bucket. For example, I have created an S3 bucket called glue-bucket-edureka. Create two folders from S3 console and name them read and write. Now create a text file with the following data and upload it to the read folder of S3 bucket.
rank,movie_title,year,rating
1,The Shawshank Redemption,1994,9.2
2,The Godfather,1972,9.2
3,The Godfather: Part II,1974,9.0
4,The Dark Knight,2008,9.0
5,12 Angry Men,1957,8.9
6,Schindler’s List,1993,8.9
7,The Lord of the Rings: The Return of the King,2003,8.9
8,Pulp Fiction,1994,8.9
9,The Lord of the Rings: The Fellowship of the Ring,2001,8.8
10,Fight Club,1999,8.8Crawl the data source to the data catalog:
In this step, we will create a crawler. The crawler will catalog all files in the specified S3 bucket and prefix. All the files should have the same schema. In Glue crawler terminology the file format is known as a classifier. The crawler identifies the most common classifiers automatically including CSV, json and parquet. Our sample file is in the CSV format and will be recognized automatically.
In the left panel of the Glue management console click Crawlers.
Click the blue Add crawler button.
Give the crawler a name such as glue-demo-edureka-crawler.
In Add a data store menu choose S3 and select the bucket you created. Drill down to select the read folder.
In Choose an IAM role create new. Name the role to for example glue-demo-edureka-iam-role.
In Configure the crawler’s output add a database called glue-demo-edureka-db.
When you are back in the list of all crawlers, tick the crawler that you created. Click Run crawler.
3. The crawled metadata in Glue tables:
Once the data has been crawled, the crawler creates a metadata table from it. You find the results from the Tables section of the Glue console. The database that you created during the crawler setup is just an arbitrary way of grouping the tables. Glue tables don’t contain the data but only the instructions on how to access the data.
4. AWS Glue jobs for data transformations:
From the Glue console left panel go to Jobs and click blue Add job button. Follow these instructions to create the Glue job:
- Name the job as glue-demo-edureka-job.
- Choose the same IAM role that you created for the crawler. It can read and write to the S3 bucket.
- Type: Spark.
- Glue version: Spark 2.4, Python 3.
- This job runs: A new script to be authored by you.
- Security configuration, script libraries, and job parameters
- Maximum capacity: 2. This is the minimum and costs about 0.15$ per run.
- Job timeout: 10. Prevents the job to run longer than expected.
- Click Next and then Save job and edit the script.
5. Editing the Glue script to transform the data with Python and Spark:
Copy the following code to your Glue script editor Remember to change the bucket name for the s3_write_path variable. Save the code in the editor and click Run job.
######################################### ### IMPORT LIBRARIES AND SET VARIABLES ######################################### #Import python modules from datetime import datetime #Import pyspark modules from pyspark.context import SparkContext import pyspark.sql.functions as f #Import glue modules from awsglue.utils import getResolvedOptions from awsglue.context import GlueContext from awsglue.dynamicframe import DynamicFrame from awsglue.job import Job #Initialize contexts and session spark_context = SparkContext.getOrCreate() glue_context = GlueContext(spark_context) session = glue_context.spark_session #Parameters glue_db = "glue-demo-edureka-db" glue_tbl = "read" s3_write_path = "s3://glue-demo-bucket-edureka/write" ######################################### ### EXTRACT (READ DATA) ######################################### #Log starting time dt_start = datetime.now().strftime("%Y-%m-%d %H:%M:%S") print("Start time:", dt_start) #Read movie data to Glue dynamic frame dynamic_frame_read = glue_context.create_dynamic_frame.from_catalog(database = glue_db, table_name = glue_tbl) #Convert dynamic frame to data frame to use standard pyspark functions data_frame = dynamic_frame_read.toDF() ######################################### ### TRANSFORM (MODIFY DATA) ######################################### #Create a decade column from year decade_col = f.floor(data_frame["year"]/10)*10 data_frame = data_frame.withColumn("decade", decade_col) #Group by decade: Count movies, get average rating data_frame_aggregated = data_frame.groupby("decade").agg( f.count(f.col("movie_title")).alias('movie_count'), f.mean(f.col("rating")).alias('rating_mean'), ) #Sort by the number of movies per the decade data_frame_aggregated = data_frame_aggregated.orderBy(f.desc("movie_count")) #Print result table #Note: Show function is an action. Actions force the execution of the data frame plan. #With big data the slowdown would be significant without cacching. data_frame_aggregated.show(10) ######################################### ### LOAD (WRITE DATA) ######################################### #Create just 1 partition, because there is so little data data_frame_aggregated = data_frame_aggregated.repartition(1) #Convert back to dynamic frame dynamic_frame_write = DynamicFrame.fromDF(data_frame_aggregated, glue_context, "dynamic_frame_write") #Write data back to S3 glue_context.write_dynamic_frame.from_options( frame = dynamic_frame_write, connection_type = "s3", connection_options = { "path": s3_write_path, #Here you could create S3 prefixes according to a values in specified columns #"partitionKeys": ["decade"] }, format = "csv" ) #Log end time dt_end = datetime.now().strftime("%Y-%m-%d %H:%M:%S") print("Start time:", dt_end)The detailed explanations are commented in the code. Here is the high-level description:
Read the movie data from S3
Get movie count and rating average for each decade
Write aggregated data back to S3
The execution time with 2 Data Processing Units (DPU) was around 40 seconds. A relatively long duration is explained by the start-up overhead.
 AWS Glue is integrated across a very wide range of AWS services. AWS Glue natively supports data stored in Amazon Aurora and all other Amazon RDS engines,
AWS Glue is integrated across a very wide range of AWS services. AWS Glue natively supports data stored in Amazon Aurora and all other Amazon RDS engines,  AWS Glue is serverless. There is no infrastructure to provision or manage. AWS Glue handles provisioning, configuration, and scaling of the resources required to run your ETL jobs on a fully managed, scale-out Apache Spark environment. You pay only for the resources that you use while your jobs are running.
AWS Glue is serverless. There is no infrastructure to provision or manage. AWS Glue handles provisioning, configuration, and scaling of the resources required to run your ETL jobs on a fully managed, scale-out Apache Spark environment. You pay only for the resources that you use while your jobs are running. AWS Glue automates a significant amount of effort in building, maintaining, and running ETL jobs. It crawls your data sources, identifies data formats as well as suggests schemas and transformations. AWS Glue automatically generates the code to execute your data transformations and loading processes.
AWS Glue automates a significant amount of effort in building, maintaining, and running ETL jobs. It crawls your data sources, identifies data formats as well as suggests schemas and transformations. AWS Glue automatically generates the code to execute your data transformations and loading processes.
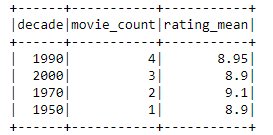
The data transformation script creates summarized movie data. For example, 2000 decade has 3 movies in IMDB top 10 with average rating 8.9. You can download the result file from the write folder of your S3 bucket. Another way to investigate the job would be to take a look at the CloudWatch logs.
The data is stored back to S3 as a CSV in the “write” prefix. The number of partitions equals the number of the output files.You can learn more about Amazon web services through the AWS Solution Training and Certification.
Conclusion
AWS Glue is a powerful ETL tool that doesn’t need a server and makes it easy to get, change, and load data from many different places. It offers a number of features that make it a full and flexible solution to handle and connect business data. Some of these are the Data Catalog, Glue Studio, and the ability to handle both batch and streaming workloads. You can use AWS Glue to make sure your data is good, develop data warehouses, or execute analytics in real time. It does this by automating, scaling, and making it easy to use. This speeds up your data engineering task and gives you faster access to more information.
FAQs
1. What is AWS Glue used for?
AWS Glue is used for serverless data integration, primarily for ETL operations for analytics.
2. Is AWS Glue good for ETL?
Yes, AWS Glue is excellent for ETL, offering serverless operation, scalability, and various tools for data transformation.
3. What is the main function of AWS Glue?
Its main function is to prepare and load data for analytics and machine learning, automating ETL processes.
With this, we have come to the end of this article on AWS Glue. I hope you have understood everything that I have explained here.
If you find this AWS Glue article relevant, you can check out Edureka’s live and instructor-led course created by industry practitioners. Also,Unlock your potential as an AWS Developer by earning your AWS Developer Certification. Take the next step in your cloud computing journey and showcase your expertise in designing,
Do you have a question for us? Please mention it in the comments section of this How to Deploy Java Web Application in AWS, and we will respond to you.