
Advanced Certification in Agentic AI Engineer ...
- 68k Enrolled Learners
- Weekend
- Live Class
(45931)





 Copy Link!
Copy Link!_1648290501.jpg)
We can all agree that Artificial Intelligence has created a huge impact on the world’s economy and will continue to do so since we’re aiding its growth by producing an immeasurable amount of data. Thanks to the advancement in Artificial Intelligence Algorithms we can deal with such humungous data. In this blog post, you will understand the different Artificial Intelligence Algorithms and how they can be used to solve real-world problems.
To simply put it, Artificial Intelligence is the science of getting machines to think and make decisions like human beings do.
Since the development of complex Artificial Intelligence Algorithms, it has been able to accomplish this by creating machines and robots that are applied in a wide range of fields including agriculture, healthcare, robotics, marketing, business analytics and many more.
Before we move any further let’s try to understand what Machine Learning is and how does it is related to AI.
Generally, an algorithm takes some input and uses mathematics and logic to produce the output. In stark contrast, an Artificial Intelligence Algorithm takes a combination of both – inputs and outputs simultaneously in order to “learn” the data and produce outputs when given new inputs.
This process of making machines learn from data is what we call Machine Learning.
Artificial Intelligence Algorithm – Artificial Intelligence Algorithms – Edureka
Machine Learning is a sub-field of Artificial Intelligence, where we try to bring AI into the equation by learning the input data.
If you’re curious to learn more about Machine Learning, give the following blogs a read:
Machines can follow different approaches to learn depending on the data set and the problem that is being solved. In the below section we’ll understand the different ways in which machines can learn.
Machine Learning can be done in the following ways:
Let’s briefly understand the idea behind each type of Machine Learning.
In Supervised Learning, as the name rightly suggests, it involves making the algorithm learn the data while providing the correct answers or the labels to the data. This essentially means that the classes or the values to be predicted are known and well defined for the algorithm from the very beginning.
The other class falls under Unsupervised Learning, where, unlike supervised methods the algorithm doesn’t have correct answers or any answers at all, it is up to the algorithms discretion to bring together similar data and understand it.
Along with these two prominent classes, we also have a third class, called Reinforcement Learning. Just as children are generally “reinforced” certain ideas, principles by either rewarding them when doing the right thing or punishing upon doing something wrong, in Reinforcement Learning, there are rewards given to the algorithm upon every correct prediction thus driving the accuracy higher up.
Check out this Artificial Intelligence Certification Course by Edureka to upgrade your AI skills to the next level
Here’s a short video recorded by our Machine Learning experts. This will help you understand the difference between Supervised, Unsupervised and Reinforcement learning.
Artificial Intelligence Full Course
This Edureka video on “Artificial Intelligence Full Course” will provide you with a comprehensive and detailed knowledge of Artificial Intelligence concepts with hands-on examples.
While the above three classes cover most fields comprehensively, we sometimes still land into the issue of having to bump up the performance of our model. In such cases it might make sense, to use ensemble methods (explained later) to get the accuracy higher up.
Now let’s understand how Artificial Intelligence algorithms can be used to solve different types of problems.
Algorithms in each category, in essence, perform the same task of predicting outputs given unknown inputs, however, here data is the key driver when it comes to picking the right algorithm.
What follows is an outline of categories of Machine Learning problems with a brief overview of the same:
Here’s a table that effectively differentiates each of these categories of problems.
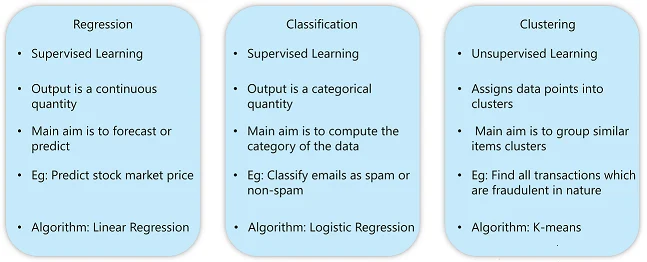
Type Of Problems Solved Using AI – Artificial Intelligence Algorithms – Edureka
For each category of tasks, we can use specific algorithms. In the below section you’ll understand how a category of algorithms can be used as a solution to complex problems.
As mentioned above, different Artificial Intelligence algorithms can be used to solve a category of problems. In the below section we’ll see the different types of algorithms that fall under Classification, Regression and Clustering problems.
Classification, as the name suggests is the act of dividing the dependent variable (the one we try to predict) into classes and then predict a class for a given input. It falls into the category of Supervised Machine Learning, where the data set needs to have the classes, to begin with.
Thus, classification comes into play at any place where we need to predict an outcome, from a set number of fixed, predefined outcomes.
Classification uses an array of algorithms, a few of them listed below
Let us break them down and see where they fit in when it comes to application.
Naive Bayes algorithm follows the Bayes theorem, which unlike all the other algorithms in this list, follows a probabilistic approach. This essentially means, that instead of jumping straight into the data, the algorithm has a set of prior probabilities set for each of the classes for your target.
Once you feed in the data, the algorithm updates these prior probabilities to form something known as the posterior probability.
Hence this can be extremely useful in cases where you need to predict whether your input belongs to either a given list of n classes or does it not belong to any of them. This can be possible using a probabilistic approach mainly because the probabilities thrown for all the n classes will be quite low.
Improving communication, content generation, data analysis, decision-making based on inputs, making innovations, improving accessibility, etc. These are some helpful benefits of LLM applications in every industry.
Let us try to understand this with an example, of a person playing golf, depending on factors like the weather outside.
We first try to generate the frequencies with which certain events occur, in this case, we try to find frequencies of the person playing golf if it’s sunny, rainy, etc outside.
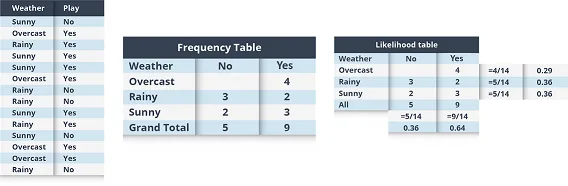
Naive Bayes – Artificial Intelligence Algorithms – Edureka
Using these frequencies we generate our apriori or initial probabilities (eg, the probability of overcast is 0.29 while the general probability of playing is 0.64)
Next up, we generate the posterior probabilities, where we try to answer questions like “what would be the probability of it being sunny outside and the person would play golf?”
We use the Bayesian formula here,
P(Yes | Sunny) = P( Sunny | Yes) * P(Yes) / P (Sunny)
Here we have P (Sunny |Yes) = 3/9 = 0.33, P(Sunny) = 5/14 = 0.36, P( Yes)= 9/14 = 0.64
You can go through this A Comprehensive Guide To Naive Bayes blog to help you understand the math behind Naive Bayes.
The Decision Tree can essentially be summarized as a flowchart-like tree structure where each external node denotes a test on an attribute and each branch represents the outcome of that test. The leaf nodes contain the actual predicted labels. We start from the root of the tree and keep comparing attribute values until we reach a leaf node.
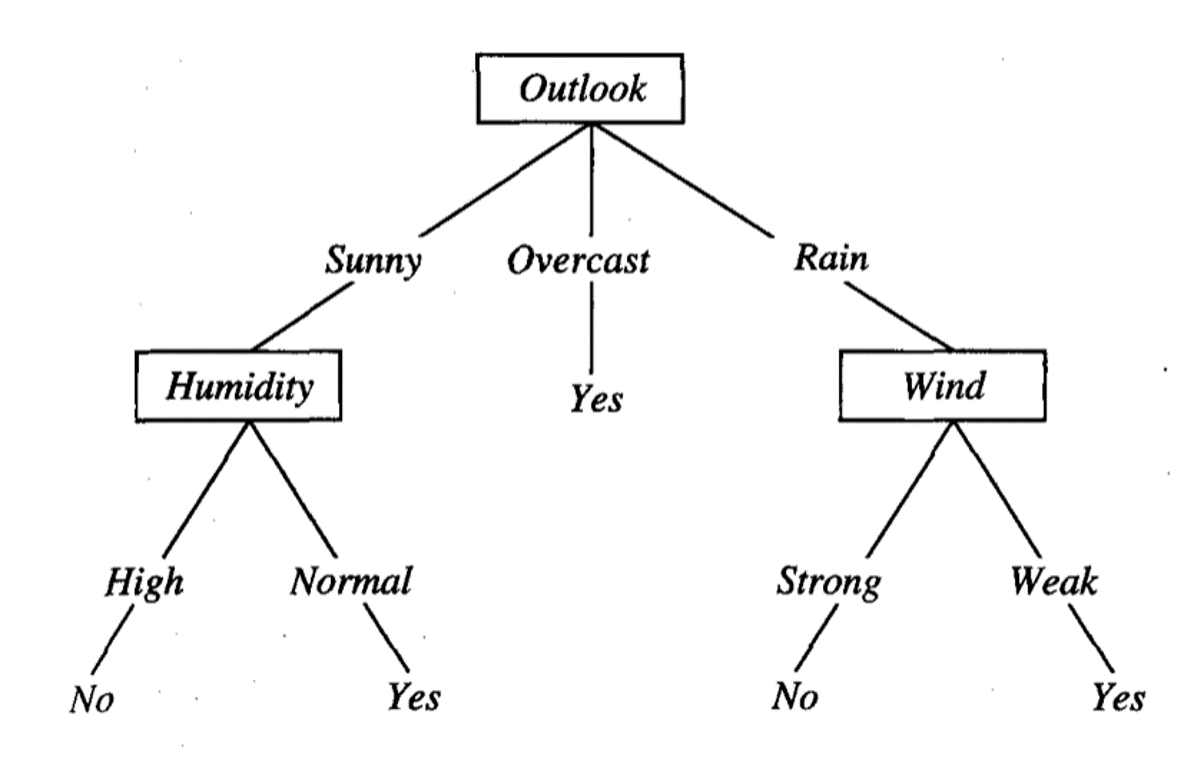 Decision Trees – Artificial Intelligence Algorithms – Edureka
Decision Trees – Artificial Intelligence Algorithms – Edureka
We use this classifier when handling high dimensional data and when little time has been spent behind data preparation. However, a word of caution – they tend to overfit and are prone to change drastically even with slight nuances in the training data.
You can through these blogs to learn more about Decision Trees:
Think of this as a committee of Decision Trees, where each decision tree has been fed a subset of the attributes of data and predicts on the basis of that subset. The average of the votes of all decision trees are taken into account and the answer is given.
An advantage of using Random Forest is that it alleviates the problem of overfitting which was present in a standalone decision tree, leading to a much more robust and accurate classifier.
 Random Forest – Artificial Intelligence Algorithms – Edureka
Random Forest – Artificial Intelligence Algorithms – Edureka
As we can see in the above image, we have 5 decision trees trying to classify a color. Here 3 of these 5 decision trees predict blue and two have different outputs, namely green and red. In this case, we take the average of all the outputs, which gives blue as the highest weightage.
Here’s a blog on Random Forest Classifier that will help you understand the working of Random forest algorithm and how it can be used to solve real-world problems.
It’s a go-to method mainly for binary classification tasks. The term ‘logistic’ comes from the logit function that is used in this method of classification. The logistic function, also called as the sigmoid function is an S-shaped curve that can take any real-valued number and map it between 0 and 1 but never exactly at those limits.
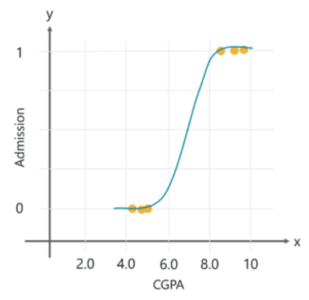
Logistic Regression – Artificial Intelligence Algorithms – Edureka
Let’s assume that your little brother is trying to get into grad school, and you want to predict whether he’ll get admitted in his dream establishment. So, based on his CGPA and the past data, you can use Logistic Regression to foresee the outcome.
Logistic Regression allows you to analyze a set of variables and predict a categorical outcome. Since here we need to predict whether he will get into the school or not, which is a classification problem, logistic regression would be ideal.
Logistic Regression is used to predict house values, customer lifetime value in the insurance sector, etc.
An SVM is unique, in the sense that it tries to sort the data with the margins between two classes as far apart as possible. This is called maximum margin separation.
Another thing to take note of here is the fact that SVM’s take into account only the support vectors while plotting the hyperplane, unlike linear regression which uses the entire dataset for that purpose. This makes SVM’s quite useful in situations when data is in high dimensions.
Let’s try to understand this with an example. In the below figure we have to classify data points into two different classes (squares and triangles).
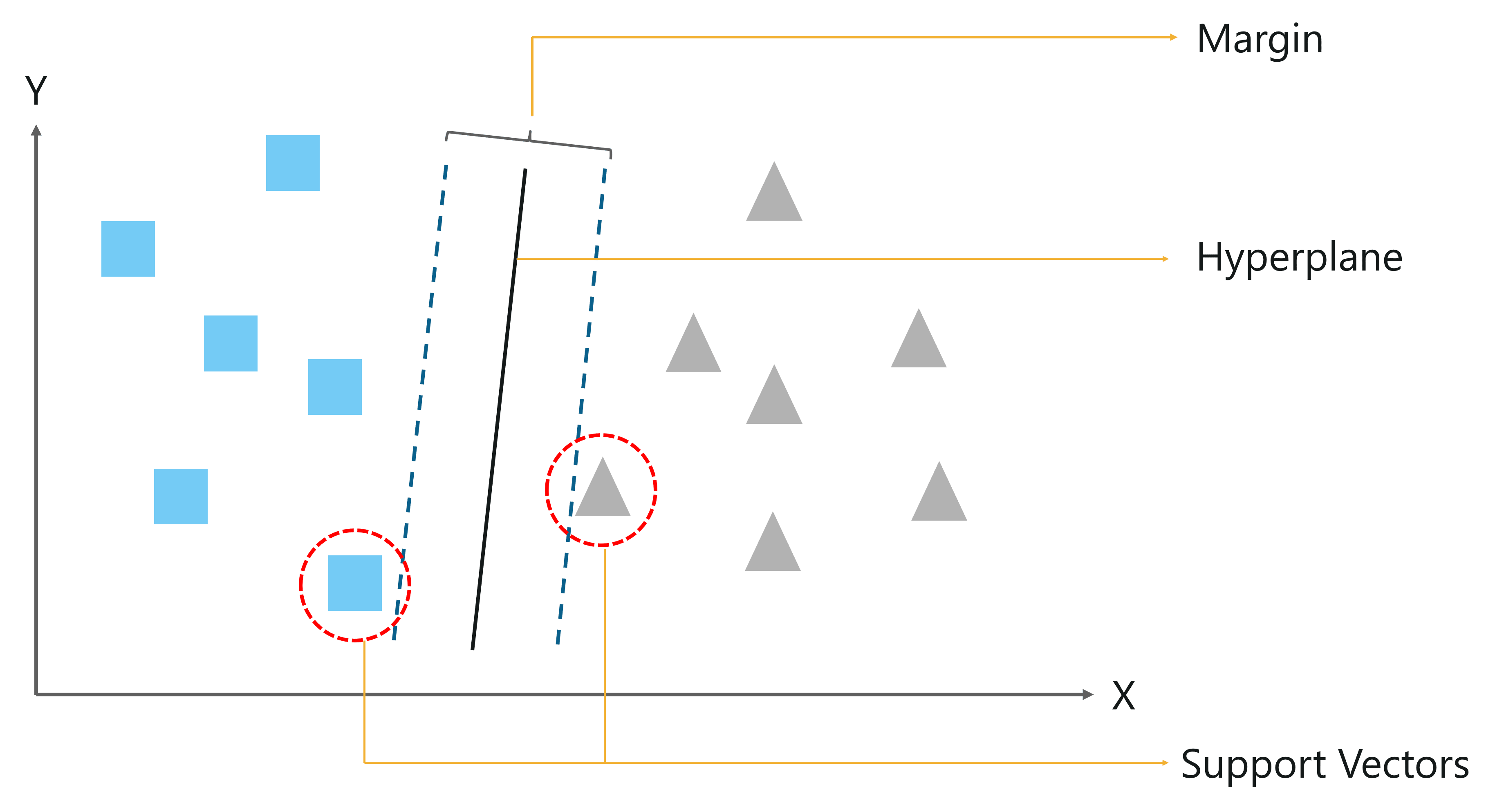 Support Vector Machine – Artificial Intelligence Algorithms – Edureka
Support Vector Machine – Artificial Intelligence Algorithms – Edureka
So, you start off by drawing a random hyperplane and then you check the distance between the hyperplane and the closest data points from each class. These closest data points to the hyperplane are known as Support vectors. And that’s where the name comes from, Support Vector Machine.
The hyperplane is drawn based on these support vectors and an optimum hyperplane will have a maximum distance from each of the support vectors. And this distance between the hyperplane and the support vectors is known as the margin.
To sum it up, SVM is used to classify data by using a hyperplane, such that the distance between the hyperplane and the support vectors is maximum.
To learn more about SVM, you can go through this, Using SVM To Predict Heart Diseases blog.
KNN is a non-parametric (here non-parametric is just a fancy term which essentially means that KNN does not make any assumptions on the underlying data distribution), lazy learning algorithm (here lazy means that the “training” phase is fairly short).
Its purpose is to use a whole bunch of data points separated into several classes to predict the classification of a new sample point.
The following points serve as an overview of the general working of the algorithm:
However, there are some downsides to using KNN. These downsides mainly revolve around the fact that KNN works on storing the entire dataset and comparing new points to existing ones. This means that the storage space increases as our training set increases. This also means that the estimation time increases in proportion to the number of training points.
The following blogs will help you understand how the KNN algorithm works in depth:
Now let’s understand how regression problems can be solved by using regression algorithms.
In the case of regression problems, the output is a continuous quantity. Meaning that we can use regression algorithms in cases where the target variable is a continuous variable. It falls into the category of Supervised Machine Learning, where the data set needs to have the labels, to begin with.
Linear Regression is the most simple and effective regression algorithm. It is utilized to gauge genuine qualities (cost of houses, number of calls, all out deals and so forth.) in view of the consistent variable(s). Here, we build up a connection between free and ward factors by fitting the best line. This best fit line is known as regression line and spoken to by a direct condition Y= a *X + b.
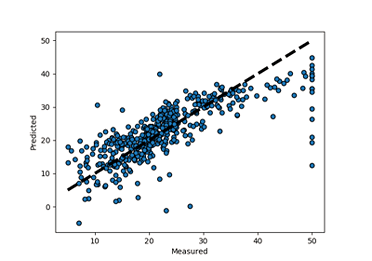
Linear Regression – Artificial Intelligence Algorithms – Edureka
Let us take a simple example here to understand linear regression.
Consider that you are given the challenge to estimate an unknown person’s weight by just looking at them. With no other values in hand, this might look like a fairly difficult task, however using your past experience you know that generally speaking the taller someone is, the heavier they are compared to a shorter person of the same build. This is linear regression, in actuality!
However, linear regression is best used in approaches involving a low number of dimensions. Also, not every problem is linearly separable.
Some of the most popular applications of Linear regression are in financial portfolio prediction, salary forecasting, real estate predictions and in traffic in arriving at ETAs
Now let’s discuss how clustering problems can be solved by using the K-means algorithm. Before that, let’s understand what clustering is.
The basic idea behind clustering is to assign the input into two or more clusters based on feature similarity. It falls into the category of Unsupervised Machine Learning, where the algorithm learns the patterns and useful insights from data without any guidance (labeled data set).
For example, clustering viewers into similar groups based on their interests, age, geography, etc can be done by using Unsupervised Learning algorithms like K-Means Clustering.
K-means is probably the simplest unsupervised learning approach. The idea here is to gather similar data points together and bind them together in the form of a cluster. It does this by calculating the centroid of the group of data points.
To carry out effective clustering, k-means evaluates the distance between each point from the centroid of the cluster. Depending on the distance between the data point and the centroid, the data is assigned to the closest cluster. The goal of clustering is to determine the intrinsic grouping in a set of unlabelled data.
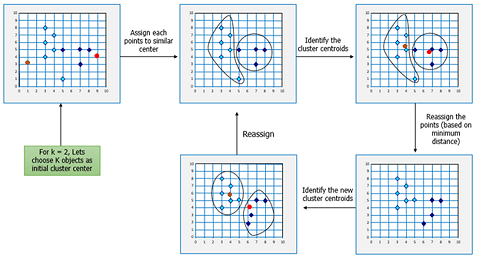
K-means – Artificial Intelligence Algorithms – Edureka
The ‘K’ in K-means stands for the number of clusters formed. The number of clusters (basically the number of classes in which your new instances of data can fall into) is determined by the user.
K-means is used majorly in cases where the data set has points which are distinct and well separated from each other, otherwise, the clusters won’t be far apart, rendering them inaccurate. Also, K-means should be avoided in cases where the data set contains a high amount of outliers or the data set is non-linear.
So that was a brief about K-means algorithm, to learn more you can go through this content recorded by our Machine Learning experts.
In this video, you learn the concepts of K-Means clustering and its implementation using python.
In cases where data is of abundance and prediction precision is of high value, boosting algorithms come into the picture.
Consider the scenario, you have a decision tree trained on a data set along with a whole bunch of hyperparameter tuning already performed, however, the final accuracy is still slightly off than you’d like. In this case, while it might seem that you have run out of possible things to try, ensemble learning comes to the rescue.
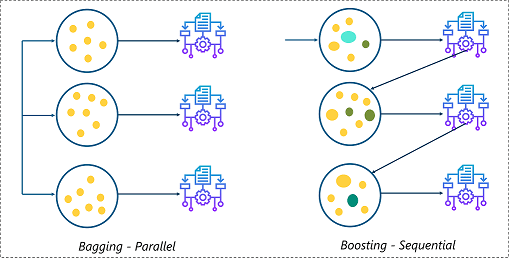
Ensemble Learning – Artificial Intelligence Algorithms – Edureka
You have two different ways in which you can use ensemble learning, in this case, to bump up your accuracy. Let us say your decision tree was failing on a set of input test values, what you do now is, to train a new decision tree model and give a higher weighting to those input test values that your previous model struggled with. This is also called as Boosting, where our initial tree can be formally stated as a weak learner, and the mistakes caused by that model pave way for a better and stronger model.
Another way to approach this is by simply training a whole bunch of trees at once (this can be done fairly quickly and in a parallel fashion) and then taking outputs from each tree and averaging them out. So this way, if after training 10 trees, let’s say 6 trees reply positive to input and 4 trees reply negative, the output you consider is positive. This is formally known as Bagging.
They are used to reduce the bias and variance in supervised learning techniques. There are a host of boosting algorithms available, a few of them discussed below:
Gradient Boosting is a boosting algorithm used when we deal with plenty of data to make a prediction with high prediction power. It combines multiple weak or average predictors to build strong predictor. These boosting algorithms are heavily used to refine the models in data science competitions.
Here, we consider an “optimal” or best model, so essentially our model is at some distance from that “optimal” model. What we now do is, use gradient mathematics and try to get our model closer to the optimal space.
Pertaining to its extremely high predictive power, XGBoost is one of the go-to algorithms when it comes to increasing accuracy as it contains both linear & tree learning algorithms making it 10 times faster than most boosting techniques.
It is the holy grail algorithm when it comes to hackathons, it is no wonder CERN used it in the model for classification of signals from the Large Hadron Collider.
Agentic AI enables AI systems to act autonomously. Enroll in our Agentic AI Certification course to learn how to build intelligent, self-directed AI models.
Also, Elevate your skills and unlock the future of technology with our Prompt Engineering Course Online! Dive into the world of creativity, innovation, and intelligence. Harness the power of algorithms to generate unique solutions. Don’t miss out on this opportunity to shape the future – enroll now and become a trailblazer in Generative AI. Your journey to cutting-edge proficiency begins here!
If you want to learn more about Boosting Machine Learning, you can go through this, Comprehensive Guide To Boosting Machine Learning Algorithms blog.
So with this, we come to an end of this Artificial Intelligence Algorithms blog. If you wish to learn more about Artificial Intelligence, you can give these blogs a read:
Related Post: AI Code Logic













 Thank you for registering Join Edureka Meetup community for 100+ Free Webinars each month JOIN MEETUP GROUP
Thank you for registering Join Edureka Meetup community for 100+ Free Webinars each month JOIN MEETUP GROUP



