





I will start this Apache Spark vs Hadoop blog by first introducing Hadoop and Spark as to set the right context for both the frameworks. Then, moving ahead we will compare both the Big Data frameworks on different parameters to analyse their strengths and weaknesses. But, whatever the outcome of our comparison comes to be, you should know that both Spark and Hadoop are crucial components of the Big Data course curriculum.
Apache Spark vs Hadoop: Introduction to Hadoop
Hadoop is a framework that allows you to first store Big Data in a distributed environment so that you can process it parallely. There are basically two components in Hadoop:
HDFS
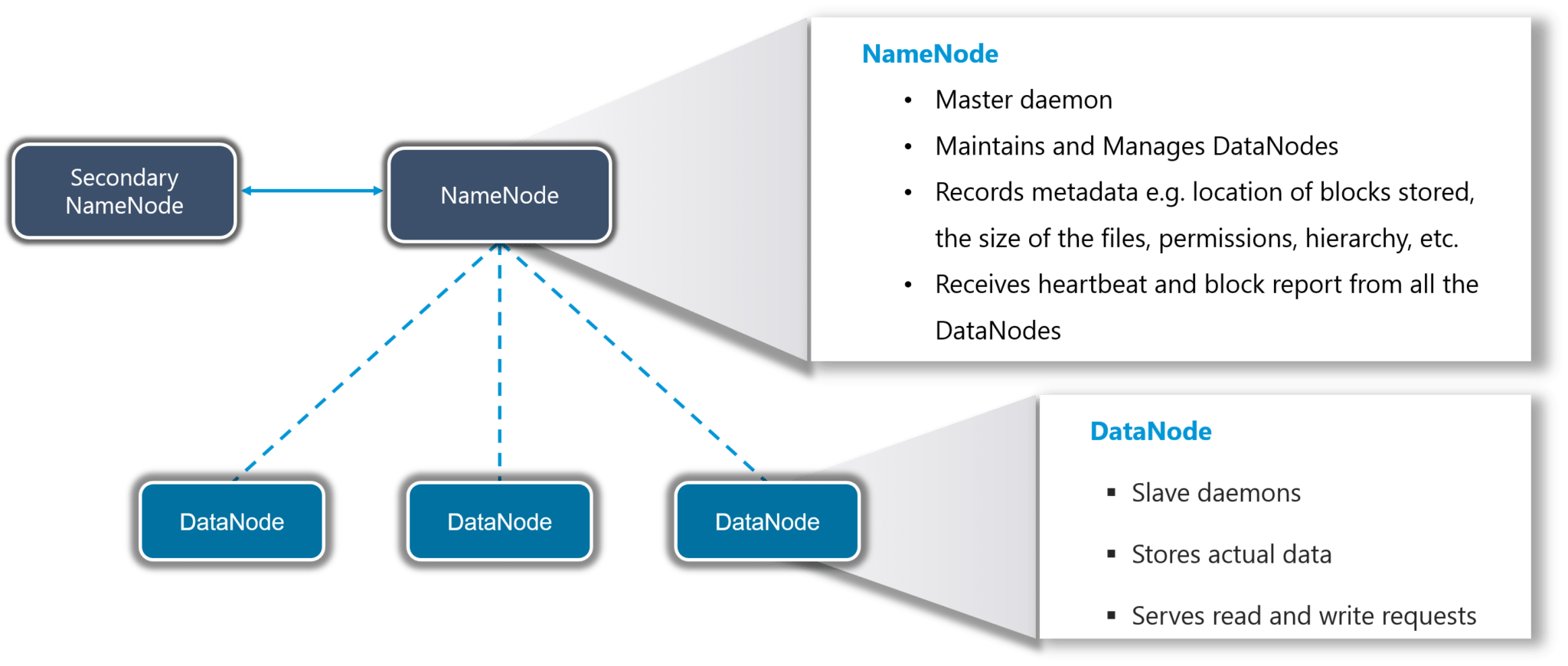
HDFS creates an abstraction of resources, let me simplify it for you. Similar as virtualization, you can see HDFS logically as a single unit for storing Big Data, but actually you are storing your data across multiple nodes in a distributed fashion. Here, you have master-slave architecture. In HDFS, Namenode is a master node and Datanodes are slaves.
NameNode
It is the master daemon that maintains and manages the DataNodes (slave nodes). It records the metadata of all the files stored in the cluster, e.g. location of blocks stored, the size of the files, permissions, hierarchy, etc. It records each and every change that takes place to the file system metadata.
For example, if a file is deleted in HDFS, the NameNode will immediately record this in the EditLog. It regularly receives a Heartbeat and a block report from all the DataNodes in the cluster to ensure that the DataNodes are live. It keeps a record of all the blocks in HDFS and in which nodes these blocks are stored.
DataNode
These are slave daemons which runs on each slave machine. The actual data is stored on DataNodes. They are responsible for serving read and write requests from the clients. They are also responsible for creating blocks, deleting blocks and replicating the same based on the decisions taken by the NameNode.
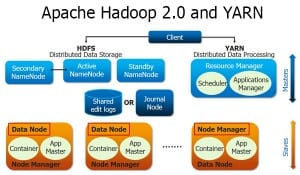
 YARN
YARN
 YARN
YARNYARN performs all your processing activities by allocating resources and scheduling tasks. It has two major daemons, i.e. ResourceManager and NodeManager.
ResourceManager
It is a cluster level (one for each cluster) component and runs on the master machine. It manages resources and schedule applications running on top of YARN.
NodeManager
It is a node level component (one on each node) and runs on each slave machine. It is responsible for managing containers and monitoring resource utilization in each container. It also keeps track of node health and log management. It continuously communicates with ResourceManager to remain up-to-date. So, you can perform parallel processing on HDFS using MapReduce.

To learn more about Hadoop, you can go through this Hadoop Tutorial blog. Now, that we are all set with Hadoop introduction, let’s move on to Spark introduction.
Apache Spark vs Hadoop: Introduction to Apache Spark
Apache Spark is a framework for real time data analytics in a distributed computing environment. It executes in-memory computations to increase speed of data processing. It is faster for processing large scale data as it exploits in-memory computations and other optimizations. Therefore, it requires high processing power.
Resilient Distributed Dataset (RDD) is a fundamental data structure of Spark. It is an immutable distributed collection of objects. Each dataset in RDD is divided into logical partitions, which may be computed on different nodes of the cluster. RDDs can contain any type of Python, Java, or Scala objects, including user-defined classes. Spark components make it fast and reliable. Apache Spark has the following components:
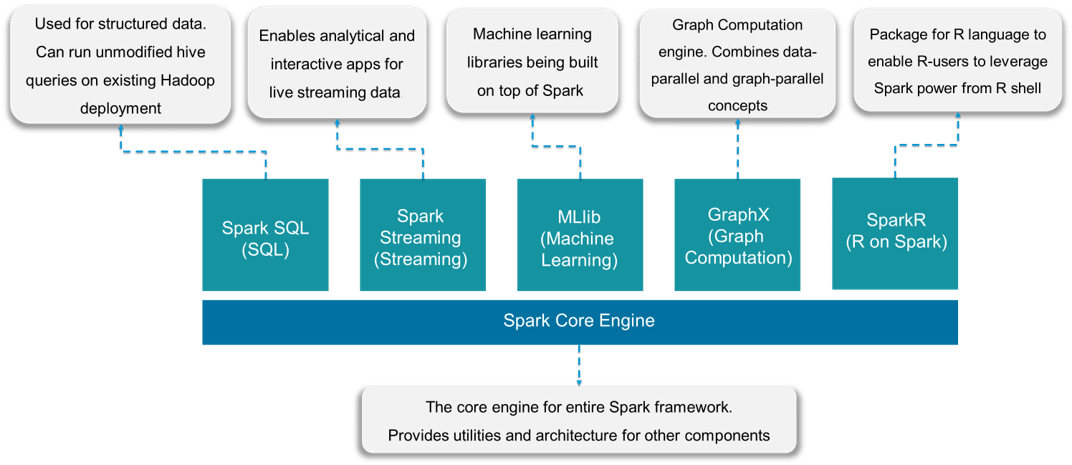
- Spark Core – Spark Core is the base engine for large-scale parallel and distributed data processing. Further, additional libraries which are built atop the core allow diverse workloads for streaming, SQL, and machine learning. It is responsible for memory management and fault recovery, scheduling, distributing and monitoring jobs on a cluster & interacting with storage systems
- Spark Streaming – Spark Streaming is the component of Spark which is used to process real-time streaming data. Thus, it is a useful addition to the core Spark API. It enables high-throughput and fault-tolerant stream processing of live data streams
- Spark SQL: Spark SQL is a new module in Spark which integrates relational processing with Spark’s functional programming API. It supports querying data either via SQL or via the Hive Query Language. For those of you familiar with RDBMS, Spark SQL will be an easy transition from your earlier tools where you can extend the boundaries of traditional relational data processing.
- GraphX: GraphX is the Spark API for graphs and graph-parallel computation. Thus, it extends the Spark RDD with a Resilient Distributed Property Graph. At a high-level, GraphX extends the Spark RDD abstraction by introducing the Resilient Distributed Property Graph: a directed multigraph with properties attached to each vertex and edge.
- MLlib (Machine Learning): MLlib stands for Machine Learning Library. Spark MLlib is used to perform machine learning in Apache Spark.
As you can see, Spark comes packed with high-level libraries, including support for R, SQL, Python, Scala, Java etc. These standard libraries increase the seamless integrations in complex workflow. Over this, it also allows various sets of services to integrate with it like MLlib, GraphX, SQL + Data Frames, Streaming services etc. to increase its capabilities.
To learn more about Apache Spark, you can go through this Spark Tutorial blog. Now the ground is all set for Apache Spark vs Hadoop. Let’s move ahead and compare Apache Spark with Hadoop on different parameters to understand their strengths.
Apache Spark vs Hadoop: Parameters to Compare
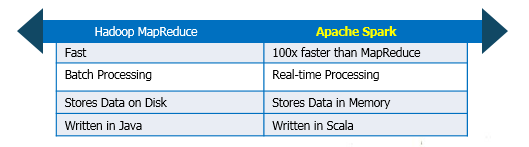
Performance
Spark is fast because it has in-memory processing. It can also use disk for data that doesn’t all fit into memory. Spark’s in-memory processing delivers near real-time analytics. This makes Spark suitable for credit card processing system, machine learning, security analytics and Internet of Things sensors.
Hadoop was originally setup to continuously gather data from multiple sources without worrying about the type of data and storing it across distributed environment. MapReduce uses batch processing. MapReduce was never built for real-time processing, main idea behind YARN is parallel processing over distributed dataset.
The problem with comparing the two is that they perform processing differently.
Ease of Use
Spark comes with user-friendly APIs for Scala, Java, Python, and Spark SQL. Spark SQL is very similar to SQL, so it becomes easier for SQL developers to learn it. Spark also provides an interactive shell for developers to query & perform other actions, & have immediate feedback.
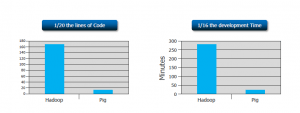
You can ingest data in Hadoop easily either by using shell or integrating it with multiple tools like Sqoop, Flume etc. YARN is just a processing framework and it can be integrated with multiple tools like Hive and Pig. HIVE is a data warehousing component which performs reading, writing and managing large data sets in a distributed environment using SQL-like interface. You can go through this Hadoop ecosystem blog to know about the various tools that can be integrated with Hadoop.
Costs
Hadoop and Spark are both Apache open source projects, so there’s no cost for the software. Cost is only associated with the infrastructure. Both the products are designed in such a way that it can run on commodity hardware with low TCO.
Now you may be wondering the ways in which they are different. Storage & processing in Hadoop is disk-based & Hadoop uses standard amounts of memory. So, with Hadoop we need a lot of disk space as well as faster disks. Hadoop also requires multiple systems to distribute the disk I/O.
Due to Apache Spark’s in memory processing it requires a lot of memory, but it can deal with a standard speed & amount of disk. As disk space is a relatively inexpensive commodity and since Spark does not use disk I/O for processing, instead it requires large amounts of RAM for executing everything in memory. Thus, Spark system incurs more cost.
But yes, one important thing to keep in mind is that Spark’s technology reduces the number of required systems. It needs significantly fewer systems that cost more. So, there will be a point at which Spark reduces the costs per unit of computation even with the additional RAM requirement.
Data Processing
There are two types of data processing: Batch Processing & Stream Processing.
Batch Processing vs Stream Processing
Batch Processing: Batch processing has been crucial to big data world. In simplest term, batch processing is working with high data volumes collected over a period. In batch processing data is first collected and then processed results are produced at a later stage.
Batch processing is an efficient way of processing large, static data sets. Generally, we perform batch processing for archived data sets. For example, calculating average income of a country or evaluating the change in e-commerce in last decade.
Stream processing: Stream processing is the current trend in the big data world. Need of the hour is speed and real-time information, which is what steam processing does. Batch processing does not allow businesses to quickly react to changing business needs in real time, stream processing has seen a rapid growth in demand.
Now coming back to Apache Spark vs Hadoop, YARN is a basically a batch-processing framework. When we submit a job to YARN, it reads data from the cluster, performs operation & write the results back to the cluster. Then it again reads the updated data, performs the next operation & write the results back to the cluster and so on.
Spark performs similar operations, but it uses in-memory processing and optimizes the steps. GraphX allows users to view the same data as graphs and as collections. Users can also transform and join graphs with Resilient Distributed Datasets (RDDs).
Fault Tolerance
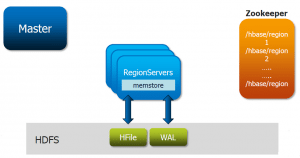
Hadoop and Spark both provides fault tolerance, but both have different approach. For HDFS and YARN both, master daemons (i.e. NameNode & ResourceManager respectively) checks heartbeat of slave daemons (i.e. DataNode & NodeManager respectively). If any slave daemon fails, master daemons reschedules all pending and in-progress operations to another slave. This method is effective, but it can significantly increase the completion times for operations with single failure also. As Hadoop uses commodity hardware, another way in which HDFS ensures fault tolerance is by replicating data.
As we discussed above, RDDs are building blocks of Apache Spark. RDDs provide fault tolerance to Spark. They can refer to any dataset present in external storage system like HDFS, HBase, shared filesystem. They can be operated parallelly.
RDDs can persist a dataset in memory across operations, which makes future actions 10 times much faster. If a RDD is lost, it will automatically be recomputed by using the original transformations. This is how Spark provides fault-tolerance.
Security
Hadoop supports Kerberos for authentication, but it is difficult to handle. Nevertheless, it also supports third party vendors like LDAP (Lightweight Directory Access Protocol) for authentication. They also offer encryption. HDFS supports traditional file permissions, as well as access control lists (ACLs). Hadoop provides Service Level Authorization, which guarantees that clients have the right permissions for job submission.
Spark currently supports authentication via a shared secret. Spark can integrate with HDFS and it can use HDFS ACLs and file-level permissions. Spark can also run on YARN leveraging the capability of Kerberos.
Use-cases where Hadoop fits best:
- Analysing Archive Data. YARN allows parallel processing of huge amounts of data. Parts of Data is processed parallelly & separately on different DataNodes & gathers result from each NodeManager.
- If instant results are not required. Hadoop MapReduce is a good and economical solution for batch processing.
Use-cases where Spark fits best:
Real-Time Big Data Analysis:
Real-time data analysis means processing data generated by the real-time event streams coming in at the rate of millions of events per second, Twitter data for instance. The strength of Spark lies in its abilities to support streaming of data along with distributed processing. This is a useful combination that delivers near real-time processing of data. MapReduce is handicapped of such an advantage as it was designed to perform batch cum distributed processing on large amounts of data. Real-time data can still be processed on MapReduce but its speed is nowhere close to that of Spark.
Spark claims to process data 100x faster than MapReduce, while 10x faster with the disks.
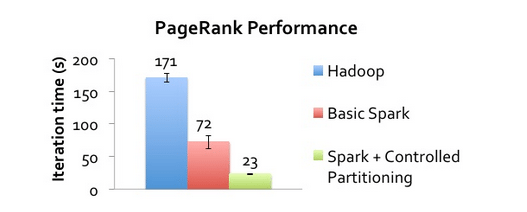
Graph Processing:
Most graph processing algorithms like page rank perform multiple iterations over the same data and this requires a message passing mechanism. We need to program MapReduce explicitly to handle such multiple iterations over the same data. Roughly, it works like this: Read data from the disk and after a particular iteration, write results to the HDFS and then read data from the HDFS for next the iteration. This is very inefficient since it involves reading and writing data to the disk which involves heavy I/O operations and data replication across the cluster for fault tolerance. Also, each MapReduce iteration has very high latency, and the next iteration can begin only after the previous job has completely finished.
Also, message passing requires scores of neighboring nodes in order to evaluate the score of a particular node. These computations need messages from its neighbors (or data across multiple stages of the job), a mechanism that MapReduce lacks. Different graph processing tools such as Pregel and GraphLab were designed in order to address the need for an efficient platform for graph processing algorithms. These tools are fast and scalable, but are not efficient for creation and post-processing of these complex multi-stage algorithms.

Introduction of Apache Spark solved these problems to a great extent. Spark contains a graph computation library called GraphX which simplifies our life. In-memory computation along with in-built graph support improves the performance of the algorithm by a magnitude of one or two degrees over traditional MapReduce programs. Spark uses a combination of Netty and Akka for distributing messages throughout the executors. Let’s look at some statistics that depict the performance of the PageRank algorithm using Hadoop and Spark.
Iterative Machine Learning Algorithms:
Almost all machine learning algorithms work iteratively. As we have seen earlier, iterative algorithms involve I/O bottlenecks in the MapReduce implementations. MapReduce uses coarse-grained tasks (task-level parallelism) that are too heavy for iterative algorithms. Spark with the help of Mesos – a distributed system kernel, caches the intermediate dataset after each iteration and runs multiple iterations on this cached dataset which reduces the I/O and helps to run the algorithm faster in a fault tolerant manner.
Spark has a built-in scalable machine learning library called MLlib which contains high-quality algorithms that leverages iterations and yields better results than one pass approximations sometimes used on MapReduce.
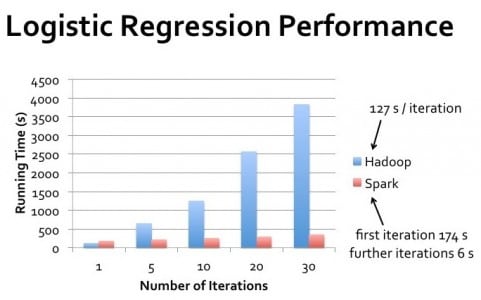
- Fast data processing. As we know, Spark allows in-memory processing. As a result, Spark is up to 100 times faster for data in RAM and up to 10 times for data in storage.
- Iterative processing. Spark’s RDDs allow performing several map operations in memory, with no need to write interim data sets to a disk.
- Near real-time processing. Spark is an excellent tool to provide immediate business insights. This is the reason why Spark is used in credit card’s streaming system.
“Apache Spark: A Killer or Saviour of Apache Hadoop?”
The Answer to this – Hadoop MapReduce and Apache Spark are not competing with one another. In fact, they complement each other quite well. Hadoop brings huge datasets under control by commodity systems. Spark provides real-time, in-memory processing for those data sets that require it. When we combine, Apache Spark’s ability, i.e. high processing speed, advance analytics and multiple integration support with Hadoop’s low cost operation on commodity hardware, it gives the best results. Hadoop compliments Apache Spark capabilities. Spark cannot completely replace Hadoop but the good news is that the demand for Spark is currently at an all-time high! This is the right time to master Spark and make the most of the career opportunities that come your way. Get started now!
Got a question for us? Please mention it in the comments section and we will get back to you at the earliest.
If you wish to learn Spark and build a career in domain of Spark to perform large-scale Data Processing using RDD, Spark Streaming, SparkSQL, MLlib, GraphX and Scala with Real Life use-cases, check out our interactive, live-online Apache Spark Certification Training here, that comes with 24*7 support to guide you throughout your learning period.Upskill your data engineering skills with our Microsoft fabric certification Training course



































asshole mapreduce is a framework/algo logically . whether we perform it at disk ,ssd,in memory that is physical implementation. shaal just likie IASA/IPS/IIM/IIT ratta marke degree lya phir hagna is a necessity