Contributed by Prithviraj Bose
In my previous blog I have discussed stateful transformations using the windowing concept of Apache Spark Streaming. You can read it here.
In this post I am going to discuss cumulative stateful operations in Apache Spark Streaming. If you are new to Spark Streaming then I strongly recommend you to read my previous blog in order to understand how windowing works.
Types of Stateful Transformation in Spark Streaming (Continued…)
> Cumulative tracking
We had used the reduceByKeyAndWindow(…) API to track the states of keys, however windowing poses limitations for certain use cases. What if we want to accumulate the states of the keys throughout rather than limiting it to a time window? In that case we would need to use updateStateByKey(…) API.
This API was introduced in Spark 1.3.0 and has been very popular. However this API has some performance overhead, its performance degrades as the size of the states increases over time. I have written a sample to show the usage of this API.
Spark 1.6.0 introduced a new API mapWithState(…) which solves the performance overheads posed by updateStateByKey(…). In this blog I am going to discuss this particular API using a sample program that I have written.
Before I dive into a code walk-through, let’s spare a few words on checkpointing. For any stateful transformation, checkpointing is mandatory. Checkpointing is a mechanism to restore the state of the keys in case the driver program fails. When the driver restarts, the state of the keys are restored from the checkpointing files. Checkpoint locations are usually HDFS or Amazon S3 or any reliable storage. While testing the code, one can also store in the local file system.
In the sample program, we listen to socket text stream on host = localhost and port = 9999. It tokenizes the incoming stream into (words, no. of occurrences) and tracks the word count using the 1.6.0 API mapWithState(…). Additionally, keys with no updates are removed using StateSpec.timeout API. We are checkpointing in HDFS and the checkpointing frequency is every 20 seconds.
Let’s first create a Spark Streaming session,

We create a checkpointDir in the HDFS and then call the object method getOrCreate(…). The getOrCreate API checks the checkpointDir to see if there are any previous states to restore, if that exists, then it recreates the Spark Streaming session and updates the states of the keys from the data stored in the files before moving on with new data. Otherwise it creates a new Spark Streaming session.
The getOrCreate takes the checkpoint directory name and a function (which we have named createFunc) whose signature should be () => StreamingContext.
Let’s examine the code inside createFunc.
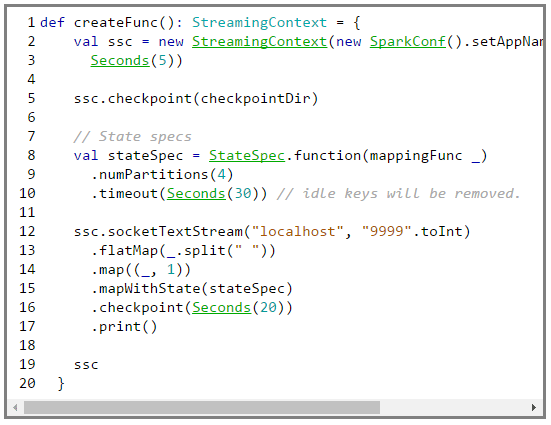
Line# 2: We create a streaming context with job name to “TestMapWithStateJob” and batch interval = 5 seconds.
Line# 5: Set the checkpoint directory.
Line# 8: Set the state specification using the classorg.apache.streaming.StateSpec object. We first set the function that will track the state, then we set the number of partitions for the resulting DStreams that are to be generated during subsequent transformations. Finally we set the timeout (to 30 seconds) where if any update for a key is not received in 30 seconds then the key state will be removed.
Line 12#: Setup the socket stream, flatten the incoming batch data, create a key-value pair, call mapWithState, set the checkpointing interval to 20s and finally print the results.
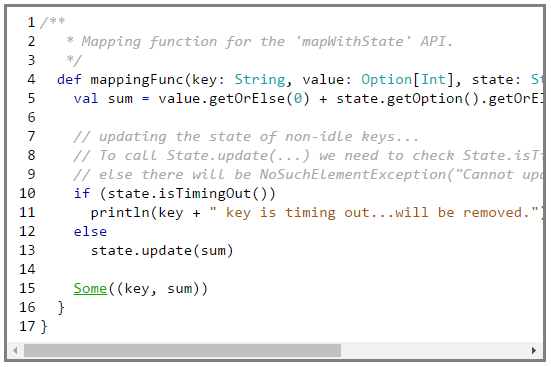
The Spark framework calls the createFunc for every key with the previous value and the current state. We compute the sum and update the state with the cumulative sum and finally we return the sum for the key.
Github Sources -> TestMapStateWithKey.scala, TestUpdateStateByKey.scala
Got a question for us? Please mention it in the comments section and we will get back to you.
Related Posts:
Get Started with Apache Spark & Scala