





Today’s post is about the Load functions in Apache Pig. This is the sequel to the first post which covered UDF functions like Eval, Filter and Aggregate. Please refter to them for more information on other functions of Pig UDF.
Pig’s load function is built on top of a Hadoop’s InputFormat, the class that Hadoop uses to read data. InputFormat has two purposes: It determines how input will be fragmented between map tasks and provides a RecordReader that results in key-value pairs as input to those map tasks. The base class for the load function is LoadFunc.
Load Function – Classification:
LoadFunc abstract class has three main methods for loading data and in most use cases it would suffice to extend it. There are three other optional interfaces which can be implemented to achieve extended functionality:
LoadMetadata:
LoadMetadata has methods to deal with metadata. Most execution of loaders don’t need to implement this unless they interact with a metadata system. The getSchema() method in this interface offers a way for the loader implementations to communicate about the schema of the data back to Pig. If a loader implementation returns data comprised of fields of real types, it should provide the schema describing the data returned through the getSchema() method. The other methods deal with other types of metadata like partition keys and statistics. Implementations can return null return values for these methods if they are not valid for the other implementation.
LoadPushDown:
LoadPushDown has different methods to push operations from Pig runtime into loader implementations. Currently, only the pushProjection() method is called by Pig to communicate to the loader, the exact fields that are required in the Pig script. The loader implementation can choose to abide or not abide the request. If the loader implementation decides to abide the request, it should implement LoadPushDown to improve query performance.
pushProjection():
This method informs LoadFunc, which fields are required in the Pig script. Thus enabling LoadFunc to enhance performance by loading only the fields that are required. pushProjection() takes a ‘requiredFieldList.’ ‘requiredFieldList’ is read only and cannot be changed by LoadFunc. ‘requiredFieldList’ includes a list of ‘requiredField’, where each ‘requiredField’ indicates a field required by the Pig script and is comprised of index, alias, type and subFields. Pig uses the column index requiredField.index to communicate with the LoadFunc about the fields required by the Pig script. If the required field is a map, Pig will pass ‘requiredField.subFields’ which contains a list of keys required by Pig scripts for the map.
LoadCaster:
LoadCaster has techniques to convert byte arrays in to specific types. A loader implementation should implement this when implicit or explicit casts from DataByteArray fields to other types needs to be supported.
The LoadFunc abstract class is the main class to extend for implementing a loader. The methods which is required to be overridden are explained below:
getInputFormat():
This method is called by Pig to get the InputFormat utilized by the loader. The methods in the InputFormat are called by Pig in the same fashion as Hadoop in a MapReduce Java program. If the InputFormat is a Hadoop packaged one, the implementation should use the new API based one, under org.apache.hadoop.mapreduce. If it is a custom InputFormat, it is better to be implemented using the new API in org.apache.hadoop.mapreduce.
setLocation():
This method is called by Pig to communicate the load location to the loader. The loader needs to use this method to communicate the same information to the core InputFormat. This method is called multiple times by pig.
prepareToRead():
In this method, the RecordReader related to the InputFormat provided by the LoadFunc is passed to the LoadFunc. The RecordReader can now be used by the implementation in getNext() to return a tuple representing a record of data back to Pig.
getNext():
The meaning of getNext() has not changed and is called by Pig runtime to acquire the next tuple in the data. In this method, the implementation should use the underlying RecordReader and construct the tuple to return.
Gain hands-on experience in building and managing data storage, processing, and analytics solutions with the Azure Data Engineer Certification Course.
Default Implementations in LoadFunc:
Take note that the default implementations in LoadFunc should be overridden only when needed.
setUdfContextSignature():
This method will be called by Pig, both in the front end and back end to pass a unique signature to the Loader. The signature can be utilized to store any information in to the UDFContext which the Loader needs to store between various method invocations in the front end and back end. A use case is to store RequiredFieldList passed to it in LoadPushDown.pushProjection(RequiredFieldList) for use in the back end before returning tuples in getNext(). The default implementation in LoadFunc has an empty body. This method will be called before other methods.
relativeToAbsolutePath():
Pig runtime will call this method to permit the Loader to convert a relative load location to an absolute location. The default implementation provided in LoadFunc handles this for FileSystem locations. If the load source is something else, loader implementation may choose to override this.
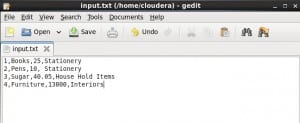
The loader implementation in the example is a loader for text data with line delimiter as ‘
‘ and ‘ ‘ as default field delimiter similar to current PigStorage loader in Pig. The implementation uses an existing Hadoop supported Inputformat – TextInputFormat – as the underlying InputFormat.
public class SimpleTextLoader extends LoadFunc {
protected RecordReader in = null;
private byte fieldDel = ' ';
private ArrayList<Object> mProtoTuple = null;
private TupleFactory mTupleFactory = TupleFactory.getInstance();
private static final int BUFFER_SIZE = 1024;
public SimpleTextLoader() {
}
/**
* Constructs a Pig loader that uses specified character as a field delimiter.
*
* @param delimiter
* the single byte character that is used to separate fields.
* (" " is the default.)
*/
public SimpleTextLoader(String delimiter) {
this();
if (delimiter.length() == 1) {
this.fieldDel = (byte)delimiter.charAt(0);
} else if (delimiter.length() > 1 & & delimiter.charAt(0) == '') {
switch (delimiter.charAt(1)) {
case 't':
this.fieldDel = (byte)' ';
break;
case 'x':
fieldDel =
Integer.valueOf(delimiter.substring(2), 16).byteValue();
break;
case 'u':
this.fieldDel =
Integer.valueOf(delimiter.substring(2)).byteValue();
break;
default:
throw new RuntimeException("Unknown delimiter " + delimiter);
}
} else {
throw new RuntimeException("PigStorage delimeter must be a single character");
}
}
@Override
public Tuple getNext() throws IOException {
try {
boolean notDone = in.nextKeyValue();
if (notDone) {
return null;
}
Text value = (Text) in.getCurrentValue();
byte[] buf = value.getBytes();
int len = value.getLength();
int start = 0;
for (int i = 0; i < len; i++) {
if (buf[i] == fieldDel) {
readField(buf, start, i);
start = i + 1;
}
}
// pick up the last field
readField(buf, start, len);
Tuple t = mTupleFactory.newTupleNoCopy(mProtoTuple);
mProtoTuple = null;
return t;
} catch (InterruptedException e) {
int errCode = 6018;
String errMsg = "Error while reading input";
throw new ExecException(errMsg, errCode,
PigException.REMOTE_ENVIRONMENT, e);
}
}
private void readField(byte[] buf, int start, int end) {
if (mProtoTuple == null) {
mProtoTuple = new ArrayList<Object>();
}
if (start == end) {
// NULL value
mProtoTuple.add(null);
} else {
mProtoTuple.add(new DataByteArray(buf, start, end));
}
}
@Override
public InputFormat getInputFormat() {
return new TextInputFormat();
}
@Override
public void prepareToRead(RecordReader reader, PigSplit split) {
in = reader;
}
@Override
public void setLocation(String location, Job job)
throws IOException {
FileInputFormat.setInputPaths(job, location);
}
}
Got a question for us? Please mention it in the comments section and we will get back to you.Related Posts:






































Any chance of including the import statements in your example? There are multiple implementations of some of those classes and they are not all compatible >:-(