Before starting this Apache Oozie tutorial, let us understand where scheduler system are used. In real time scenarios, one job is dependent on other jobs, like the output of a MapReduce task may be passed to Hive job for further processing. Next scenario can be, scheduling a set of task on the basis of time like daily, weekly, monthly or based on data availability. Apache Oozie provides you the power to easily handle these kinds of scenarios. This is why Apache Oozie is an important part of Hadoop Ecosystem.
In this Apache Oozie tutorial blog, we will be covering:
- Apache Oozie Introduction
- Oozie Workflow
- Oozie Coordinator
- Oozie Bundle
- Word Count Workflow Job
- Time-Based Word Count Coordinator Job
We will begin this Oozie tutorial by introducing Apache Oozie. Then moving ahead, we will understand types of jobs that can be created & executed using Apache Oozie.
Apache Oozie Tutorial: Introduction to Apache Oozie
 Apache Oozie is a scheduler system to manage & execute Hadoop jobs in a distributed environment. We can create a desired pipeline with combining a different kind of tasks. It can be your Hive, Pig, Sqoop or MapReduce task. Using Apache Oozie you can also schedule your jobs. Within a sequence of the task, two or more jobs can also be programmed to run parallel to each other. It is a scalable, reliable and extensible system.
Apache Oozie is a scheduler system to manage & execute Hadoop jobs in a distributed environment. We can create a desired pipeline with combining a different kind of tasks. It can be your Hive, Pig, Sqoop or MapReduce task. Using Apache Oozie you can also schedule your jobs. Within a sequence of the task, two or more jobs can also be programmed to run parallel to each other. It is a scalable, reliable and extensible system.
Oozie is an open Source Java web-application, which is responsible for triggering the workflow actions. It, in turn, uses the Hadoop execution engine to execute the tasks.
Apache Oozie detects the completion of tasks through callback and polling. When Oozie starts a task, it provides a unique callback HTTP URL to the task and notifies that URL when the task is completed. If the task fails to invoke the callback URL, Oozie can poll the task for completion.
There are three types of jobs in Apache Oozie:
- Oozie Workflow Jobs− These are Directed Acyclic Graphs (DAGs) which specifies a sequence of actions to be executed.
- Oozie Coordinator Jobs− These consist of workflow jobs triggered by time and data availability.
- Oozie Bundles− These can be referred as a package of multiple coordinators and workflow jobs.
Learn more about Big Data and its applications from the Azure Data Engineer Course.
Now, let’s understand all these jobs one by one.
Apache Oozie Tutorial: Oozie Workflow
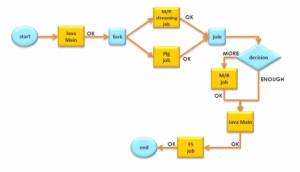
Workflow is a sequence of actions arranged in a Direct Acyclic Graph (DAG). The actions are dependent on one another, as the next action can only be executed after the output of current action. A workflow action can be a Pig action, Hive action, MapReduce action, Shell action, Java action etc. There can be decision trees to decide how and on which condition a job should run.
We can create different types of actions based on the job and each type of action can have its own type of tags. The workflow and the scripts or jars should be placed in HDFS path before executing the workflow.
Command: oozie job –oozie http://localhost:11000/oozie -config job.properties -run
For checking the status of the job, you can go to Oozie web console. By clicking on the job you will see the status of the job.
In scenarios, where we want to run multiple jobs parallely, we can use Fork. Whenever we use fork, we have to use Join as an end node to fork. For each fork there should be a join. Join assumes that all the nodes executing parallely, are a child of a single fork. For example, we can create two tables at the same time parallelly.
If we want to run an action based on the output of decision, we can add decision tags. For example, if we already have the hive table we won’t need to create it again. In that situation, we can add a decision tag to not run the create table steps if the table already exists. Decision nodes have a switch tag similar to switch case.
The value of job-tracker, name-node, script and param can be passed directly. But, this becomes hard to manage. This is where a config file (i.e. .property file) comes handy.
Apache Oozie Tutorial: Oozie Coordinator
You can schedule complex workflows as well as workflows that are scheduled regularly using Coordinator. Oozie Coordinators triggers the workflows jobs based on time, data or event predicates. The workflows inside the job coordinator start when the given condition is satisfied.
Definitions required for the coordinator jobs are:
- start− Start datetime for the job.
- end− End datetime for the job.
- timezone− Timezone of the coordinator application.
- frequency− The frequency, in minutes, for executing the jobs.
Some more properties are available for Control Information:
- timeout− The maximum time, in minutes, for which an action will wait to satisfy the additional conditions, before getting discarded. 0 indicates that if all the input events are not satisfied at the time of action materialization, the action should timeout immediately. -1 indicates no timeout, the action will wait forever. The default value is -1.
- concurrency− The maximum number of actions for a job that can run parallely. The default value is 1.
- execution– It specifies the execution order if multiple instances of the coordinator job have satisfied their execution criteria. It can be:
- FIFO (default)
- LIFO
- LAST_ONLY
Command: oozie job –oozie http://localhost:11000/oozie -config <path to coordinator.properties file> -run
If a configuration property used in the definition is not provided with the job configuration while submitting the coordinator job, the job submission will fail.
You can get a better understanding with the Data Engineering Certification in Mumbai.
Apache Oozie Tutorial: Oozie Bundle
Oozie Bundle system allows you to define and execute a set of coordinator applications, often called a data pipeline. In an Oozie bundle, there is no explicit dependency among the coordinator applications. However, you could use the data dependency of coordinator applications to create an implicit data application pipeline. You can start/stop/suspend/resume/rerun the bundle. It gives a better and easy operational control.
Kick-off-time − The time when a bundle should start and submit coordinator applications.
Advancing in this Apache Oozie tutorial, we will understand how to create Workflow Job.
Apache Oozie Tutorial: Word Count Workflow Job
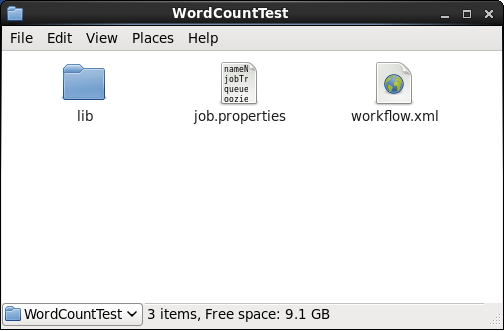
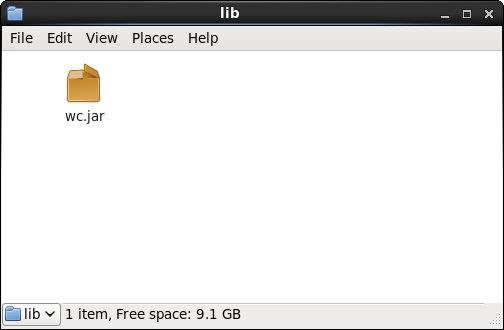
In this example, we are going to execute a Word Count Job using Apache Oozie. Here we will not discuss about how to write a MapReduce word count program. So, before following this Apache Oozie tutorial you need to download this word count jar file. Now, create a WordCountTest directory where we’ll place all the files. Create a lib directory where we’ll place the word count jar as shown in the below images.
Now, lets move ahead & create job.properties & workflow.xml files, where we will specify the job and parameters associated with it.
job.properties
First, we are creating a job.properties file, where we are defining the path of NameNode & ResourceManager. NameNode path is required for resolving the workflow directory path & jobTracker path will help in submitting the job to YARN. We need to provide the path of the workflow.xml file, which should be stored in HDFS.

workflow.xml
Next, we need to create the workflow.xml file, where we will define all our actions and execute them. First, we need to specify the workflow-app name i.e. WorkflowRunnerTest. Then, we are specifying the start node. The start node (in the start to tag) is the entry point for a workflow job. It points towards the first workflow node from where the job should start. As you can see in the below image, the next node is intersection0 from where the job will start.
Next, we are specifying the task to be performed, in the action node. We are executing a MapReduce WordCount task here. We need to specify the configurations required for executing this MapReduce task. We are defining the job tracker & NameNode address.
Next is the prepared element, which is used exclusively for directory cleanup, before executing the action. Here we are performing delete operation in HDFS for deleting the out1 folder if it is already created. Prepare tag is used for creating or deleting a folder before executing the job. Then we are specifying the MapReduce properties like job queue name, mapper class, reducer class, output key class & output value class.
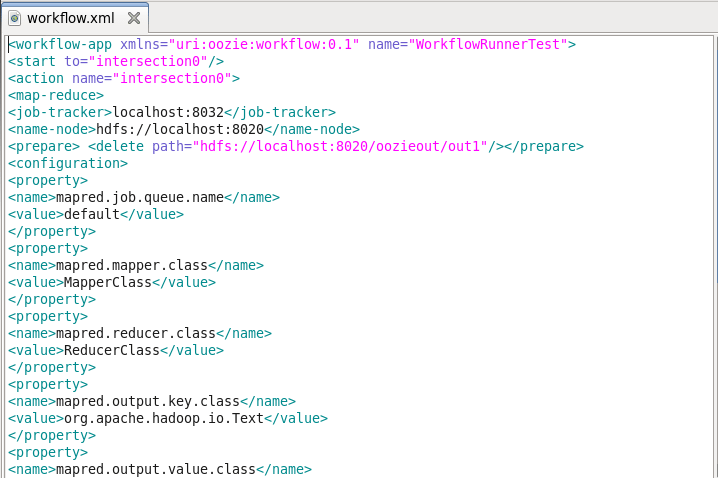
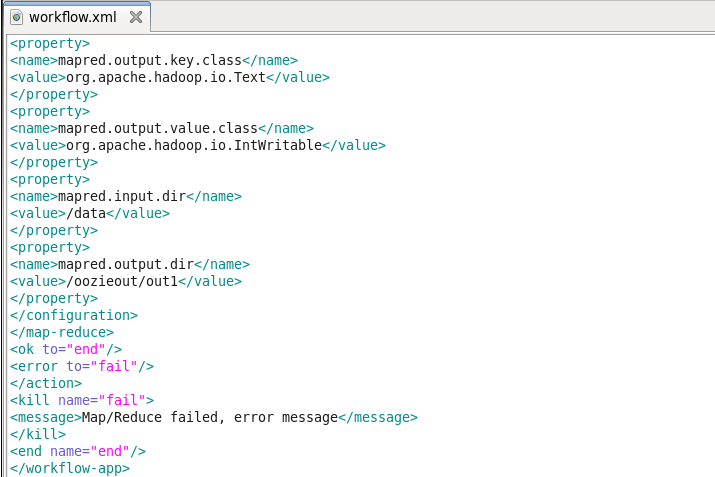
The last MapReduce task configuration is the input & output directory in HDFS. The input directory is data directory, which is stored in the root path of NameNode. At last, we will specify the kill element if the job fails.
Now we need to move the WordCountTest folder in HDFS, as we have specified in oozie.wf.application.path property in job.properties file. So, we are copying the WordCountTest folder in the Hadoop root directory.
Command: hadoop fs -put WordCountTest /

To verify, you can go to NameNode Web UI and check whether the folder has been uploaded in HDFS root directory or not.

Now, we are all set to move ahead and execute the workflow job.
Command: oozie job –oozie http://localhost:11000/oozie -config job.properties -run

Once we have executed our job we’ll get the job id (i.e. 0000009-171219160449620-oozie-edur-W) as shown in the above image. You can go and check the job that you have submitted in the Oozie Web UI i.e. localhost:11000. You can see in the below image, the job which we have submitted is listed down.

If you will observe in the above image, you’ll see the Job ID, the name of the Job, the status of the job, user who submitted the job, time of creation, start & last modification. You can click on the job to get more details like:
- Job Info

- Job Definition

- Job Configuration

As the status of the job is succeeded, so we need to go to HDFS root directory and check whether the output directory has been created or not.

As you can see that the oozieout directory has been created in the HDFS, so now let’s look at the output file that has been created.
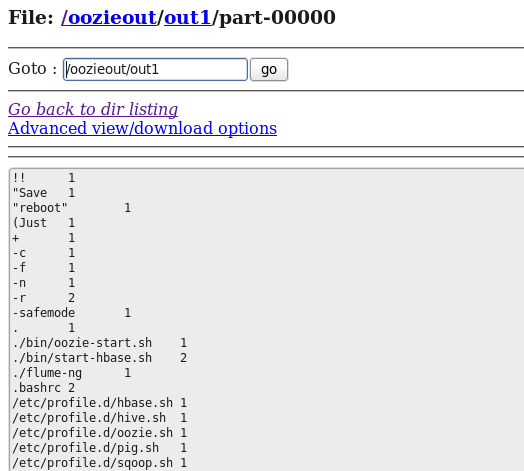
As we have seen how to create an Oozie workflow job, now we will advance in this Apache Oozie Tutorial blog and understand how to create a coordinator job.
Apache Oozie Tutorial: Time Based Word Count Coordinator Job
In this example, we will be creating a time-based word count coordinator job which will be executed after a specific time interval. You can create and schedule a job using Apache Oozie which needs to executed daily or periodically.
Let us advance quickly in this Apache Oozie tutorial and create a coordinator job. Here we will be creating three files i.e. coordinator.properties, coordinator.xml & workflow.xml file. Again, here we will place the wordcount jar inside the lib directory as shown in the below image.
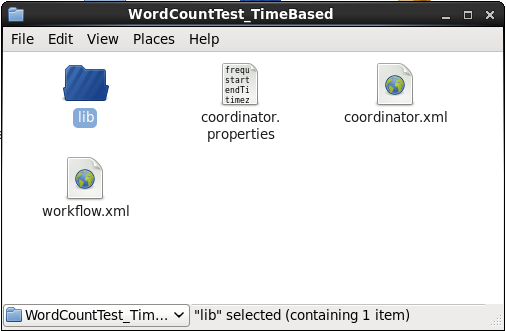
Now let us look at these files individually. First, we will start with coordinator.properties file.

Here, we are specifying the frequency at which the workflow will be executed. Frequency is always expressed in minutes. In our case, this coordinator job will be executed once every hour between the specified time. Frequency is used to capture the periodic intervals at which the data sets are produced, and coordinator applications are scheduled to run.
For defining frequency in minutes, hours, days & months use the following format:
| ${coord:minutes(int n)} | n | ${coord:minutes(45)} –> 45 |
| ${coord:hours(int n)} | n * 60 | ${coord:hours(3)} –> 180 |
| ${coord:days(int n)} | variable | ${coord:days(2)} –> minutes in 2 full days from the current date |
| ${coord:months(int n)} | variable | ${coord:months(1)} –> minutes in a 1 full month from the current date |
Next, we are defining the start & end time of the job as shown in the above image. startTime is the start datetime for the job & endTime is the end datetime of the job.
Next, we are specifying the NameNode & ResourceManager url, which will be used to refer workflow.xml file in HDFS & submit jobs to YARN respectively. At last, we are specifying workflow.xml path, which we will store in HDFS. We will also specify the application path where all the files & lib directory will be stored.
The second file is coordinator.xml where we will use all the properties that we have specified in the coordinator.properties file. Now, first, we will specify the properties of the coordinator application i.e. name, frequency & timezone. Next, we will specify the workflows one by one. Here, we only have one workflow. So, inside action element we will create workflow element, where we will specify the application path.

Next, advancing ahead we have to create workflow.xml file where we will specify the task. It is similar to the workflow.xml file, which we have created in workflow job.
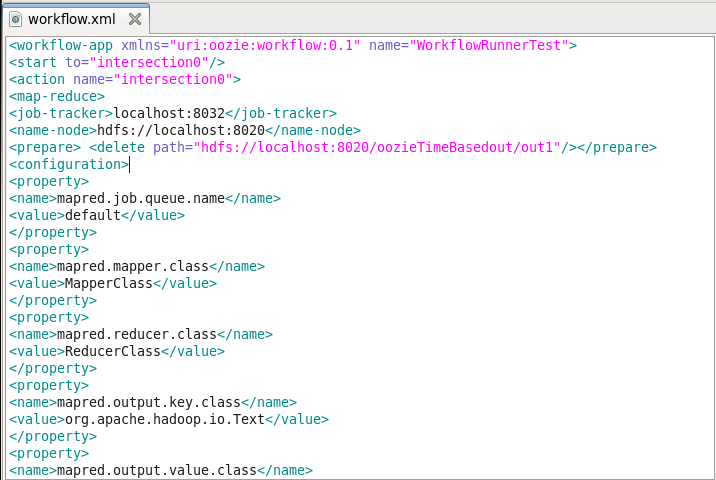
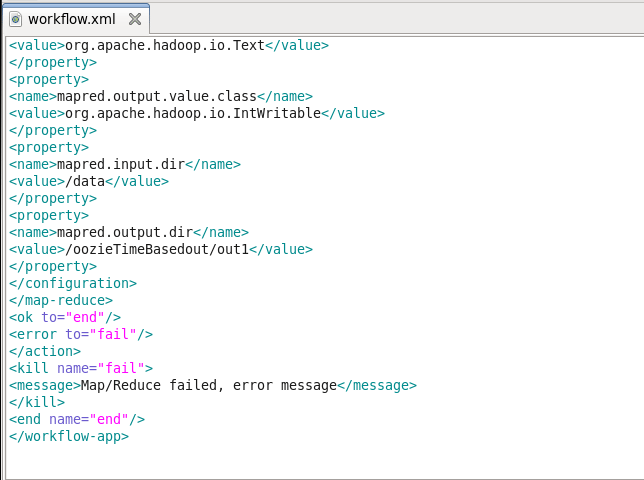
Now again, we will move this WordCountTest_TimedBased directory to HDFS.
Command: hadoop fs -put WordCountTest_TimeBased /

Now, we are all set to move ahead and execute this coordinator job in this Oozie Tutorial. Let’s go ahead and execute it.
Command: oozie job –oozie http://localhost:11000/oozie -config coordinator.properties -run

Note down this coordinator job id (i.e. 0000010-171219160449620-oozie-edur-C). It will help you to track down your job in Oozie Web UI.

You can see the job listed down in your Coordinator Jobs tab in Oozie Web UI. Similar to the Workflow job we have name, status, user, frequency, start & end time of the job. When you will click on a particular job, you will see the details of the job, as shown in the below images.
- Coordinator Job Info

- Coordinator Job Definition

- Coordinator Job Configuration

Now, as we have looked through the different tabs. We will go back to the HDFS root directory where the output folder will be created. As you can see in the below image, oozieTimeBasedout directory has been created, as we specified in workflow.xml file.

Now, let us take a look at the output file that has been created.
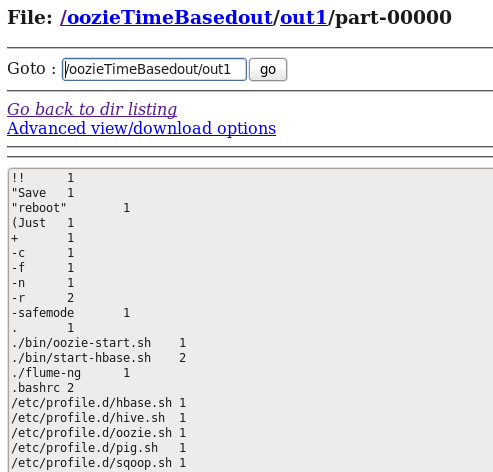
I hope you found this Apache Oozie Tutorial blog informative. If you are interested to learn more, you can go through this Hadoop Tutorial Series which tells you about Big Data and how Hadoop is solving challenges related to Big Data.
Now that you have understood Apache Oozie, check out the Hadoop training by Edureka, a trusted online learning company with a network of more than 250,000 satisfied learners spread across the globe. The Edureka Big Data Hadoop Certification Training course helps learners become expert in HDFS, Yarn, MapReduce, Pig, Hive, HBase, Oozie, Flume and Sqoop using real-time use cases on Retail, Social Media, Aviation, Tourism, Finance domain.
Got a question for us? Please mention it in the comments section and we will get back to you or join our Hadoop Training in Ahmedabad.