





Apache Hive is one of the most important frameworks in the Hadoop ecosystem, in-turn making it very crucial for Hadoop Certification. In this blog, we will learn about Apache Hive and Hive installation on Ubuntu.
What is Apache Hive?
Apache Hive is a data warehouse infrastructure that facilitates querying and managing large data sets which resides in distributed storage system. It is built on top of Hadoop and developed by Facebook. Hive provides a way to query the data using a SQL-like query language called HiveQL(Hive query Language).
Internally, a compiler translates HiveQL statements into MapReduce jobs, which are then submitted to Hadoop framework for execution.
Difference between Hive and SQL:
Hive looks very much similar like traditional database with SQL access. However, because Hive is based on Hadoop and MapReduce operations, there are several key differences:
As Hadoop is intended for long sequential scans and Hive is based on Hadoop, you would expect queries to have a very high latency. Itmeans that Hive would not be appropriate for those applications that need very fast response times, as you can expect with a traditional RDBMS database.
Finally, Hive is read-based and therefore not appropriate for transaction processing that typically involves a high percentage of write operations.
Learn more about Big Data and its applications from the Data Engineering Training.
Hive Installation on Ubuntu:
Please follow the below steps to install Apache Hive on Ubuntu:
Step 1: Download Hive tar.
Command: wget http://archive.apache.org/dist/hive/hive-2.1.0/apache-hive-2.1.0-bin.tar.gz
Step 2: Extract the tar file.
Command: tar -xzf apache-hive-2.1.0-bin.tar.gz
Command: ls

Step 3: Edit the “.bashrc” file to update the environment variables for user.
Command: sudo gedit .bashrc
Add the following at the end of the file:
# Set HIVE_HOME
export HIVE_HOME=/home/edureka/apache-hive-2.1.0-bin
export PATH=$PATH:/home/edureka/apache-hive-2.1.0-bin/bin
Also, make sure that hadoop path is also set.
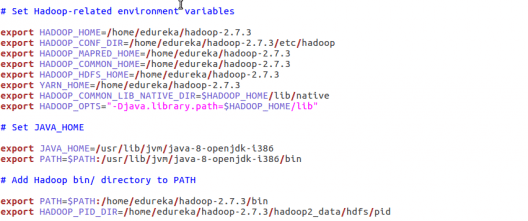
Run below command to make the changes work in same terminal.
Command: source .bashrc
Step 4: Check hive version.

Step 5: Create Hive directories within HDFS. The directory ‘warehouse’ is the location to store the table or data related to hive.
Command:
- hdfs dfs -mkdir -p /user/hive/warehouse
- hdfs dfs -mkdir /tmp
Step 6: Set read/write permissions for table.
Command:
In this command, we are giving write permission to the group:
- hdfs dfs -chmod g+w /user/hive/warehouse
- hdfs dfs -chmod g+w /tmp
Step 7: Set Hadoop path in hive-env.sh
Command: cd apache-hive-2.1.0-bin/
Command: gedit conf/hive-env.sh

Set the parameters as shown in the below snapshot.

Step 8: Edit hive-site.xml
Command: gedit conf/hive-site.xml
<?xml version="1.0" encoding="UTF-8" standalone="no"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?><!-- Licensed to the Apache Software Foundation (ASF) under one or more contributor license agreements. See the NOTICE file distributed with this work for additional information regarding copyright ownership. The ASF licenses this file to You under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License at http://www.apache.org/licenses/LICENSE-2.0 Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License. --> <configuration> <property> <name>javax.jdo.option.ConnectionURL</name> <value>jdbc:derby:;databaseName=/home/edureka/apache-hive-2.1.0-bin/metastore_db;create=true</value> <description> JDBC connect string for a JDBC metastore. To use SSL to encrypt/authenticate the connection, provide database-specific SSL flag in the connection URL. For example, jdbc:postgresql://myhost/db?ssl=true for postgres database. </description> </property> <property> <name>hive.metastore.warehouse.dir</name> <value>/user/hive/warehouse</value> <description>location of default database for the warehouse</description> </property> <property> <name>hive.metastore.uris</name> <value/> <description>Thrift URI for the remote metastore. Used by metastore client to connect to remote metastore.</description> </property> <property> <name>javax.jdo.option.ConnectionDriverName</name> <value>org.apache.derby.jdbc.EmbeddedDriver</value> <description>Driver class name for a JDBC metastore</description> </property> <property> <name>javax.jdo.PersistenceManagerFactoryClass</name> <value>org.datanucleus.api.jdo.JDOPersistenceManagerFactory</value> <description>class implementing the jdo persistence</description> </property> </configuration>
Learn more about Big Data and its applications from the Data Engineering Course in London.
Step 9: By default, Hive uses Derby database. Initialize Derby database.
Command: bin/schematool -initSchema -dbType derby

Step 10: Launch Hive.
Command: hive
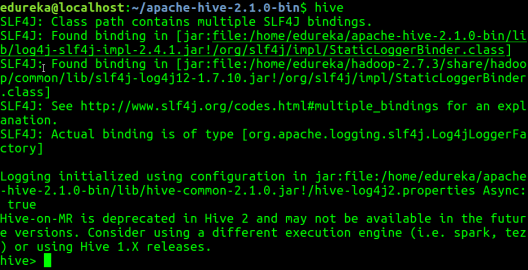
Step 11: Run few queries in Hive shell.
Command: show databases;
Command: create table employee (id string, name string, dept string) row format delimited fields terminated by ‘ ‘ stored as textfile;
Command: show tables;

Step 12: To exit from Hive:
Command: exit;
Now that you are done with Hive installation, the next step forward is to try out Hive commands on Hive shell. Hence, our next blog “Top Hive Commands with Examples in HQL” will help you to master Hive commands.
Gain hands-on experience in building and managing data storage, processing, and analytics solutions with the Microsoft Azure Data Engineering Certification Course (DP-203)
Related Posts:







































Worked like a charm..thanks edureka.
Thanks for checking out our blog, Abhijit. We’re glad you found it useful. Do hit subscribe to stay posted on upcoming blogs. Cheers!
Issue at Step 9 in my system
Kindly help me advise on this, why the err is throwing as “Unrecognized Hadoop major version number: 1.0.4”
anilchittajallu@ubuntu:~/Work/apache-hive-2.1.1-bin$ bin/schematool -initSchema -dbType derby
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/home/anilchittajallu/Work/apache-hive-2.1.1-bin/lib/log4j-slf4j-impl-2.4.1.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/home/anilchittajallu/Work/hadoop-2.7.2/share/hadoop/common/lib/slf4j-log4j12-1.7.10.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.apache.logging.slf4j.Log4jLoggerFactory]
Exception in thread “main” java.lang.IllegalArgumentException: Unrecognized Hadoop major version number: 1.0.4
at org.apache.hadoop.hive.shims.ShimLoader.getMajorVersion(ShimLoader.java:169)
at org.apache.hadoop.hive.shims.ShimLoader.loadShims(ShimLoader.java:136)
at org.apache.hadoop.hive.shims.ShimLoader.getHadoopShims(ShimLoader.java:95)
at org.apache.hive.beeline.HiveSchemaTool.(HiveSchemaTool.java:81)
at org.apache.hive.beeline.HiveSchemaTool.(HiveSchemaTool.java:68)
at org.apache.hive.beeline.HiveSchemaTool.main(HiveSchemaTool.java:480)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at org.apache.hadoop.util.RunJar.main(RunJar.java:156)
Hey Anil, thanks for checking out our blog. Here’s what you need to do:
Please delete these jar files binding between Hadoop and Hive
rm lib/hive-jdbc-2.0.0-standalone.jar
rm lib/log4j-slf4j-impl-2.4.1.jar
Now execute your commands and Let us know if you are still getting the same error.
Hope this helps. Cheers!
followed the same steps as mentioned above, but, getting this error :
I’m a new bie to hadoop, please resolve this issue. screenshot attached !!
Hi Naina,
Thank you for reaching out to us.
You can raise a support ticket for the same by logging into your LMS, and our support team will surely help you.
You can get in touch with us for further clarification by contacting our sales team on +91-8880862004 (India) or 1800 275 9730 (US toll free). You can also mail us on sales@edureka.co.
Is this issue got resolved?, i am also getting same problem
I’m unable to create hive directories within HDFS. The command mentioned in step 4 is returning :- No such file or directory
Just like unix we’ll need the “-p” flag to create the parent directories as well unless you have already created them. Then command will work
hadoop fs -mkdir -p /user/hive/warehouse
Really good tutorial worked very well… thanks
What is the server domain and the port on which hive is installed and where can i modify it?
Hi Sricharan, it takes the domain server of the machine on which hive is installed, by default. You can modify the Hive server domain and port number by editing the below property in hive-site.xml or hive-default.xml file.
hive.metastore.uris
thrift://$metastore.server.full.hostname:$portnumber
URI
for client to contact metastore server. To enable HiveServer2, leave
the property value empty.
Hope this helps!!
Logging initialized using configuration in jar:file:/usr/lib/hive/apache-hive-0.13.1-bin/lib/hive-common-0.13.1.jar!/hive-log4j.properties
Exception in thread “main” java.lang.RuntimeException: java.lang.RuntimeException: Unable to instantiate org.apache.hadoop.hive.metastore.HiveMetaStoreClient
at org.apache.hadoop.hive.ql.session.SessionState.start(SessionState.java:346)
at org.apache.hadoop.hive.cli.CliDriver.run(CliDriver.java:681)
at org.apache.hadoop.hive.cli.CliDriver.main(CliDriver.java:625)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:57)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:622)
at org.apache.hadoop.util.RunJar.main(RunJar.java:156)
Caused by: java.lang.RuntimeException: Unable to instantiate org.apache.hadoop.hive.metastore.HiveMetaStoreClient
at org.apache.hadoop.hive.metastore.MetaStoreUtils.newInstance(MetaStoreUtils.java:1412)
at org.apache.hadoop.hive.metastore.RetryingMetaStoreClient.(RetryingMetaStoreClient.java:62)
at org.apache.hadoop.hive.metastore.RetryingMetaStoreClient.getProxy(RetryingMetaStoreClient.java:72)
at org.apache.hadoop.hive.ql.metadata.Hive.createMetaStoreClient(Hive.java:2453)
at org.apache.hadoop.hive.ql.metadata.Hive.getMSC(Hive.java:2465)
at org.apache.hadoop.hive.ql.session.SessionState.start(SessionState.java:340)
… 7 more
Caused by: java.lang.reflect.InvocationTargetException
at sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method)
at sun.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:57)
at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45)
at java.lang.reflect.Constructor.newInstance(Constructor.java:534)
at org.apache.hadoop.hive.metastore.MetaStoreUtils.newInstance(MetaStoreUtils.java:1410)
… 12 more
Caused by: MetaException(message:Got exception: java.net.ConnectException Call to localhost/127.0.0.1:9000 failed on connection exception: java.net.ConnectException: Connection refused)
at org.apache.hadoop.hive.metastore.MetaStoreUtils.logAndThrowMetaException(MetaStoreUtils.java:1102)
at org.apache.hadoop.hive.metastore.Warehouse.getFs(Warehouse.java:114)
at org.apache.hadoop.hive.metastore.Warehouse.getDnsPath(Warehouse.java:144)
at org.apache.hadoop.hive.metastore.Warehouse.getWhRoot(Warehouse.java:159)
at org.apache.hadoop.hive.metastore.Warehouse.getDefaultDatabasePath(Warehouse.java:177)
at org.apache.hadoop.hive.metastore.HiveMetaStore$HMSHandler.createDefaultDB_core(HiveMetaStore.java:504)
at org.apache.hadoop.hive.metastore.HiveMetaStore$HMSHandler.createDefaultDB(HiveMetaStore.java:523)
at org.apache.hadoop.hive.metastore.HiveMetaStore$HMSHandler.init(HiveMetaStore.java:397)
at org.apache.hadoop.hive.metastore.HiveMetaStore$HMSHandler.(HiveMetaStore.java:356)
at org.apache.hadoop.hive.metastore.RetryingHMSHandler.(RetryingHMSHandler.java:54)
at org.apache.hadoop.hive.metastore.RetryingHMSHandler.getProxy(RetryingHMSHandler.java:59)
at org.apache.hadoop.hive.metastore.HiveMetaStore.newHMSHandler(HiveMetaStore.java:4944)
at org.apache.hadoop.hive.metastore.HiveMetaStoreClient.(HiveMetaStoreClient.java:171)
… 17 more
I am getting above error while launching Hive or while running command hive.
Plz help. Thank you
any one
solve this issue?
Hi,
I followed this steps,When I entered sudo hive in ubuntu,I see the following exception.
sudo: hive: command not found
I have also tried with out sudo,i see the following exception.
No command ‘hive’ found, did you mean:
Command ‘hime’ from package ‘hime’ (universe)
Command ‘jive’ from package ‘filters’ (universe)
hive: command not found
Note; I am in this folder.
/usr/lib/hive/apache-hive-0.13.1-bin/conf$
Please help me in solving this issue.!!Thanks in advance..!!
Hi Murali, please try with the following command and check
Command: cd /usr/lib/hive/apache-hive-0.13.1-bin/
Command: bin/hive
Hope this helps!!
I am still getting the same error which is mentioned above by murali…. please suggest what to do..
you should correct the path of hive in either bashrc or profile where you have save your environment setting @Murali
Hi,
I followed the steps exactly outlined here. Using Hive 0.8.0 I am getting the error
Exception in thread “main” java.lang.NoClassDefFoundError: org/apache/hadoop/hive/conf/HiveConf
at java.lang.Class.forName0(Native Method)
at java.lang.Class.forName(Class.java:249)
at org.apache.hadoop.util.RunJar.main(RunJar.java:149)
Caused by: java.lang.ClassNotFoundException: org.apache.hadoop.hive.conf.HiveConf
at java.net.URLClassLoader$1.run(URLClassLoader.java:202)
at java.security.AccessController.doPrivileged(Native Method)
at java.net.URLClassLoader.findClass(URLClassLoader.java:190)
at java.lang.ClassLoader.loadClass(ClassLoader.java:306)
at java.lang.ClassLoader.loadClass(ClassLoader.java:247)
… 3 more
Hi Bala, Seems like the HADOOP_HOME path has not been set. I would
suggest to set the HADOOP_HOME in ~/.bashrc or /etc/profile file. To do that
please follow the below steps.
Step1: Open a new terminal and give: sudo gedit ~/.bashrc
Step 2:Go to end of the file and add the below line:
export HADOOP_HOME=/path/to/Hadoop
Step 3: In the command, give the path where Hadoop is installed on your Ubuntu
and then try to run Hive.