Shubham SinhaShubham Sinha is a Big Data and Hadoop expert working as a...Shubham Sinha is a Big Data and Hadoop expert working as a Research Analyst at Edureka. He is keen to work with Big Data...
In this Apache Flume tutorial blog, we will understand how Flume helps in streaming data from various sources. But before that let us understand the importance of data ingestion. Data ingestion is the initial & important step in order to process & analyse data, and then derive business values out of it. There are be multiple sources from which data is gathered in an organization.
Table of Content
Lets talk about another important reason why Flume became so popular. I hope you may be familiar with Apache Hadoop, which is being used tremendously in the industry as it can store all kinds of data. Flume can easily integrate with Hadoop and dump unstructured as well as semi-structured data on HDFS, complimenting the power of Hadoop. This is why Apache Flume is an important part of Hadoop Ecosystem.
In this Apache Flume tutorial blog, we will be covering:
We will be beginning this Flume tutorial by discussing about what is Apache Flume. Then moving ahead, we will understand the advantages of using Flume.
Apache Flume Tutorial: Introduction to Apache Flume
Apache Flume is a tool for data ingestion in HDFS. It collects, aggregates and transports large amount of streaming data such as log files, events from various sources like network traffic, social media, email messages etc. to HDFS. Flume is a highly reliable & distributed.
The main idea behind the Flume’s design is to capture streaming data from various web servers to HDFS. It has simple and flexible architecture based on streaming data flows. It is fault-tolerant and provides reliability mechanism for Fault tolerance & failure recovery.
After understanding what is Flume, now let us advance in this Flume Tutorial blog and understand the benefits of Apache Flume. Then moving ahead, we will look at the architecture of Flume and try to understand how it works fundamentally.
Apache Flume Tutorial: Advantages of Apache Flume
There are several advantages of Apache Flume which makes it a better choice over others. The advantages are:
Flume is scalable, reliable, fault tolerant and customizable for different sources and sinks.
Apache Flume can store data in centralized stores (i.e data is supplied from a single store) like HBase & HDFS.
Flume is horizontally scalable.
If the read rate exceeds the write rate, Flume provides a steady flow of data between read and write operations.
Flume provides reliable message delivery. The transactions in Flume are channel-based where two transactions (one sender & one receiver) are maintained for each message.
Using Flume, we can ingest data from multiple servers into Hadoop.
It gives us a solution which is reliable and distributed and helps us in collecting, aggregating and moving large amount of data sets like Facebook, Twitter and e-commerce websites.
It helps us to ingest online streaming data from various sources like network traffic, social media, email messages, log files etc. in HDFS.
It supports a large set of sources and destinations types.
The architecture is one which is empowering Apache Flume with these benefits. Now, as we know the advantages of Apache Flume, lets move ahead and understand Apache Flume architecture.
Apache Flume Tutorial: Flume Architecture
Now, let us understand the architecture of Flume from the below diagram:
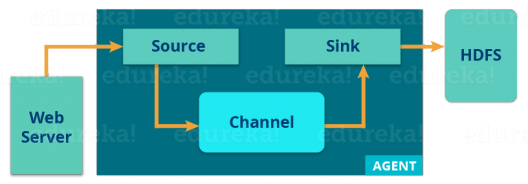
There is a Flume agent which ingests the streaming data from various data sources to HDFS. From the diagram, you can easily understand that the web server indicates the data source. Twitter is among one of the famous sources for streaming data.
The flume agent has 3 components: source, sink and channel.
Source: It accepts the data from the incoming streamline and stores the data in the channel.
Channel: In general, the reading speed is faster than the writing speed. Thus, we need some buffer to match the read & write speed difference. Basically, the buffer acts as a intermediary storage that stores the data being transferred temporarily and therefore prevents data loss. Similarly, channel acts as the local storage or a temporary storage between the source of data and persistent data in the HDFS.
Sink: Then, our last component i.e. Sink, collects the data from the channel and commits or writes the data in the HDFS permanently.
Now as we know how Apache Flume works, let us take a look at a practical where we will sink the Twitter data and store it in the HDFS.
Apache Flume Tutorial: Streaming Twitter Data
In this practical, we will stream data from Twitterusing Flume and then store the data in HDFS as shown in the below image.
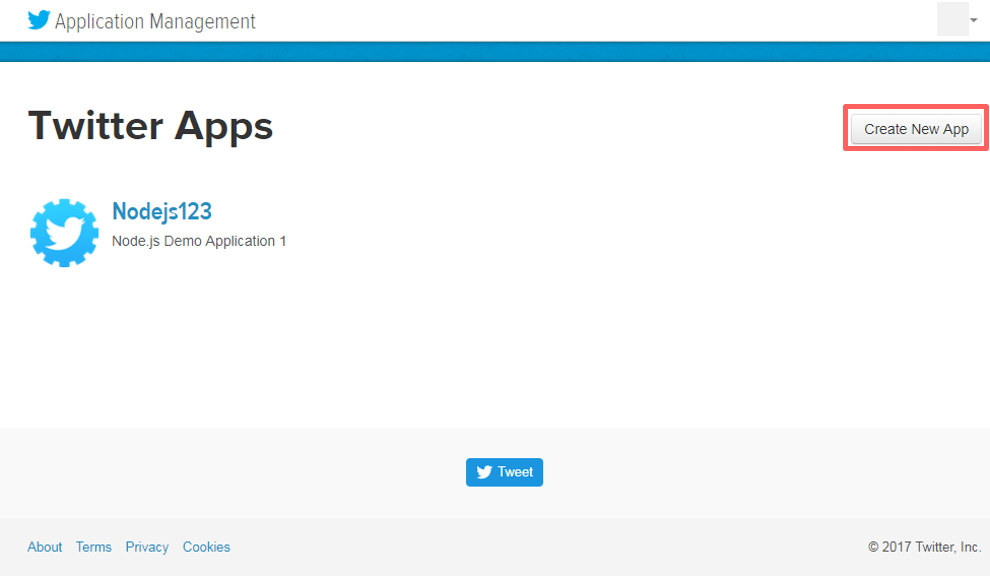
The first step is to create a Twitter application. For this, you first have to go to this url: https://apps.twitter.com/and sign in to your Twitter account. Go to create application tab as shown in the below image.
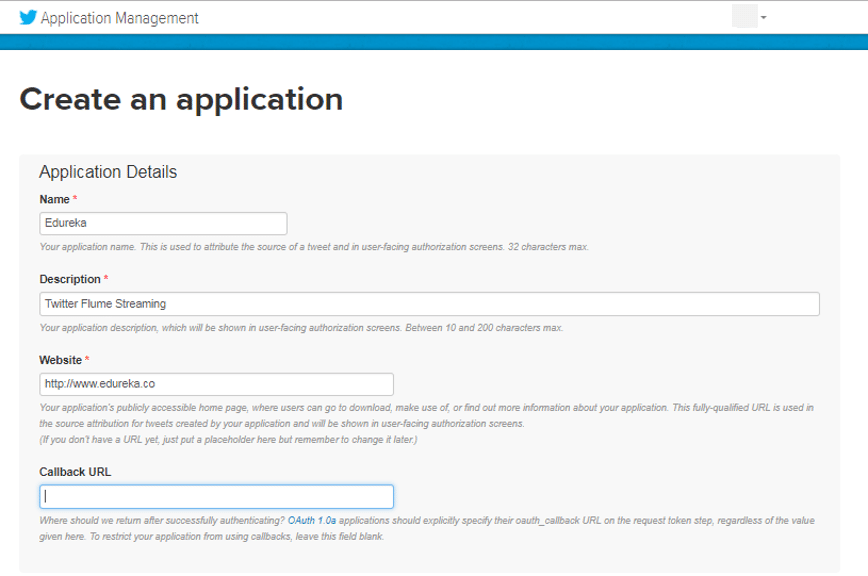
Then, create an application as shown in the below image.
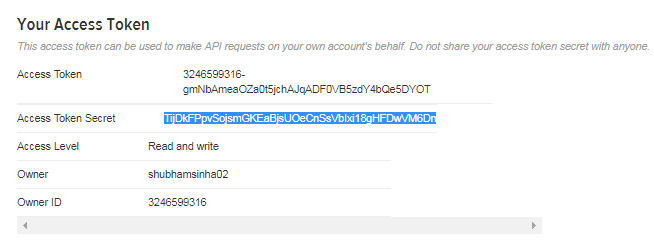
After creating this application, you will find Key & Access token. Copy the key and the access token. We will pass these tokens in our Flume configuration file to connect to this application.
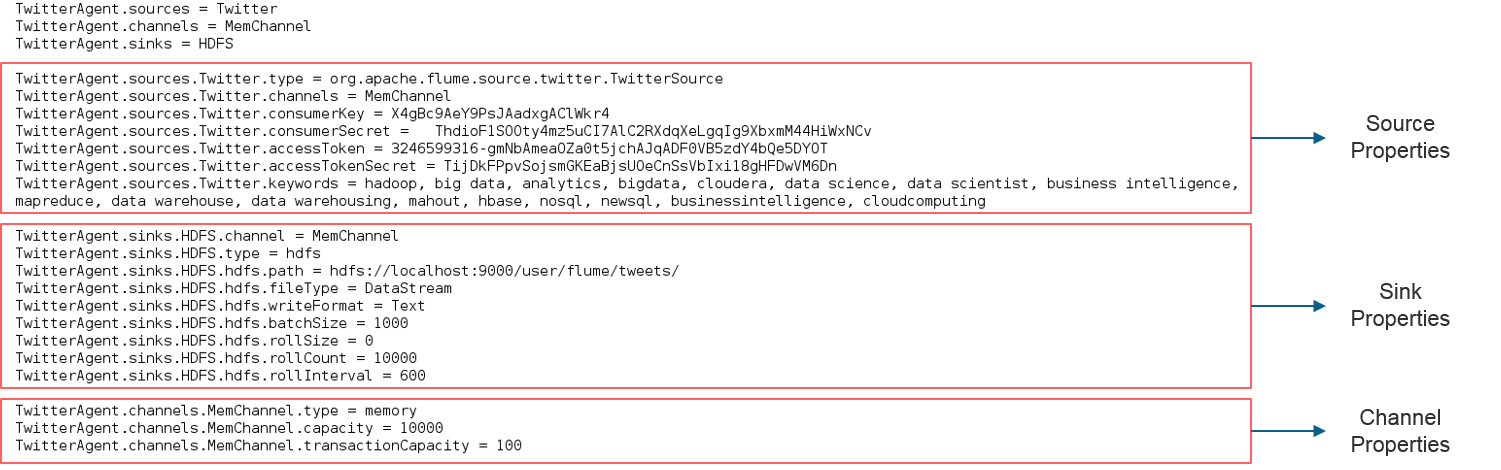
Now create a flume.conf file in the flume’s root directory as shown in the below image. As we discussed, in the Flume’s Architecture, we will configure our Source, Sink and Channel. Our Source is Twitter, from where we are streaming the data and our Sink is HDFS, where we are writing the data.
In source configuration we are passing the Twitter source type as org.apache.flume.source.twitter.TwitterSource. Then, we are passing all the four tokens which we received from Twitter. At last in source configuration we are passing the keywords on which we are going to fetch the tweets.
In the Sink configuration we are going to configure HDFS properties. We will set HDFS path, write format, file type, batch size etc. At last we are going to set memory channel as shown in the below image.
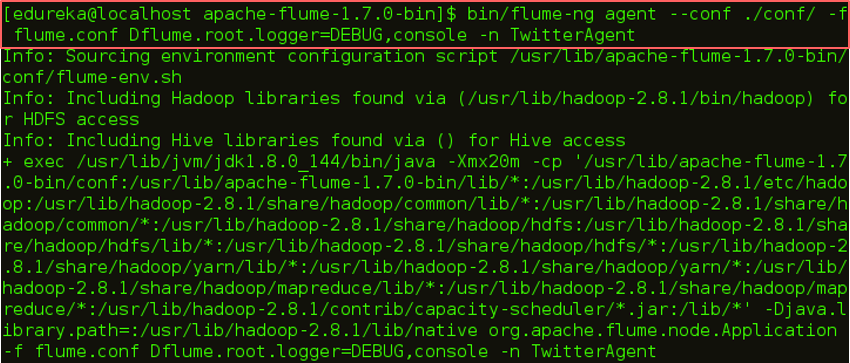
Now we are all set for execution. Let us go ahead and execute this command:
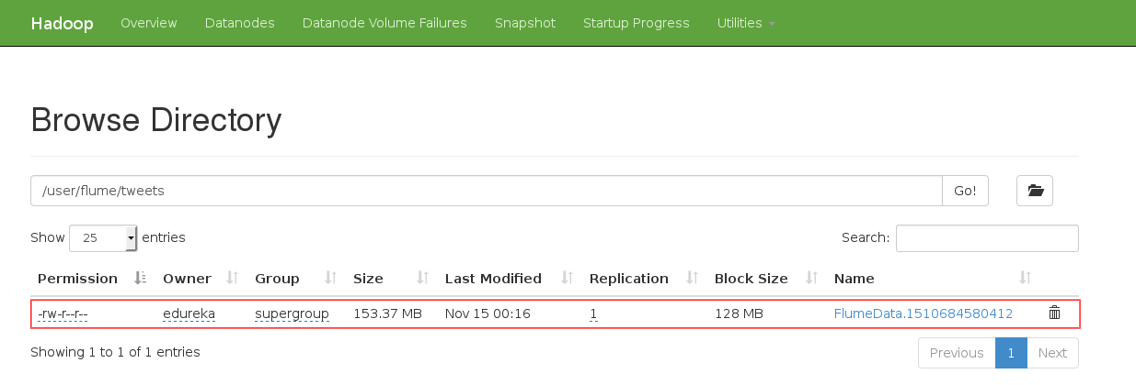
After executing this command for a while, and then you can exit the terminal using CTRL+C. Then you can go ahead in your Hadoop directory and check the mentioned path, whether the file is created or not.
Download the file and open it. You will get something as shown in the below image.
I hope this blog is informative and added value to you. If you are interested to learn more, you can go through this Hadoop Tutorial Series which tells you about Big Data and how Hadoop is solving challenges related to Big Data.
Redefine your data analytics workflow and unleash the true potential of big data with Pyspark Training.
Now that you have understood Apache Flume, check out the Hadoop trainingby Edureka, a trusted online learning company with a network of more than 250,000 satisfied learners spread across the globe. The Edureka Big Data Hadoop Certification Training course helps learners become expert in HDFS, Yarn, MapReduce, Pig, Hive, HBase, Oozie, Flume and Sqoop using real-time use cases on Retail, Social Media, Aviation, Tourism, Finance domain.
Got a question for us? Please mention it in the comments section and we will get back to you.
Hi,i have done my configuration for twitter data in same way but I am not getting the tweet data based on keywords passed.Even in your screenshot also it is not relevant data to keywords that you have passed in configuration file.Can you please explain how we can get data based on some keywords?Also please tell me if we can pass keywords dynamically instead of hard writing in configuration file?






 There is a Flume agent which ingests the streaming data from various data sources to HDFS. From the diagram, you can easily understand that the web server indicates the data source. Twitter is among one of the famous sources for streaming data.
There is a Flume agent which ingests the streaming data from various data sources to HDFS. From the diagram, you can easily understand that the web server indicates the data source. Twitter is among one of the famous sources for streaming data.







































Hi,i have done my configuration for twitter data in same way but I am not getting the tweet data based on keywords passed.Even in your screenshot also it is not relevant data to keywords that you have passed in configuration file.Can you please explain how we can get data based on some keywords?Also please tell me if we can pass keywords dynamically instead of hard writing in configuration file?
hi diva, you need to design agent.config file, i got this information from this website apache flume, u can also refer.