Apache Flink is an open source platform for distributed stream and batch data processing. It can run on Windows, Mac OS and Linux OS. In this blog post, let’s discuss how to set up Flink cluster locally. It is similar to Spark in many ways – it has APIs for Graph and Machine learning processing like Apache Spark – but Apache Flink and Apache Spark are not exactly the same.
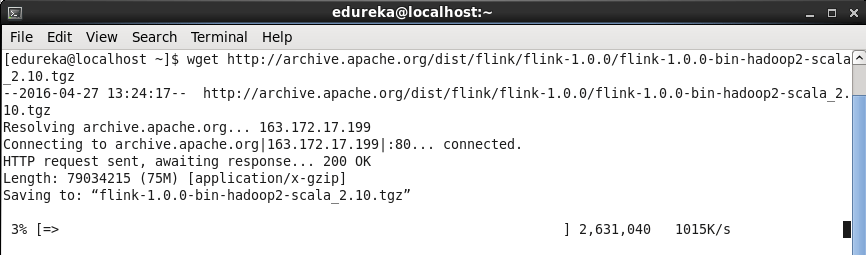
To set up Flink cluster, you must have java 7.x or higher installed on your system. Since I have Hadoop-2.2.0 installed at my end on CentOS ( Linux ), I have downloaded Flink package which is compatible with Hadoop 2.x. Run below command to download Flink package.
Command: wget http://archive.apache.org/dist/flink/flink-1.0.0/flink-1.0.0-bin-hadoop2-scala_2.10.tgz
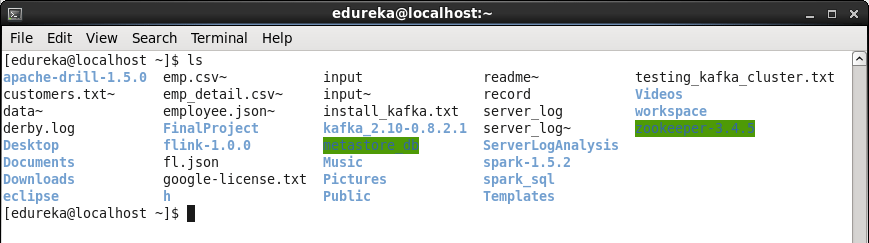
Untar the file to get the flink directory.
Command: tar -xvf Downloads/flink-1.0.0-bin-hadoop2-scala_2.10.tgz
Command: ls
Add Flink environment variables in .bashrc file.
Command: sudo gedit .bashrc

You need to run the below command so that the changes in .bashrc file are activated
Command: source .bashrc
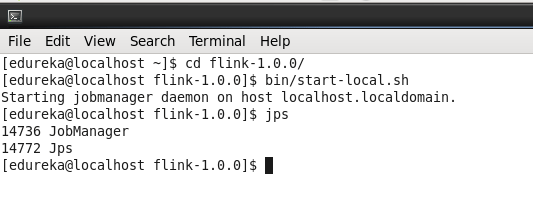
Now go to flink directory and start the cluster locally.
Command: cd flink-1.0.0
Command: bin/start-local.sh
Once you have started the cluster, you will be able to see a new daemon JobManager running.
Command: jps
Open the browser and go to http://localhost:8081 to see Apache Flink web UI.
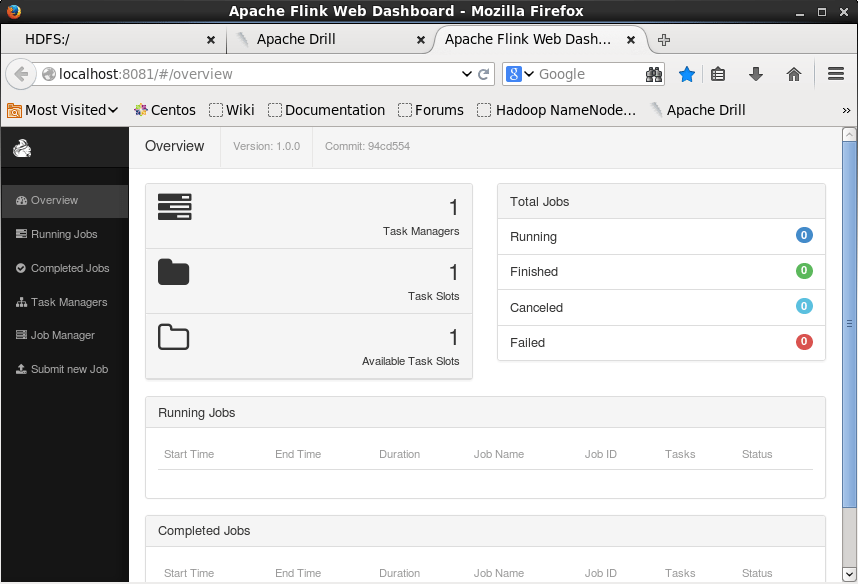
Let us run a simple wordcount example using Apache Flink.
Before running the example install netcat on your system ( sudo yum install nc ).
Now in a new terminal run the below command.
Command: nc -lk 9000

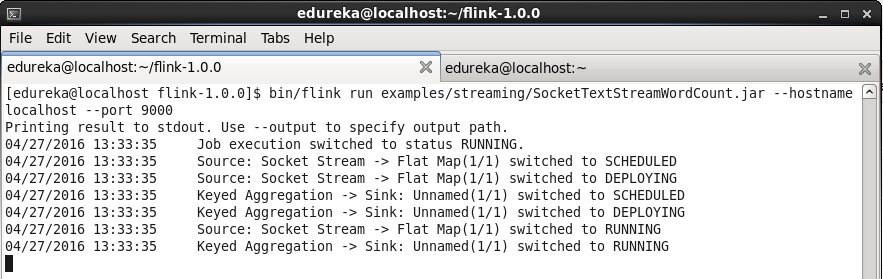
Run the below given command in the flink terminal. This command runs a program which takes the streamed data as input and performs wordcount operation on that streamed data.
Command: bin/flink run examples/streaming/SocketTextStreamWordCount.jar –hostname localhost –port 9000
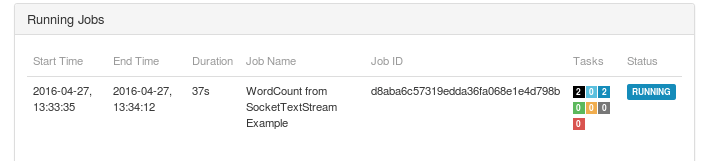
In the web ui, you will be able to see a job in running state.
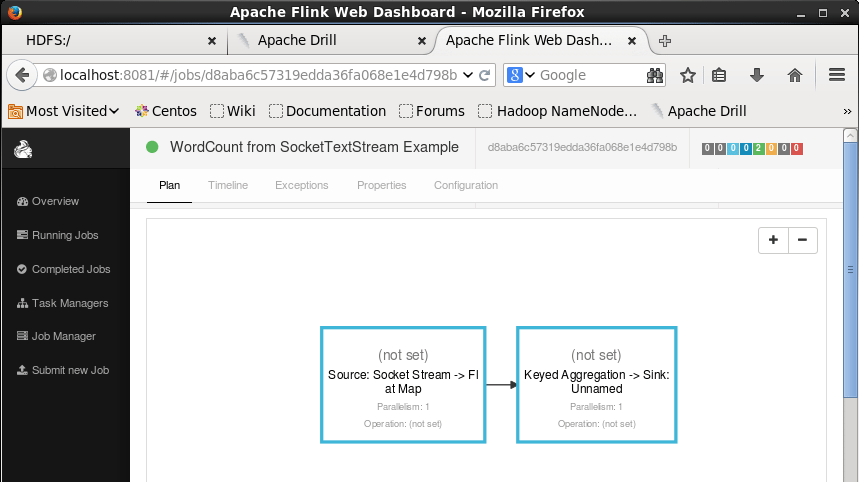
Run below command in a new terminal, this will print the data streamed and processed.
Command: tail -f log/flink-*-jobmanager-*.out

Now go to the terminal where you started netcat and type something.
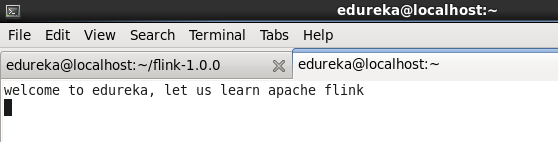
The moment you press enter button on your keyword after you typed some data on netcat terminal, wordcount operation will be applied on that data and the output will be printed here ( flink’s jobmanager log ) within milliseconds!
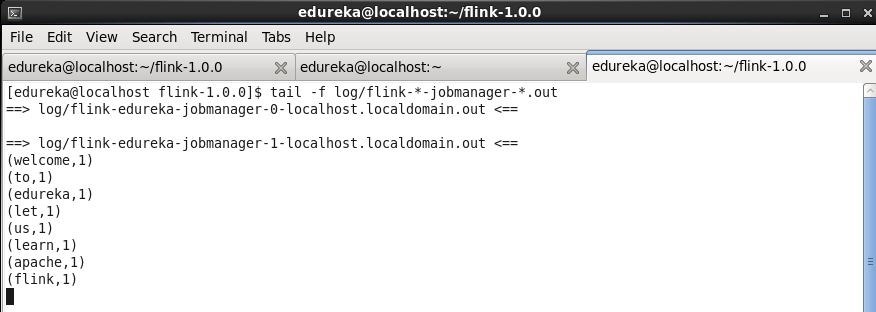
Within a very very short span of time, data will be streamed, processed and printed.
There is much more to learn about Apache Flink. We will touch upon other Flink topics in our upcoming blog.
Got a question for us? Mention them in the comment section and we will get back to you.
Related Posts:
Get Started with Big Data and Hadoop
Apache Falcon: New Data Management Platform for the Hadoop Ecosystem