





Apache Falcon is a framework for managing data life cycle in Hadoop clusters. It establishes relationship between various data and processing elements on a Hadoop environment, and also provides feed management services such as feed retention, replications across clusters, archival etc.
Let us first discuss how to setup Apache Falcon. Run the below given command to download git repository of Falcon:
Command: git clone https://git-wip-us.apache.org/repos/asf/falcon.git falcon
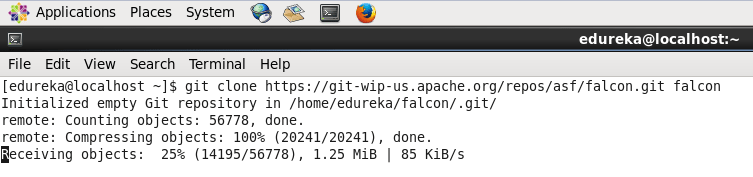
To run falcon, you need to build it first.
Command: cd falcon
Command: export MAVEN_OPTS=”-Xmx1024m -XX:MaxPermSize=256m -noverify” && mvn clean install -DskipTests
Command: mvn clean assembly:assembly -DskipTests -DskipITs
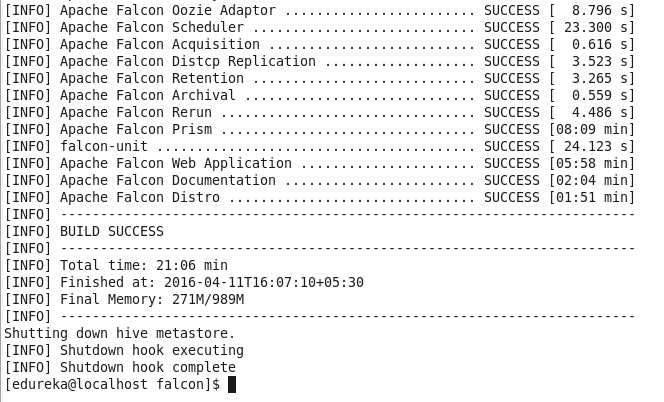
Once you have built falcon, you will find a falcon package inside /falcon/distro/target/ directory.

The commands for building falcon looks very easy, but you will face a lot issues before you see the Build Success message. I faced a lot of issues while building it for Hadoop-2.2.0
So to skip the pain of building Falcon , I am giving you a successfully built falcon package, which you can download using the below link.
https://edureka.wistia.com/medias/xw5cfzqmho/download?media_file_id=124642564
Unzip the file to get falcon-0.10 directory.
Command: unzip falcon-0.10-SNAPSHOT.zip
Set flacon environment variables in .bashrc file.
Command: sudo gedit .bashrc
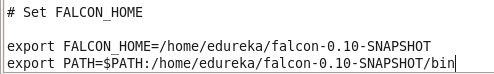
Command: source .bashrc
You can go to falcon directory and see the files and directories inside it.
Command: cd falcon-0.10-SNAPSHOT/
Command: ls

You can find falcon scripts inside bin directory.
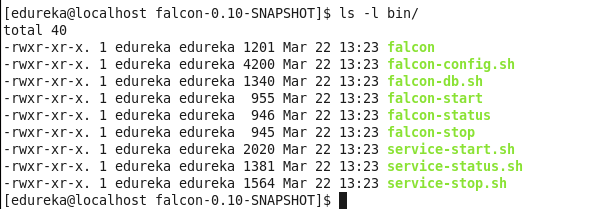
Run below command to start Falcon.
Command: ./bin/falcon-start

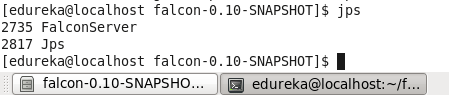
You’ll see a new daemon FalconServer running now.
Command: jps
Command: ./bin/falcon admin -version

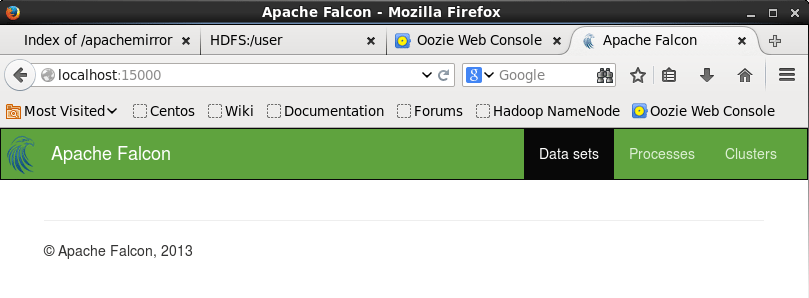
Open your browser, and go to localhost:15000. You can see Falcon web ui.
Got a question for us? Mention them in the comment section and we will get back to you.
Related Posts:








































Thanks for the information. I am working on data management platform, which is really helpful for me.