 Hadoop Framework comprises of two main components, namely,
Hadoop Framework comprises of two main components, namely,
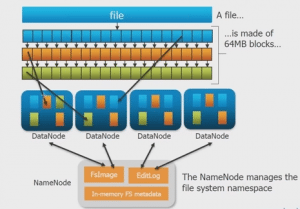
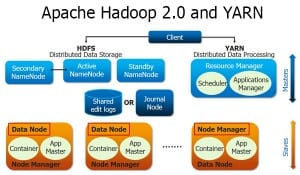
- Hadoop Distributed File System (HDFS) for Data Storage and
- MapReduce for Data Processing.
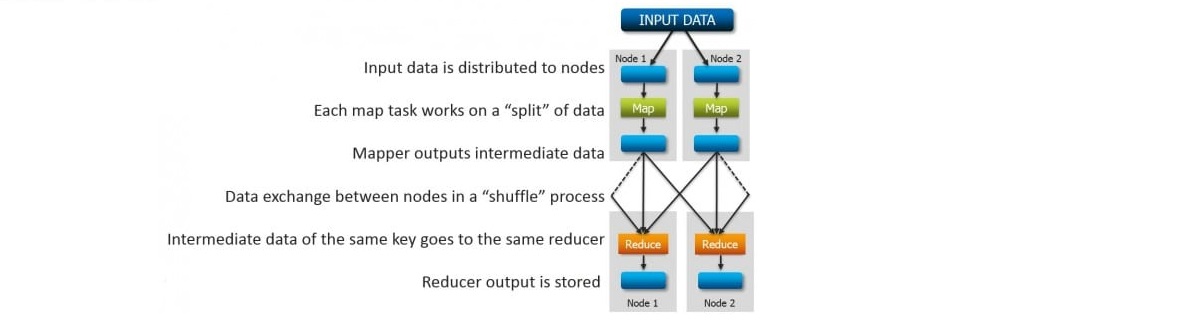
In this post we will discuss the Anatomy of a MapReduce Job in Apache Hadoop. A typical Hadoop MapReduce job is divided into a set of Map and Reduce tasks that execute on a Hadoop cluster. The execution flow occurs as follows:
- Input data is split into small subsets of data.
- Map tasks work on these data splits.
- The intermediate input data from Map tasks is then submitted to Reduce task after an intermediate process called ‘shuffle’.
- The Reduce task(s) works on this intermediate data to generate the result of a MapReduce Job.
Let’s concentrate on Map and Reduce phase in this blog. (We will review the input data splitting and shuffle process in detail in our future blogs). Learn more about Big Data and its applications from the Data Engineering Training.
Let us look at a simple MapReduce job execution using one of the sample examples, “teragen” in CDH3. This program is used for generating large amount of data for bench marking the clusters available in Cloudera CDH3 Quick Demo VM.

The data size to be generated and the output file location are specified as an argument to the ‘teragen’ program. The ‘teragen’ class/program runs a MapReduce job to generate the data. We will analyze this MapReduce job execution.

This output file stores the output data on HDFS. The following figure shows the execution process and all the intermediate phases of a MapReduce Job execution:

Let’s review the execution log to understand the Job execution flow:
Learn more about Big Data and its applications from the Azure Data Engineering Course in Canada.

The ‘teragen’ program launches two map tasks and 3 reduce tasks to generate the required data.
- The Map tasks generate the records.
- The generated records go to a combiner task as input. The ‘combiner’ is an intermediate process.
(We will discuss combiner in detail in our future blog. As of now consider it as an intermediate process before reduce task). - The combiner output records go as an input into a Reduce task.
- Finally, the reducer task aggregates the data and generates the output records.
Note that the Reduce task starts after the map task completion and the number of records continue to reduce at each level. From this Big Data Course ,you will get a better understanding about HDFS and MapReduce.
Got a question for us? Mention them in the comments section and we will get back to you.
Related Posts:
Get started with Big Data and Hadoop