The life of a Hadoop Administrator revolves around creating, managing and monitoring the Hadoop Cluster. However, cluster administration is not a consistent activity practiced through and through by administrators from around the globe. The main variable in this case is the “Distribution of Hadoop” or in simple words a ‘cluster’ based where you choose the cluster monitoring tools. The different distributions of Hadoop are Cloudera, Hortonworks, Apache and MapR. Apache distribution is of course the Open source Hadoop distribution. The best way to become a Hadoop Administrator is from the Hadoop Admin Training.

As an administrator, if I want to setup a Hadoop cluster on the Hortonworks/Cloudera distribution, my job will be simple because all the configurations files will be present on startup. However, in the case of the open source Apache distribution of Hadoop, we have to manually setup all the configurations such as Core-Site, HDFS-Site, YARN-Site and MapRed-Site.
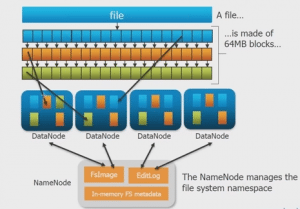
Once we have created the cluster, we have to ensure that the Cluster is active and available at all times. For this, all the nodes in the cluster have to be setup. They are NameNode, DataNode, Active & Standby NameNode, Resource Manager and the Node Manager.
NameNode is the Heart of the cluster. It consists of Metadata, which helps the cluster to recognize the data and coordinate all the activities. Since a lot depends on the NameNode, we have to ensure 100% reliability and for this, we have something called the Standby NameNode which acts as the backup for the Active NameNode. NameNode stores the Metadata, while the actual data is stored in the DataNode in the form of Blocks. The Resource Manager takes care of the cluster’s CPU and memory resources at all times for all the Jobs while the Application Master manages the actual jobs.
If all the above services are running and are active at all times, your Hadoop Cluster is ready for use.
When setting up the Hadoop Cluster, the administrator will also need to decide the cluster size based on the amount of data that is to be stored in the HDFS. Since the replication factor of HDFS is 3, 15 TB of free space is required to store 5 TB of data in the Hadoop cluster. The replication factor is set at 3 in order to increase the Redundancy and Reliability. Cluster growth based on storage capacity is a very effective technique that is implemented in the clusters. We can add new systems to the existing cluster and thereby increase the storage space any number of times.
Another important activity we have to perform as a Hadoop Administrator is that we have to monitor the cluster on a regular basis. We monitor the Cluster to ensure that it is up and running at all times and to keep track of the performance. You can learn more about clusters from the Hadoop Admin Course in Hyderabad.
Clusters can be monitored using various cluster monitoring tools. We choose the appropriate cluster monitoring tools based on the distribution of Hadoop that you are using.
The monitoring tools for the appropriate distribution of Hadoop are:
Open Source Hadoop/Apache Hadoop à Nagios/ Ganglia/Ambari/ Shell scripting/Python Scripting
Cloudera Hadoop à Cloudera Manager + Open Source Hadoop tools
Hortonworks à Apache Ambari + Open Source Hadoop tools

Ganglia is used for monitoring Compute Grids i.e a bunch of servers working on the same task to achieve a common goal. It is like a cluster of clusters. Ganglia is also used to monitor the various statistics of the cluster. Nagios is used for monitoring the different servers, the different services running in the servers, switches, and network bandwidth via SNMP etc.
Do remember that Nagios and Ganglia are open source which is why both are slightly difficult to manage when compared to Ambari and Cloudera Manager. The former is the monitoring tool used by Hortonworks distribution while Cloudera uses the latter. Apache Ambari and Cloudera Manager are more popular tools because they come along with the Hadoop Distributions providing you with around 10,000 statistics to monitor. But the drawback is that they are not open source.
Got a question for us? Please mention it in the comments section and we will get back to you.
Related Posts:
Get Started with Hadoop Administration