





This is a recording of a Techgig Webinar held on 4th September’14. It covers the following topics in detail-
- What is Big Data
- Traditional Warehouse Vs Hadoop
- Why Should you Learn Hadoop and Related Technologies
- Jobs and Trends in Big Data
- Hadoop Architecture and Ecosystem
Here’s an excerpt of the video:
Definition of Big Data
Big Data doesn’t necessarily relate to Terabytes and Petabytes of data i.e the size of the data. The term ‘Big Data’ is used to represent a collection of data sets that are large and complex and is difficult to process using available database management tools or traditional data processing applications.
Big Data comprises both structured as well as unstructured date. The amount of data streaming in too huge and majorly comprises unstructured data. In 2012, there were more than 2,500 Exabytes of data streaming from the Internet alone and the digital universe have grown by 62% since then. The amount of data has grown from 800k Petabytes since last year to a whopping 1.2 Zettabytes, this year.
Real World Applications of Big Data:
eBay – Web and Retailing:
- Recommendation Engines
- Ad Targeting
- Search Quality
- Abuse and Click Fraud Detection
China Mobile – Telecommunications:
- Customer Churn Prevention
- Network Performance Optimization
- Calling Data Record (CDR) Analysis
- Analyzing Network to Predict Failure
JP Morgan Chase – Banks and Financial Services:
- Modeling True Risk
- Threat Analysis
- Fraud Detection
- Trade Surveillance
- Credit Scoring and Analysis
Sears – Retail:
- Point of Sales Transaction Analysis
- Customer Churn Analysis
- Sentiment Analysis
Sears – Case Study:
Initially, Sears was using traditional systems like Oracle Exadata, Teradata, SAS, etc. to store and process customer activity and sales data. With more data coming in, Sears wanted to analyse the customer behaviour and know more about their buying patterns and come up with recommended products based on the data. The existing system at that time could not meet this expectation due to limitations at ‘ETL’ point and storage grid in the data analysis structure. Almost 90% of data streaming in was being archived and after certain point this data was simply too huge to handle in the storage grid. As a result, only limited amount of data was available for analyzing. At any point of time, only 10% of the data would be available to generate reports and gain meaningful insights from this data.
Sears overcame this setback by implementing Hadoop. With Hadoop, 100% of its data is available for processing. Sears completely removed the ETL and storage grid from the data analysis structure. With the implementation of Hadoop, the entire data is now available for analysis.
Sears is now able to gain meaningful insights and use it to their advantage, gather key early indicators that are of significant business value and are able to perform precise analysis on the data.
Reasons to Move to Hadoop:
Hadoop has become a popular and successful platform for handling Big Data. Let’s look at some of the features that has earned this status:
- Hadoop allows distributed processing of large data sets across clusters of computer using simple programming model.
- Hadoop has become the defacto standard for storing, processing and analyzing hundreds of Terabytes and Petabytes of data.
- Hadoop is cheaper to use in comparision to other traditional proprietary technologies like Oracle, IBM etc. It can run on low cost commodity hardware.
- Hadoop can handle all types of data from disparate systems such as server logs, emails, sensor data, pictures, videos, etc.
Growth and Job Opportunities with Hadoop:

Alice Hill, Managing Director of Dice.com, states that the data professionals with Hadoop skill are best paid in the IT industry. As per Dice’s salary survey in 2013, Big Data has disproportionate impact on salaries. Salaries for professionals skilled in Hadoop and NoSQL are more than $100,000
Huge Demand for Hadoop Professionals:
According to Gartner, 4.4 million IT jobs will be created globally to support Big Data by 2015. A huge demand for Hadoop professionals is already there, but this demand is not met due to insufficient professionals with Hadoop skills.

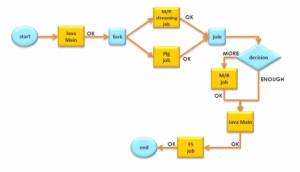
Hadoop Ecosystem:

The Hadoop ecosystem consists of various components like Sqoop and Flume, which are some of the tools used along with Hadoop. It also includes HDFS, which plays the role of an Administrator and Hive, Pig and Mahout, which is taken care by the developers. Here, HBase is used to store MapReduce data.
After glancing through Hadoop and its components, you have enough and more reasons to understand in detail, why the yellow toy so important.
Got a question for us? Mention them in the comments section and we will get back to you.
Check out our related posts on this topic:




































Hi Anil here this side. I am currently working as Software Build Engineer at automotive sector for past 5 years. I got mixed exposure to different languages such as Java,groovy, Configuration management and Continuos Integration and Some other age old stuffs. I want to switch my career to BIG Data Hadoop developer. I went through some of the blogs here. I have a query here how can i switch my career to Hadoop without having any experience in Hadoop. As if i look into many job sites they are asking for work experience in Hadoop. Just getting trained in Hadoop will be able to switch my career or not. And how is the Market trend in Hadoop now. What is the prospect of Hadoop for next 5 years. After getting these info i can think of getting trained in Hadoop
I am a Manual tester with 5+yrs of exp . I want to learn and explore hadoop .Being a tester, wanted to know what opportunities will I get in hadoop, what will be my job role? Will it be beneficial for me to learn hadoop?
Hi Rahul,
Thank you for reaching out to us.
The current job scenario has witnessed several experienced professionals switching to Big Data/Hadoop technologies in order to advance in their careers.
You can master Hadoop irrespective of your IT background. While basic knowledge of Core Java and SQL might help, it is not a pre-requisite for learning Hadoop.
You can check out this blog for more information: https://www.edureka.co/blog/do-you-need-java-to-learn-hadoop
In case you do wish to brush up on your Java knowledge, Edureka also provides a self-paced course called ‘Java essentials for Hadoop’.
You can go through this link for more information about the course: https://www.edureka.co/big-data-hadoop-training-certification
We would recommend that you get in touch with us for further clarification by contacting our sales team on +91-8880862004 (India) or 1800 275 9730 (US toll free). You can mail us on sales@edureka.co.