
Data Science with Python Certification Course
- 132k Enrolled Learners
- Weekend
- Live Class
(49300)





 Copy Link!
Copy Link!Hadoop is a disruptive Java-based programming framework that supports the processing of large data sets in a distributed computing environment, while R is a programming language and software environment for statistical computing and graphics. The R language is widely used among statisticians and data miners for developing statistical software and performing data analysis. In the areas of interactive data analysis, general purpose statistics and predictive modelling, R has gained massive popularity due to its classification, clustering and ranking capabilities.
![]()
Hadoop and R complement each other quite well in terms of visualization and analytics of big data.
There are four different ways of using Hadoop and R together:
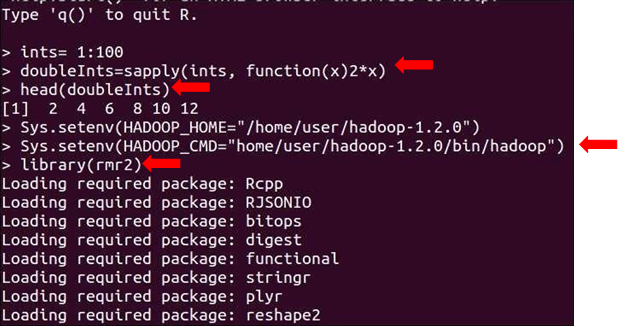
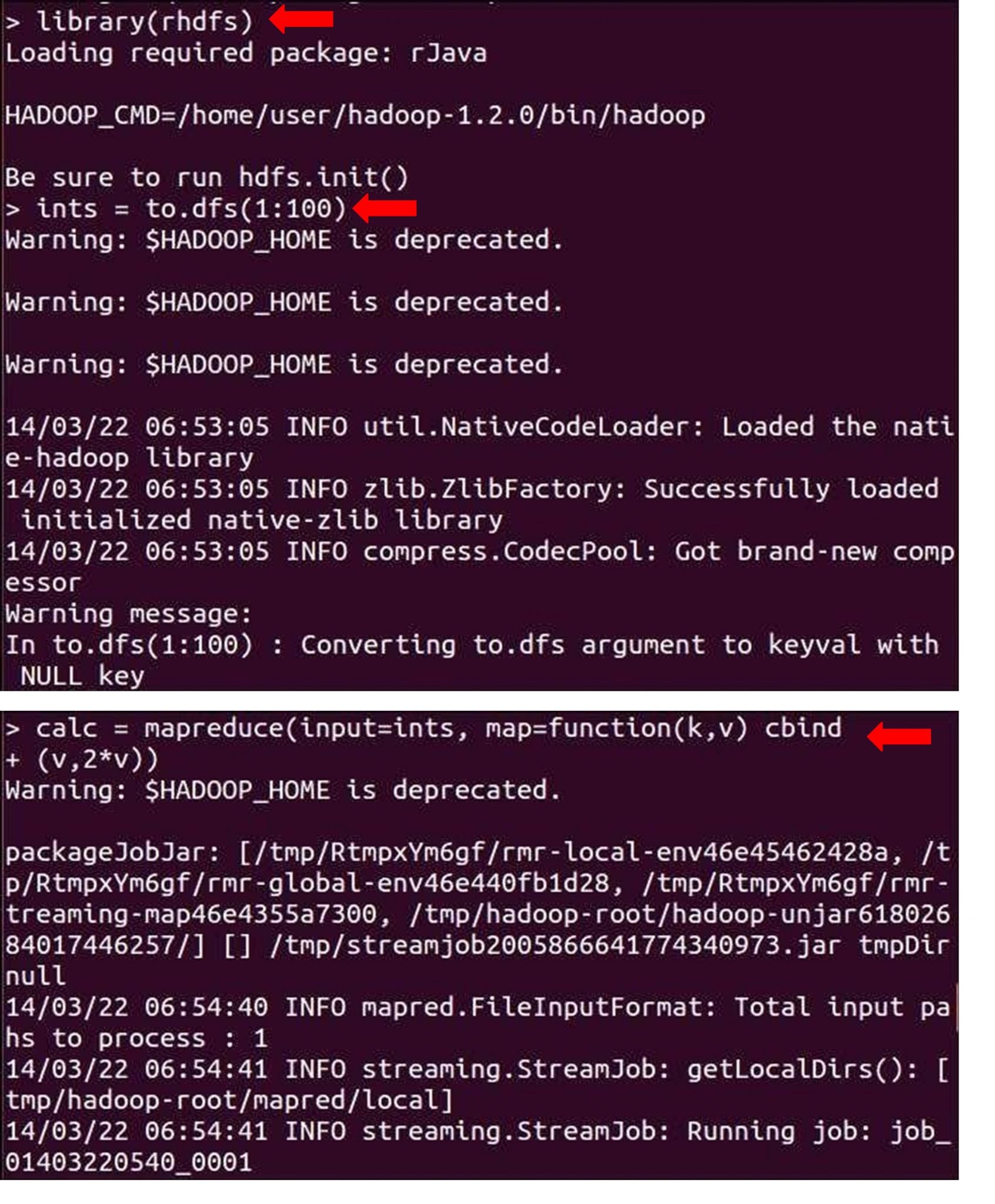
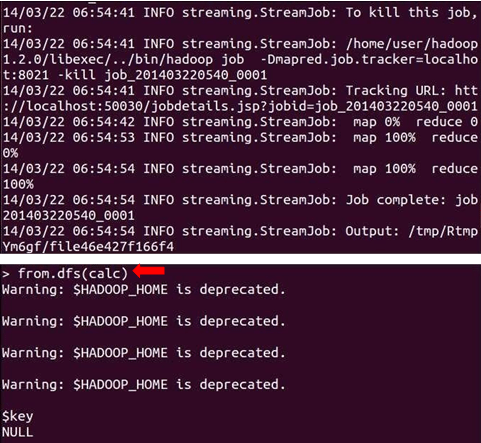
1. RHadoop
RHadoop is a collection of three R packages: rmr, rhdfs and rhbase. rmr package provides Hadoop MapReduce functionality in R, rhdfs provides HDFS file management in R and rhbase provides HBase database management from within R. Each of these primary packages can be used to analyze and manage Hadoop framework data better.
2. ORCH
ORCH stands for Oracle R Connector for Hadoop. It is a collection of R packages that provide the relevant interfaces to work with Hive tables, the Apache Hadoop compute infrastructure, the local R environment, and Oracle database tables. Additionally, ORCH also provides predictive analytic techniques that can be applied to data in HDFS files.
3. RHIPE
RHIPE is a R package which provides an API to use Hadoop. RHIPE stands for R and Hadoop Integrated Programming Environment, and is essentially RHadoop with a different API.
4. Hadoop streaming
Hadoop Streaming is a utility which allows users to create and run jobs with any executables as the mapper and/or the reducer. Using the streaming system, one can develop working Hadoop jobs with just enough knowledge of Java to write two shell scripts that work in tandem.
The combination of R and Hadoop is emerging as a must-have toolkit for people working with statistics and large data sets. However, certain Hadoop enthusiasts have raised a red flag while dealing with extremely large Big Data fragments. They claim that the advantage of R is not its syntax but the exhaustive library of primitives for visualization and statistics. These libraries are fundamentally non-distributed, making data retrieval a time-consuming affair. This is an inherent flaw with R, and if you choose to overlook it, R and Hadoop in tandem can still work wonders.
Now, let’s see a demo:
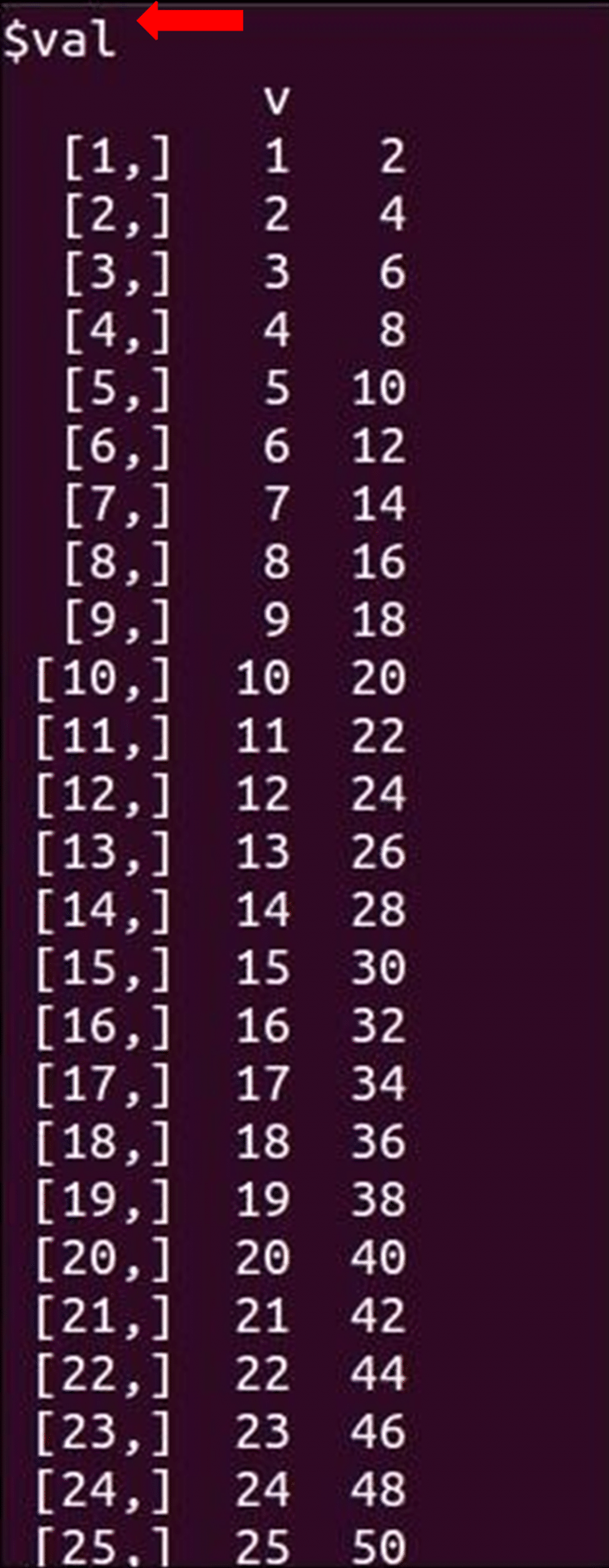
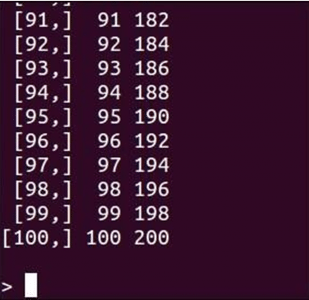
Got a question for us? Please mention them in the comments section and we will get back to you.
Related Posts:
Get Started with Big Data and Hadoop
Get Started with Mastering Data Analytics with R




































 Thank you for registering Join Edureka Meetup community for 100+ Free Webinars each month JOIN MEETUP GROUP
Thank you for registering Join Edureka Meetup community for 100+ Free Webinars each month JOIN MEETUP GROUP
Thanks for this information
Radoop for RapidMiner is a 5th – you can incorporate your SparkR, PySpark, Pig and HiveQL scripts within your predictive analytics workflows. RapidMiner is the only visual predictive analytics solution to combine data preparation on Spark, predictive analytics using Spark’s Machine Learning library (MLlib), and the ability to incorporate custom-built R and Python scripts.